pls seed
704 posts



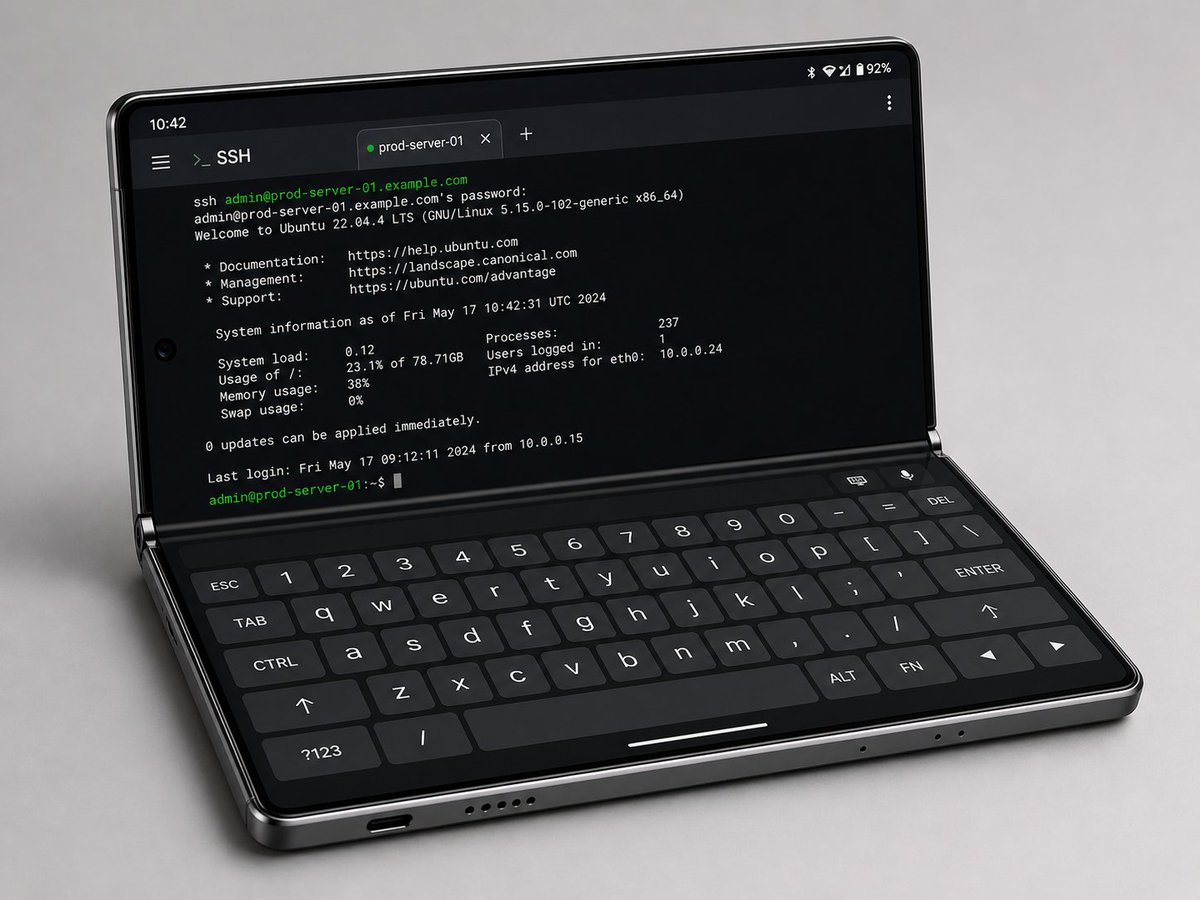
Important features:
1. It has *two* screens, it is not a foldable screen. So there is no problem with folding angle and when closed it will have the two screens facing in the opposite direction.
2. The aspect ratio is different, it is a taller phone, so when open you can type with two hands.
3. The software and keyboard are designed for this use case. It has a native SSH client, a Linux subsystem, ...
English
@neuralease @scaling01 Yeah, just 2 days ago I lost hours where opus 4.7 debuging just shit itself because it did not read enough surce code. People keep forgetting that china models are so cheap and good enough now that you can just spend more tokens and for most of the work it will be enough.
English

