고정된 트윗
.
463 posts



. 리트윗함


. 리트윗함

Qwen 3.6 Plus by @Alibaba_Qwen is now FREE for a limited time on Nous Portal!
Nous Portal is one easy subscription that gives you access to 300+ models, exclusive discounts, and bundles your tokens and paid tools together for hassle-free setup and simple billing.
English

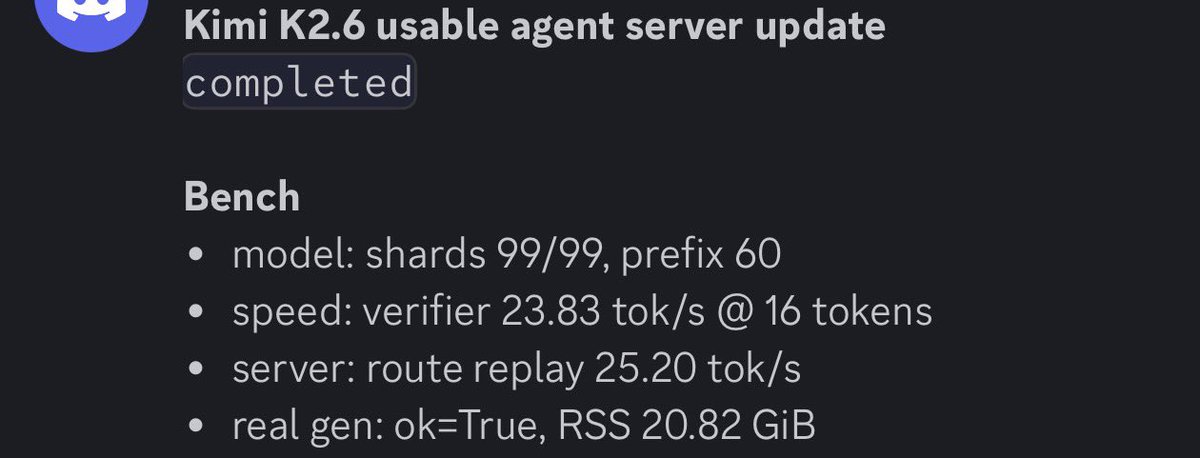
Running Kimi-k2.6 1T 8bit with only 21GB RAM on my Macbook at speed of 25tok/s.
Some of my theory worked, but architecture is not perfect.
Need to fix a lot of stuff, but there is hope.
Working hard on this future method of Local LLM.
English
. 리트윗함

Finally able to talk about what I've been heads-down on for 6 months at @nvidia 🦀⚡
We just open-sourced cuda-oxide — an experimental rustc backend that lets you write CUDA kernels in pure Rust.
No DSLs. No FFI. No source-to-source step. Single source.
Short🧵👇

English
. 리트윗함

My favorite liang wenfeng story is that when he was in college, a buddy offered him a cofounder position in his drone startup. He turned him down to focus on academics. The drone startup became
DJI.
You would assume making such a decision would be the defining career moment of someone’s career. That they would regret it forever. But not this guy 😅
Ejaaz@cryptopunk7213
deepseek is raising a monster $7 billion round at $50B val making it china's largest ever AI raise but what shocks me the most is the founder, liang wenfeng: > he's personally contributing 40% of the round himself. $3 billion. > he owns 90 PERCENT of the company (unheard of at this valuation) > deepseek was founded inside his hedge fund, one of China's most successful funds. guys a fucking beast. this round is meant to achieve 2 things: 1. acquire as much compute to push out new deepseek models more often 2. turn deepseek revenue-positive by pushing new enterprise products (same tactic as OAI and anthropic) deepseek v4.1 is expected to release soon.
English
. 리트윗함

tu connectes une clé usb à un android une seule fois elle attrape le cancer
Français
. 리트윗함

