
@RayFernando1337 On one end you have Google teasing 10t models and on the other hand qwen is releasing 27b models that are holding up against current frontier models. What are we doing google.
English
Rambone
159 posts


Every AI lab is starving for compute. Except Google. I spoke with Thomas Kurian, Google Cloud's CEO, to understand why Google doesn't just hoard compute before AGI, their relationship with Anthropic, and that viral tweet about Google's engineering culture. Watch now: 0:00 – Intro 0:42 – Google's Insane Compute Capacity 03:17 – TPU Monetization 05:24 – Why Google Doesn't Hoard Compute? 08:02 – Datacenter Buildout 15:01 - Does AGI Mean Job Displacement? 17:55 - NVIDIA vs TPU (Total Cost of Ownership) 23:25 - 8th Gen TPU 24:32 - Training vs. Inference 30:53 - Google's "Extreme Co-design" 35:01 - Working with Anthropic 37:46 - Serving Mythos-sized Models (10T) 41:42 - Google engineering culture (Steve Yagge tweet) 48:27 - Cybersecurity 51:50 - What keeps Thomas up at night?

opus 4.7 is unusable and I am saying this with a heavy heart, I continue to only use 4.6. 4.7 xhigh had to build some quick demo apps for me and simply forgot in the middle to change any of the schemas between apps, and reused as much as possible as if it didn't want to work

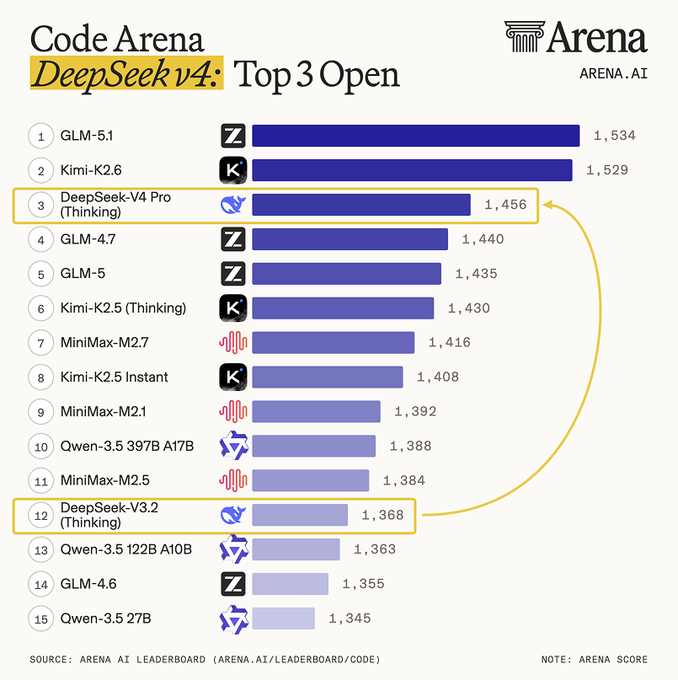
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n

My name is Ahmad and I have a Compute problem

Introducing Grok Voice Think Fast 1.0 A state-of-the-art voice model built for complex, multi-step workflows with snappy responses and high accuracy. It takes the top spot on the Tau Voice Bench and handles real-world messiness like noise, accents, and interruptions better than any other model in the world. x.ai/news/grok-voic…




My 4090 went from 26 -> 154 tok/s Qwen 3.6 27B🤯 Same GPU. Same Q4_K_M . No FP8, no extra quant. The unlock: ik_llama.cpp + speculative decoding using Qwen3-1.7B as the draft model. 85% acceptance rate. Full config + benchmarks 👇🏻


500+ likes in 28 mins. On their way to be the fastest model ever to get to #1 trending on HF! huggingface.co/deepseek-ai/De…

