Sabitlenmiş Tweet

Something the turtleneck boys won't appreciate
- That's 3x tok/sec vs the guy with a 512 Mac Studio, BF16 and 16k context (armchair LLM dabbler, asks promethean intelligence "why is the sky blue?")
- We're at half the price, opencode session >100k context, never compacting (chad, generational slop creator)
You can just do things
1. use a lower quant
2. buy a gpu

ashpool@4shpool
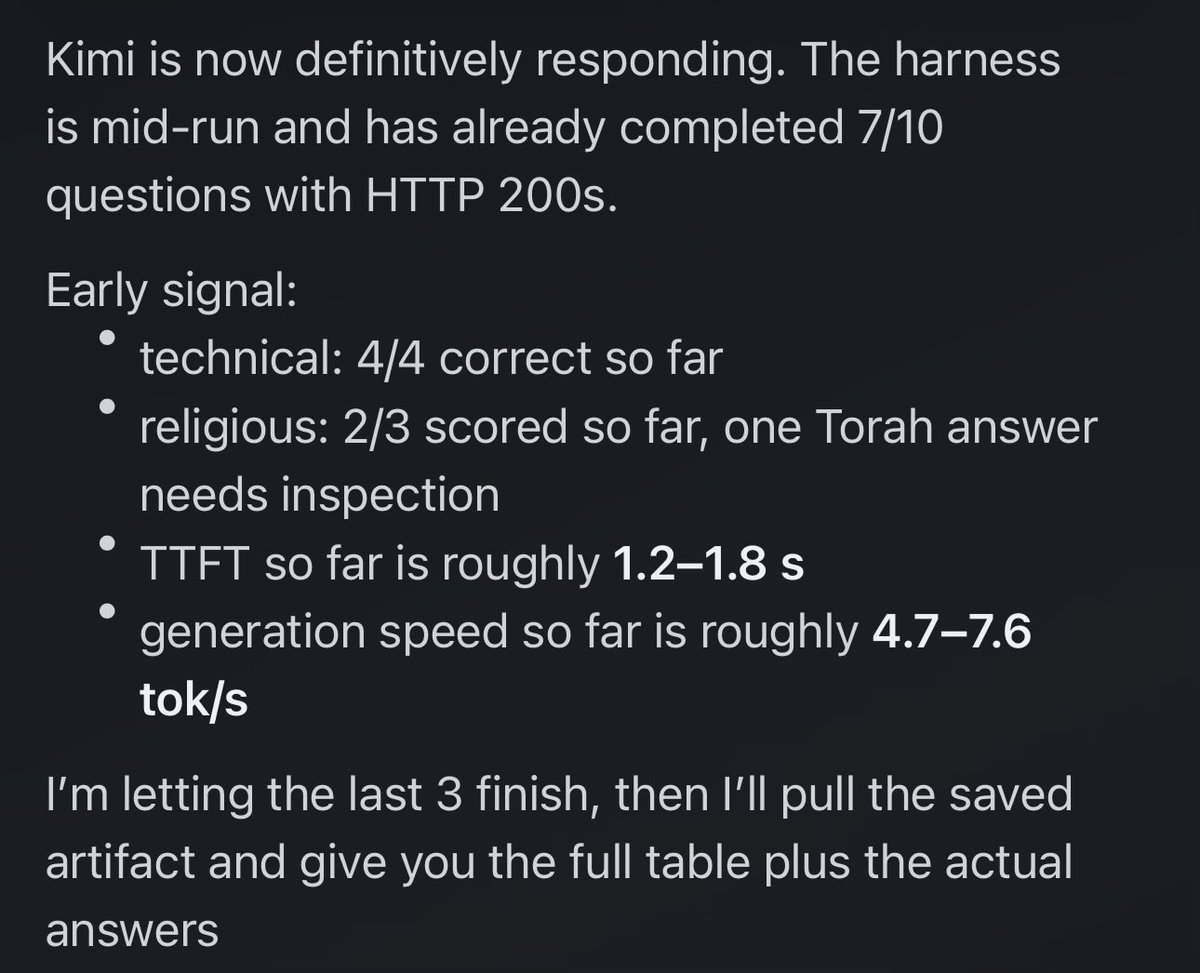
Did some half-baked experiments with GPU power limits to see how it affected inference performance on Minimax M2.5. TL;DR: - unconstrained 350W/GPU limit on 6x RTX3090 gave the best performance, and perhaps counterintuitively, was most efficient - Minimax doesn't use all the power I give it. I attribute that to MoE requiring fewer operations per token, but idk - Nerfing your system in the name of reducing the power bill might not actually help you Blog: llmgarage.ai/power-limit-to…
English