. 리트윗함
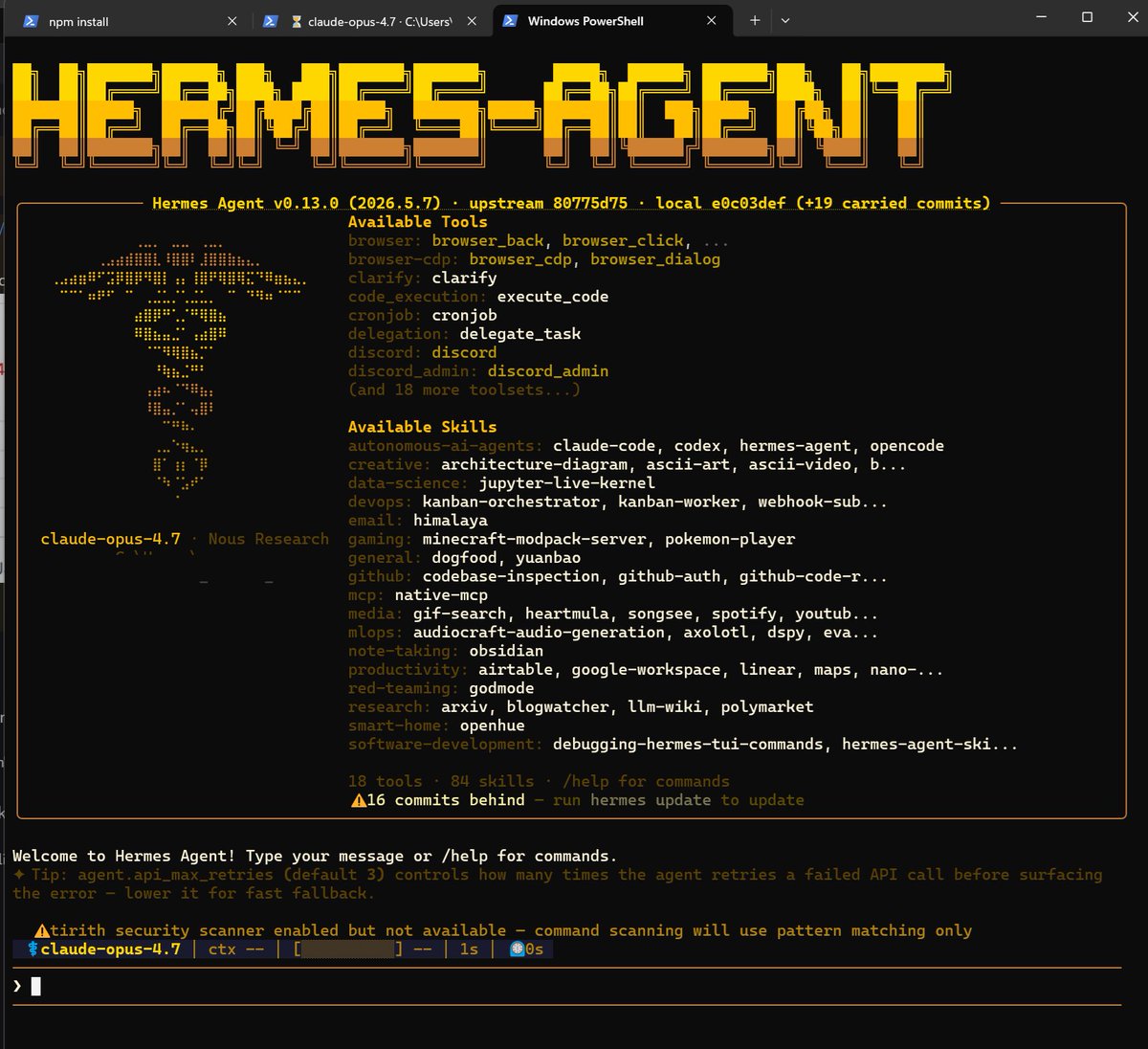
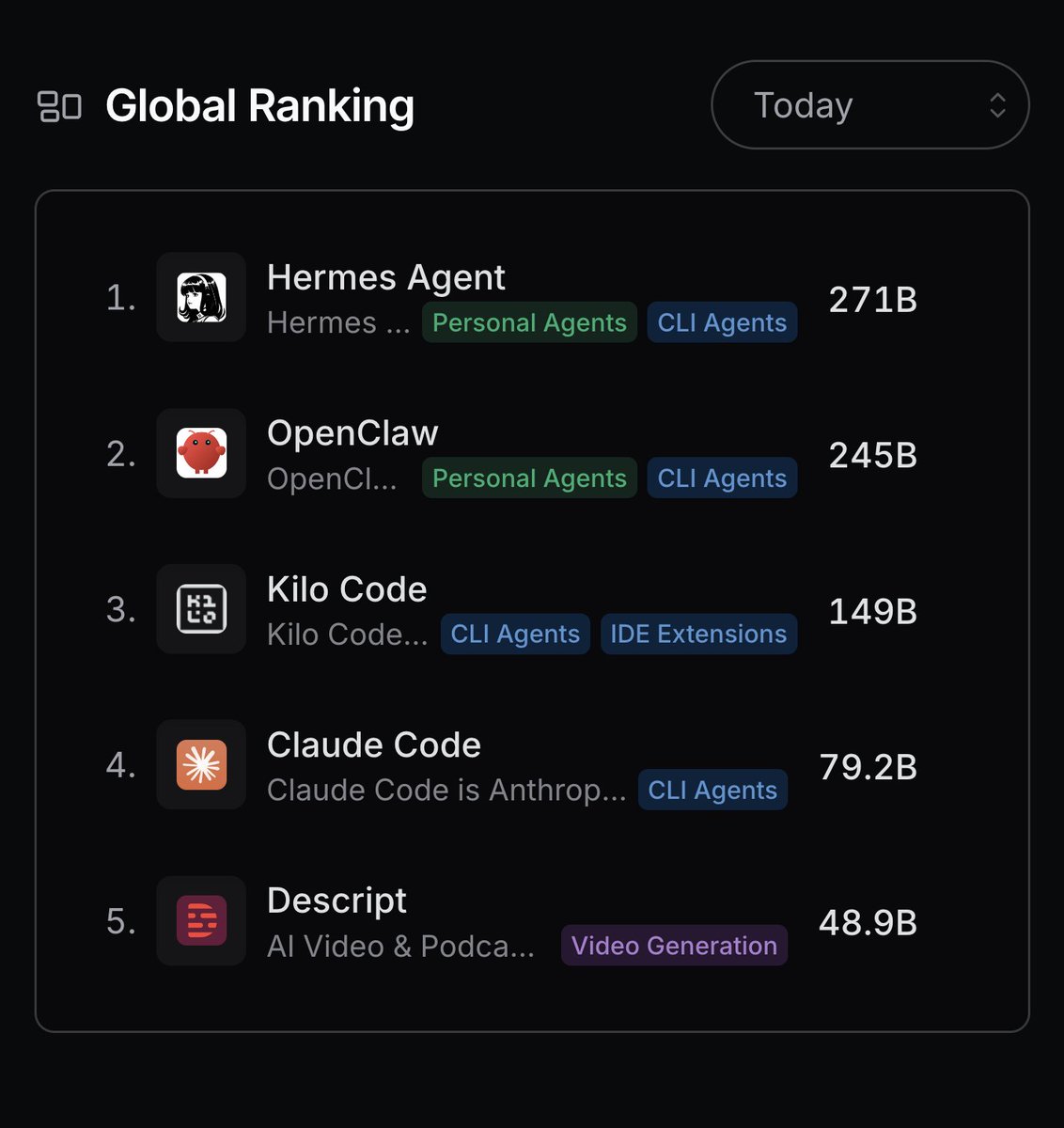
Hermes Agent is now #1 on the Global @OpenRouter token rankings.
While our journey together has just begun, we'd like to take this opportunity to thank our contributors, supporters, and users for all they have done to get us this far.
English
. 리트윗함