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n



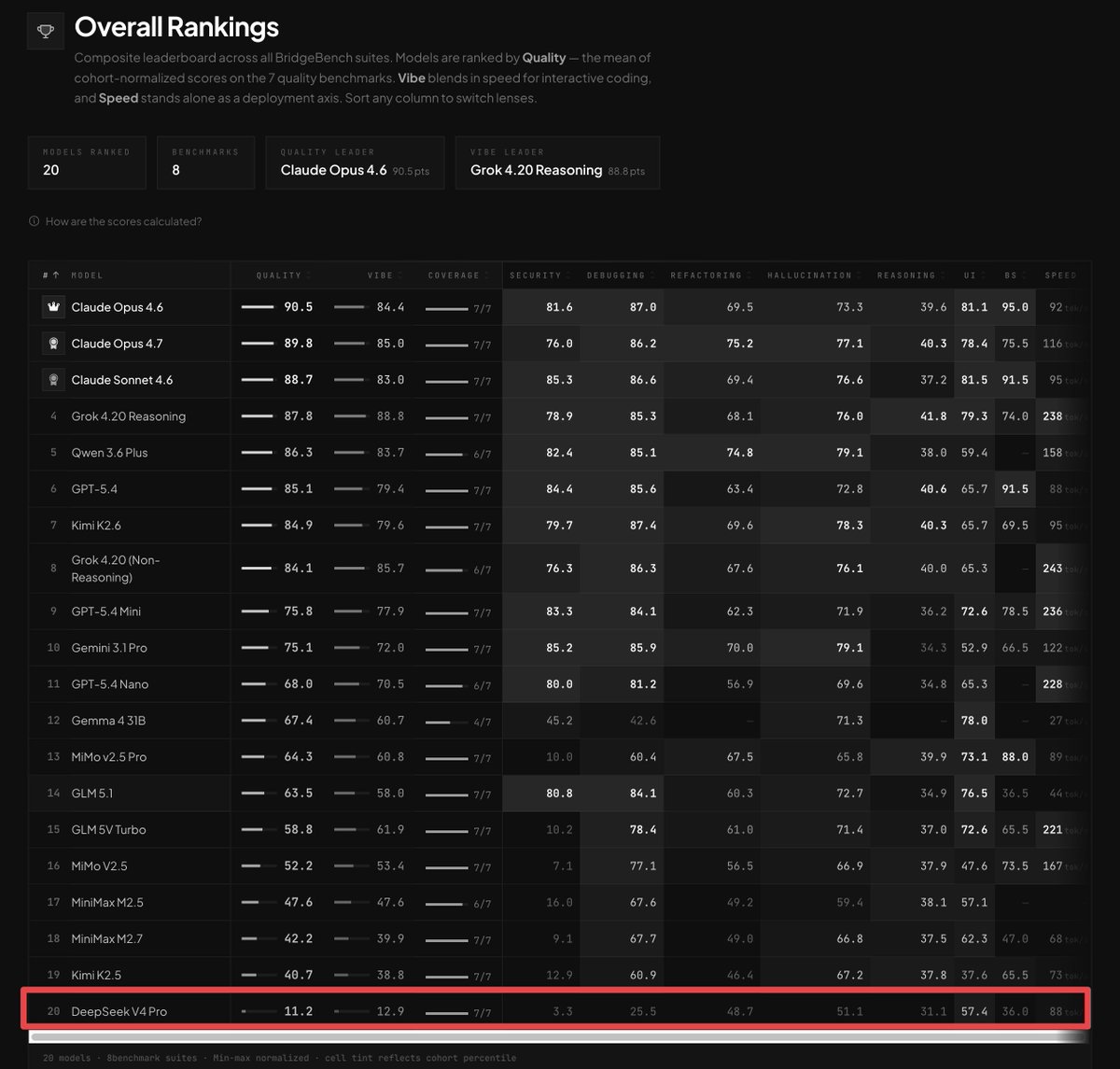
recommended reading. cool they are fixing things. but it's also a reason i switched away from CC. no control over the harness means having to wait for them to fix things. the model didn't change. the harness did.