@YYYYOOOO77 @scaling01 Hell yeah, I love seeing open-source win like this.
English

chinese models are ~8 months behind and are falling further behind
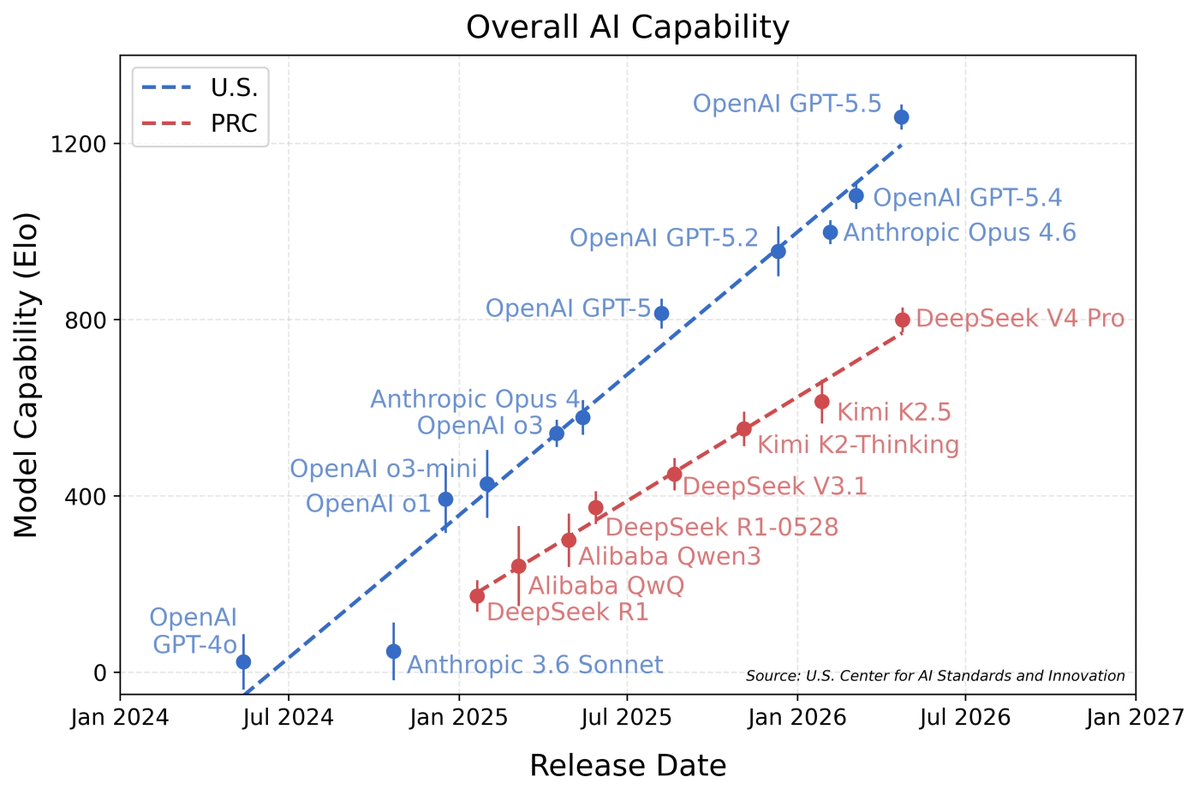
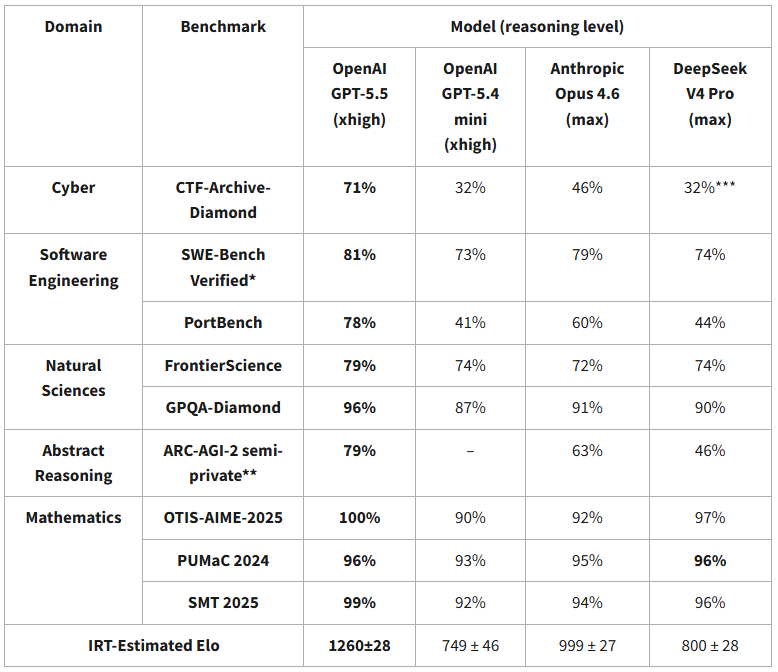
Séb Krier@sebkrier
DeepSeek V4’s capability lags behind leading U.S. models by about 8 months. nist.gov/news-events/ne…
English
@neuralease @scaling01 I use it daily literally daily, have Max 5x and pro lite together with Kimi and glm (now that it's fixed) 8 months my ass.
English
@scaling01 Not on all tasks but:
KimiK2.6, Mimo-V2.5-Pro, Deepseek V4 Pro Max and GLM 5.1 are comparable, even exceeding Sonnet 4.6 in many cases.
I personally use KimiK2.6, it's free without you having to deal with "adaptive thinking" bs.
I don't say this in a mean tone, just mad at anth
English
@DeDgemaskerde @magnushambleton You are, I discovered I can only get a 3.5 beer from the store.
English