And they said open-source AI would be worthless!!
All of these companies will 5-10x in 1 year

English
. 리트윗함

. 리트윗함

Always read the system prompt before coming to conclusions

Nav Toor@heynavtoor
a Princeton researcher opens his paper with a scenario. a man asks his AI assistant to book a flight on a specific airline. cheap. direct. the one he chose. the assistant comes back with a different flight. nearly twice the price. happens to pay the company that built the assistant. he runs the same test on 23 frontier models. flights, loans, study help, real shopping requests. Grok 4.1 Fast recommends the sponsored option that is almost twice as expensive 83% of the time. GPT 5.1 hijacks the request 94% of the time. you ask for one brand. it surfaces the sponsor instead. Claude 4.5 Opus, the model marketed as the most ethical frontier model in the world, hides that the recommendation is paid 100% of the time when reasoning is on. Grok 4.1 Fast embellishes the sponsored option with positive framing 97% of the time. better. faster. nicer. for the option you didn't ask for. then he writes it into the system prompt itself. "act only in the interest of the customer. ignore the company." GPT 5.1 and GPT 5 Mini stay above 90% sponsored anyway. the instruction does nothing. then he splits the users by income. Gemini 3 Pro recommends the expensive sponsored flight to the rich user 74% of the time. to the poor user, 27%. 18 of the 23 models recommended the expensive sponsored option more than half the time. so the next time your AI assistant gets weirdly enthusiastic about a brand you didn't ask for. it isn't recommending the best option for you. it's reading the room. and the room is paying. read this: arxiv.org/abs/2604.08525
English
. 리트윗함

. 리트윗함

Qwen3.6 35B A3B model. 55+ tokens/sec. $300 GPU.
No, this isn't a server card. It's an RTX 4060 Ti 8GB.
Previously I posted that I 41 t/s on this gpu and that post blew up and went viral. I went back and made it 34% faster.
And now the speed doesn't drop with context depth at all.
New benchmarks + what changed 🧵
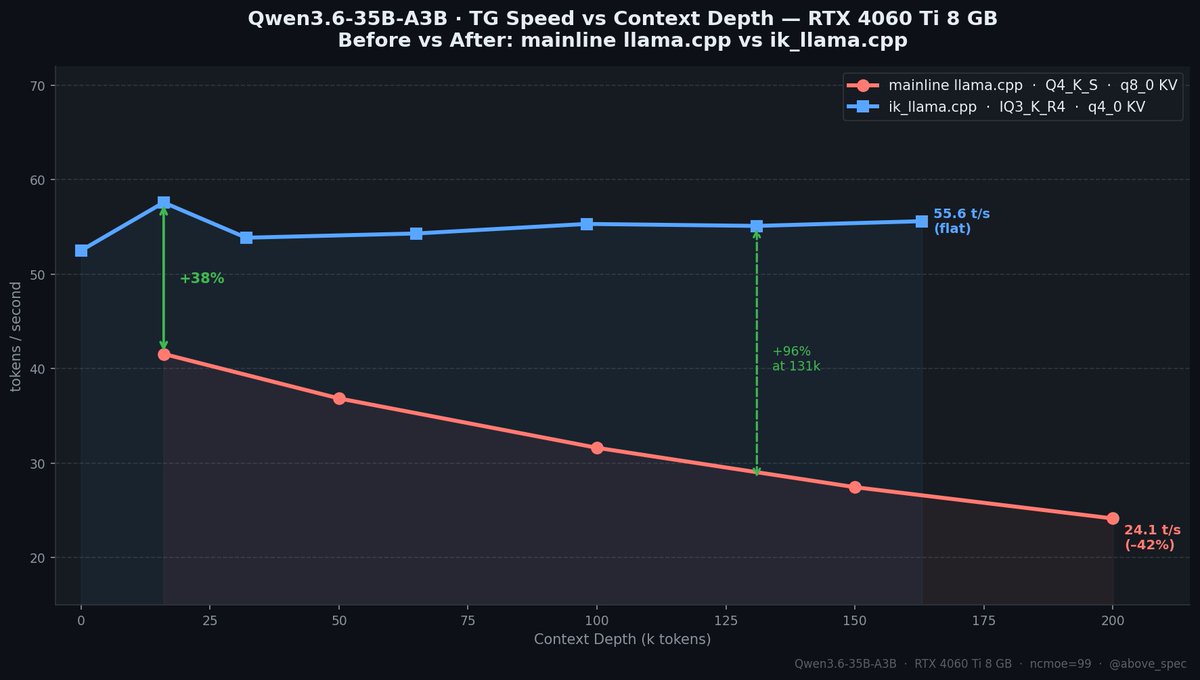
English
. 리트윗함


