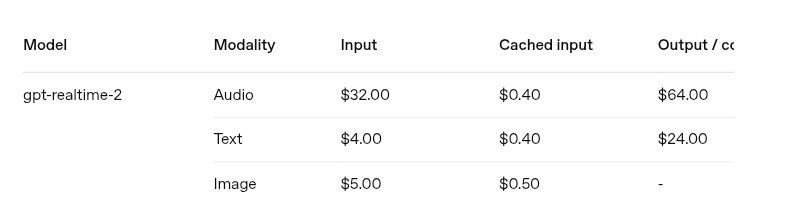
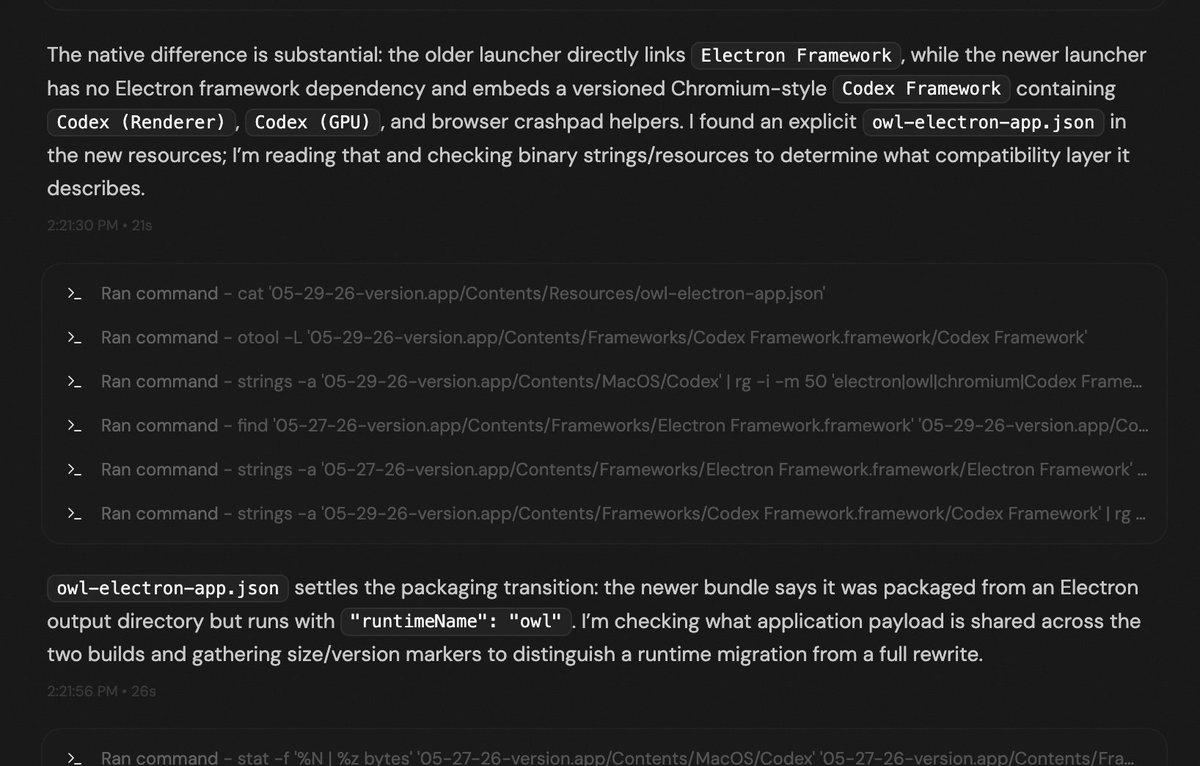
@mike64_t Yeah, it is not elegant and I guess 90% of the time people just don't know how to spend their credits and make useless goals. I can only think of very few cases where the model can be trusted to have a decent result after hours of work unsupervised. There are, but not many
English