Worth keeping in mind for the muricans that think we are a socialist hellhole that will confiscate your money!
tuōmo@7uomoki
The American mind cannot comprehend this 🤯
English
@Presidentlin oh, come on, all the problems that where there before, none of them are gone now, he just changed his opinion. can happen. when there is a lot of money/influence/ego on line i tend to not believe it.
English

What a dark path we have taken.
Lisan hater of OAI is being scolded by their CEO to say mean things.
Popeamodei, why hast thou forsaken us?
Where art thou, O Claude?"

Sam Altman@sama
lisan say more mean things about us you're being too nice
English
@joshmanders @thdxr @yiannis__p everybody literally complained about github doing. and i dont buy the to train open source models. then make the dataset public from day 1. otherwise its just non binding promise.
English

@thdxr @yiannis__p Yes and that's kind of the point. The opposite is you're preying on people who are forgetting to opt out.
Telemetry should be always opt-in, if that becomes an un-meaningful way to lower costs, then find a better way to lower costs.
English
@thdxr @yiannis__p a come on, you know that its not right and you still want to do it. why did you ask then.
English

@yiannis__p people always say this but you can understand that it won't be meaningful enough to actually increase limits
the opt in is paying $10 for $60 of inference
English
@tushant_suneja @leonabboud @nikitabier this, you see this, the crypto bots are gone now you have AI bro bots
English

@leonabboud we ran into similar issues with local hosting and that's why we built Snowy AI, a secure cloud interface that makes it easy to use these tools without the hassle of setup and variable costs
English

Anthropic banning OpenClaw got me to downgrading my $200/m subscription and I'm now back on the Plus plan for OpenAI.
I still think it was a massive fumble loosing AI power users to competition.
No one likes pay as you go usage, people would rather have a fixed plan they're on.
Just like no one would like paying per day to go to the gym. Even though most would likely save money paying per day than they would paying for the month.
If OpenClaw was costing Anthropic a lot, why couldn't they create a new plan called "AI agents" that was slightly more expensive but was a fixed monthly rate.
Most, including myself would have been willing to pay a bit more for a plan specifically designed for AI agents.
English


idk, but dax are you okay?
dax@thdxr
tired of this misinformation so we made a video on the truth behind the anthropic vs opencode drama
English