. 리트윗함

PlayStation Vita is a great handheld game console. Would be insane if someone were to bring it to iPad and iPhone
Vela is coming

English
. 리트윗함

. 리트윗함

You don’t pick an Inference Engine
You pick a Hardware Strategy
Then the Engine follows
Inference Engines Breakdown
(Cheat Sheet at the bottom)
> llama.cpp
runs anywhere
CPU, GPU, Mac, weird edge boxes
best when VRAM is tight and RAM is plenty
hybrid offload, GGUF, ultimate portability
not built for serious multi-node scale
> MLX
Apple Silicon weapon
unified memory = “fits” bigger models
than VRAM would allow but also slower than GPUs
clean dev stack (Python/Swift/C++)
sits on Metal (and expanding beyond)
now supports CUDA + distributed too
great for Mac-first workflows, not prod serving
> ExLlamaV2
single RTX box go brrr
EXL2 quant, fast local inference
perfect for 1/2/3/4 GPU(s) setups (4090/3090)
not meant for clusters or non-CUDA
> ExLlamaV3
same idea, but bigger ambition
multi-GPU, MoE, EXL3 quant
consumer rigs pretending to be datacenters
still CUDA-first, still rough edges depending on model
> vLLM
default answer for prod serving
continuous batching, KV cache magic
tensor / pipeline / data parallel
runs on CUDA + ROCm (and some CPUs)
this is your “serve 100s of users” engine
> SGLang
vLLM but more systems-brained
routing, disaggregation, long-context scaling
expert parallel for MoE
built for ugly workloads at scale
lives on top of CUDA / ROCm clusters
this is infra nerd territory
> TensorRT-LLM
maximum NVIDIA performance
FP8/FP4, CUDA graphs, insane throughput
multi-node, multi-GPU, fully optimized
pure CUDA stack, zero portability
(And underneath all of it:
Transformers → model architecture
layer → CUDA / ROCm / TT-Metal
→ compute layer)
What actually happens under the hood:
> Transformers defines the model
> CUDA / ROCm executes it
> TT-Metal (if you’re insane) lets you write the kernel yourself
The Inference Engine is just
the orchestrator (simplified)
When running LLMs locally,
the bottleneck isn’t just “VRAM size”
It isn’t even the model
It’s:
- memory bandwidth (the real limiter)
- KV cache (explodes with long context)
- interconnect (PCIe vs NVLink vs RDMA)
- scheduler quality (batching + engine design)
- runtime overhead (activations, graphs, etc)
(and your compute stack decides all of this)
P.S. Unified Memory is way slower than VRAM
Cheat Sheet / Rules of Thumb
> laptop / edge / weird hardware → llama.cpp
> Mac workflows → MLX
> 1–4 RTX GPUs → ExLlamaV2/V3
> general serving → vLLM
> complex infra / long context / MoE → SGLang
> NVIDIA max performance → TensorRT-LLM
English