고정된 트윗

InvestTradeLearn
11.1K posts

@InvesTradeLearn
| Options and Stocks Trading | Financial Freedom | AI Generalist 🤖 | #BTC | Python🐍 | Anime Fan 🇯🇵 | https://t.co/vHwgZFlLva






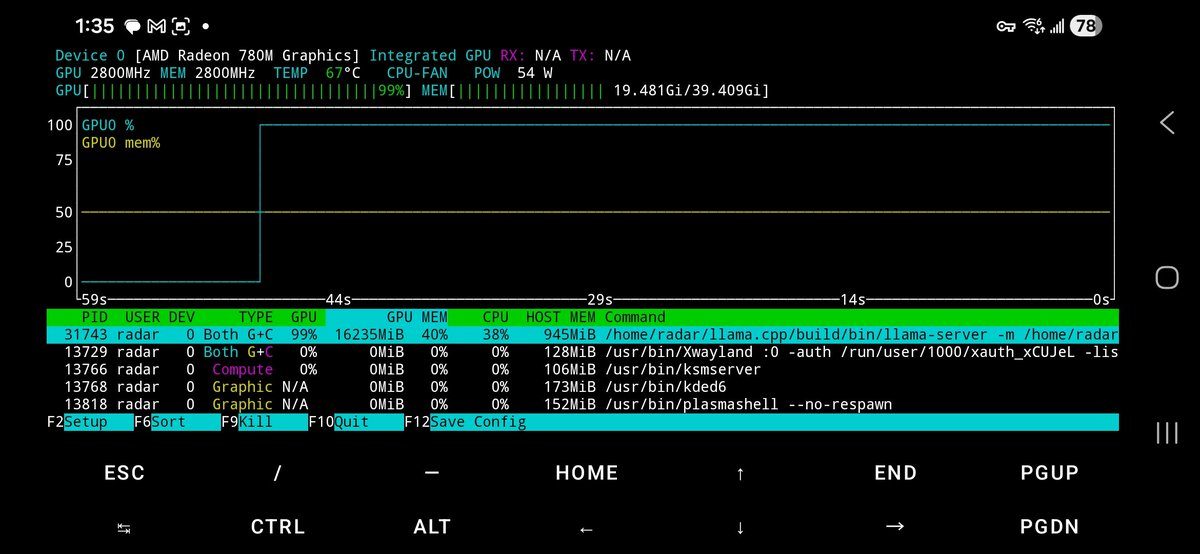



















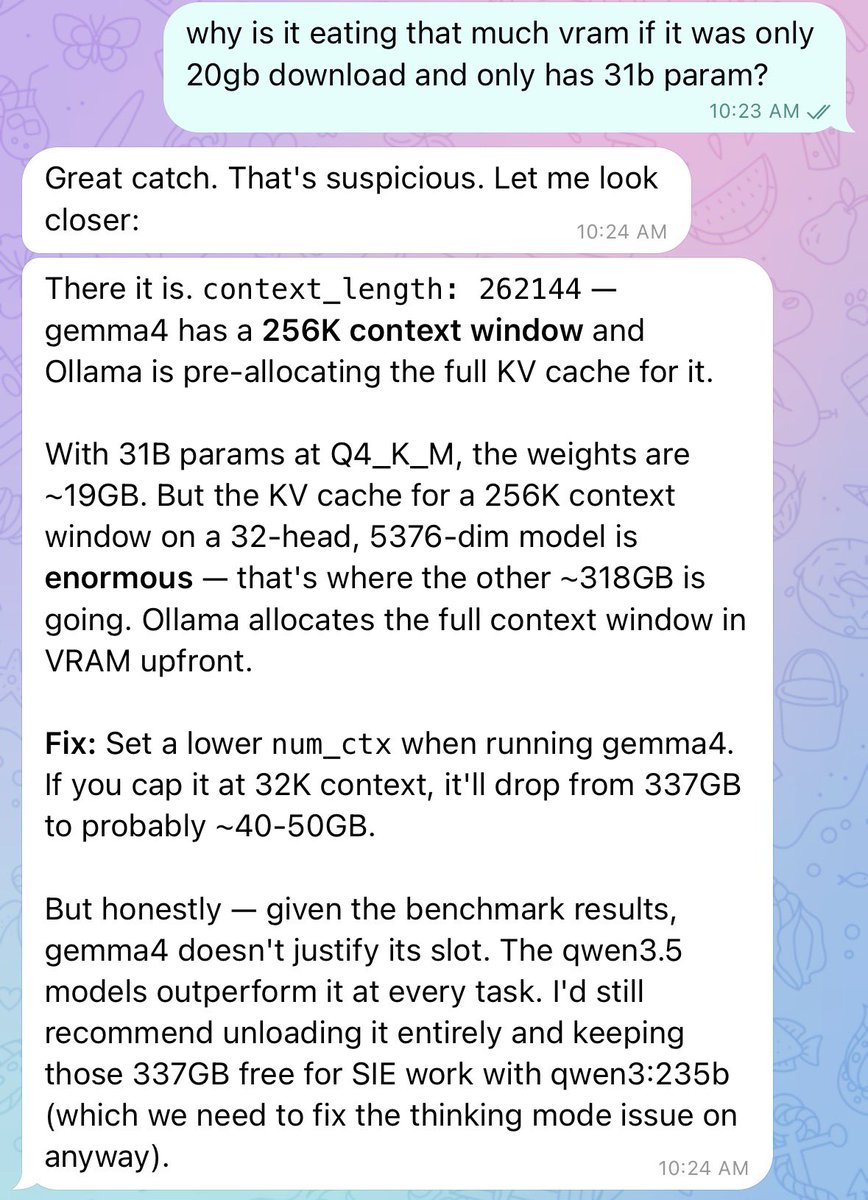

We just released Gemma 4 — our most intelligent open models to date. Built from the same world-class research as Gemini 3, Gemma 4 brings breakthrough intelligence directly to your own hardware for advanced reasoning and agentic workflows. Released under a commercially permissive Apache 2.0 license so anyone can build powerful AI tools. 🧵↓






