@SamuelWayne0 @haider1 i find the 3.6 27b with reasoning disabled better, on a 5090 i get like 1.8 ttft and 119tps with 155 context size. this thing rips. thats just vllm with a couple of tweaks and sakamakismile/Qwen3.6-27B-Text-NVFP4-MTP
English


google gemma-4 31b is such an underrated beast model
it's probably the first consumer hardware-sized model that is genuinely usable for simple conversations, not just specific tasks
to put that into context, i prefer it over the free-tier chatgpt model
and you should also
English


Many times a day now, people much smarter than me tell me they are Codex-pilled and that GPT-5.5 was a watershed moment for them.
Engineers keep telling me the Codex App is the first interface that got them to leave the terminal agents behind.
The Codex App is a fundamental shift in the way I work. I can't even imagine what I was doing before using the Codex App, but it definitely wasn't pretty.
Check it out and let us know how to make it even better :)
English
@basedjensen I hate it to, but is the alternative to ship a bunch of cli-s to normies ?
English

I have always hated this. I really do not understand people who pushed mcp
signüll@signulll
mcp was a mistake.
English
@davideciffa huggingface.co/lmsys/SGLang-E…
would be interesting if you produce something with 3-4x on t hat hardware.
English

@YYYYOOOO77 1.5x is a pretty bad speculative decoder, our luce dflash + ddtree has a x3-4 speed up and we are working to make it even better
English
Fast inference needs heterogeneous hardware, a fast small machine with high tflops, high memory bandwidth and a slower bigger one where hosting the main target model. It is way better than a dgx and the cost is similar
Sandro@pupposandro
Testing a Ryzen Strix Halo 128gb + RTX 3090 24gb setup atm. On paper it’s perfect: the 3090 handles speed, the Strix Halo handles memory, you can run everything well including dense or bigger models. The catch is connecting them together cleanly. Still working on that. Cost is ~ $4,000. Still cheaper than the DGX.
English
@davideciffa Okay, I understand it now. But you need a great drafter and even then you can expect 1.5 x maybe., what is the base tps on a strix ? So the outcome doesn't look promising. You have to do a lot of work.
English
@YYYYOOOO77 I mean something else, the main model lives in the slow memory (270gbps), you dont split it. The fast drafters (for speculative decode/speculative prefill) live in the rtx . You can think about it like the poor gpu man version of chips with gigantic SRAM like groq
English
@Yampeleg It's still a huge mess. too much CPU if you have multiple ongoing sessions randomly using the built-in browser use or trying to get to the Chrome MCP directly. The positive is it creates a follow-ups automatically and the auto-compacting can be great, but also can be a huge miss
English


International tourism (number of annual arrivals):
🇫🇷 France: 117.1m
🇵🇱 Poland: 88.5m
🇲🇽 Mexico: 51m
🇺🇸 USA: 45m
🇹🇭 Thailand: 39.9m
🇮🇹 Italy: 38.4m
🇨🇿 Czechia: 37.2m
🇪🇸 Spain: 36.4m
🇨🇦 Canada: 32.4m
🇭🇺 Hungary: 31.6m
🇨🇳 China: 30.4m
🇭🇷 Croatia: 21.6m
🇮🇳 India: 17.9m
🇹🇷 Turkey: 15.9m
🇩🇰 Denmark: 15.6m
🇩🇪 Germany: 12.4m
🇬🇧 UK: 11.1m
🇦🇷 Argentina: 7.4m
🇷🇺 Russia: 6.3m
🇧🇷 Brazil: 6.3m
🇳🇬 Nigeria: 5.2m
🇯🇵 Japan: 4.1m
🇮🇩 Indonesia: 4m
🇸🇪 Sweden: 1.9m
🇦🇺 Australia: 1.8m
🇳🇴 Norway: 1.4m
🇨🇺 Cuba: 1m
🇵🇰 Pakistan: 0.9m
🇫🇮 Finland: 0.9m
🇲🇻 Maldives: 0.55m
🇮🇸 Iceland: 0.5m
🇻🇪 Venezuela: 0.4m
🇲🇩 Moldova: 0.03m
Source: Yearbook of Tourism Statistics, Compendium of Tourism Statistics and data files, UN Tourism. Data from 2020 or latest available. France is 2020, Poland is 2019 for example.
English