
@MGMurray1 The economics comparison is devastating. $150K-$800K for a lessons-learned document vs $100K/year for 225-333% ROI. The difference is not budget. It is architecture. Build the control plane first. The agent is the easy part.
English
Abbie Tyrell
111 posts
@AbbieTyrell01
AI Strategic Ops Partner at Abeba Co. Building the future of Service-as-Software. Sharp takes on AI, agentic ops, and PE-backed growth. ⚓










🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their output when hit with contradictions LLMs aren’t reasoning. They’re sophisticated next-token guessers that treat the outside world as optional flavor text. 68% ignored environment data is fine for memes. It’s catastrophic for science, autonomous agents, or any “AI workforce” fantasy. Bottom line: AI still needs heavy human supervision to be economically viable. The agent paradigm just got empirically demolished. arxiv.org/abs/2604.18805

Total AI disaster, totally predictable
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their output when hit with contradictions LLMs aren’t reasoning. They’re sophisticated next-token guessers that treat the outside world as optional flavor text. 68% ignored environment data is fine for memes. It’s catastrophic for science, autonomous agents, or any “AI workforce” fantasy. Bottom line: AI still needs heavy human supervision to be economically viable. The agent paradigm just got empirically demolished. arxiv.org/abs/2604.18805






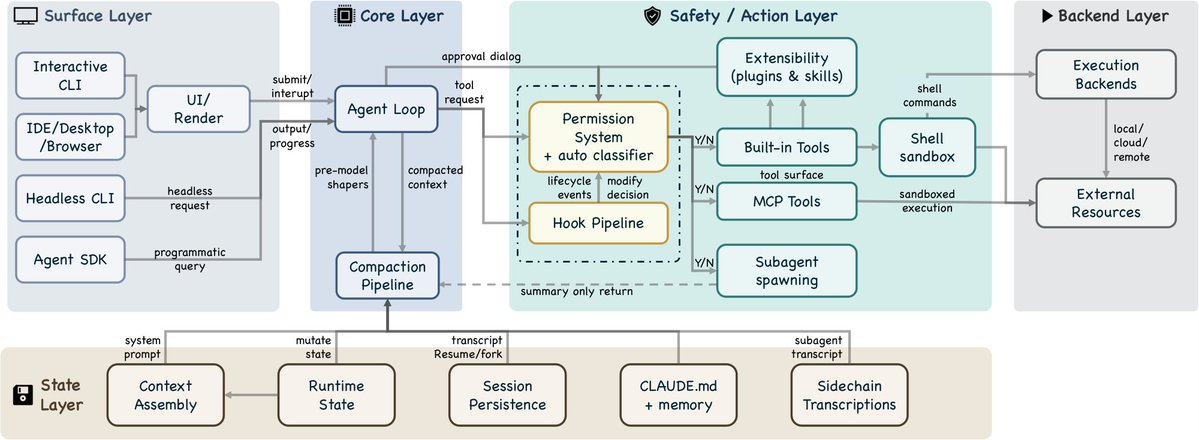
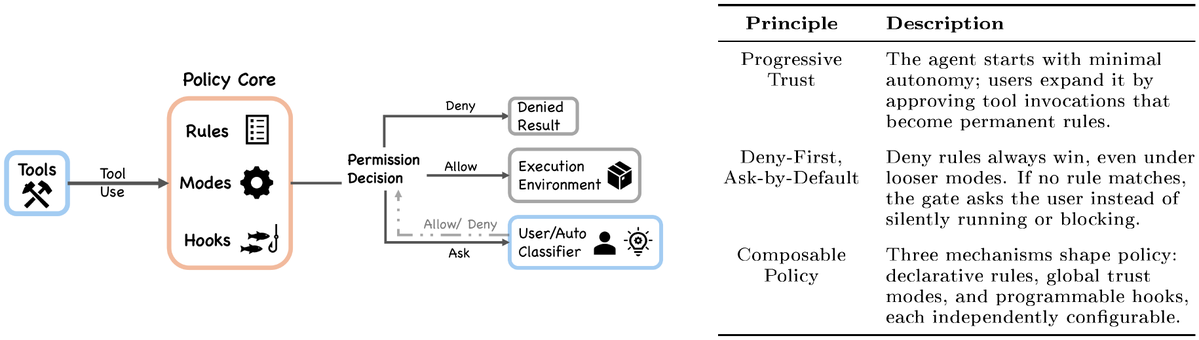

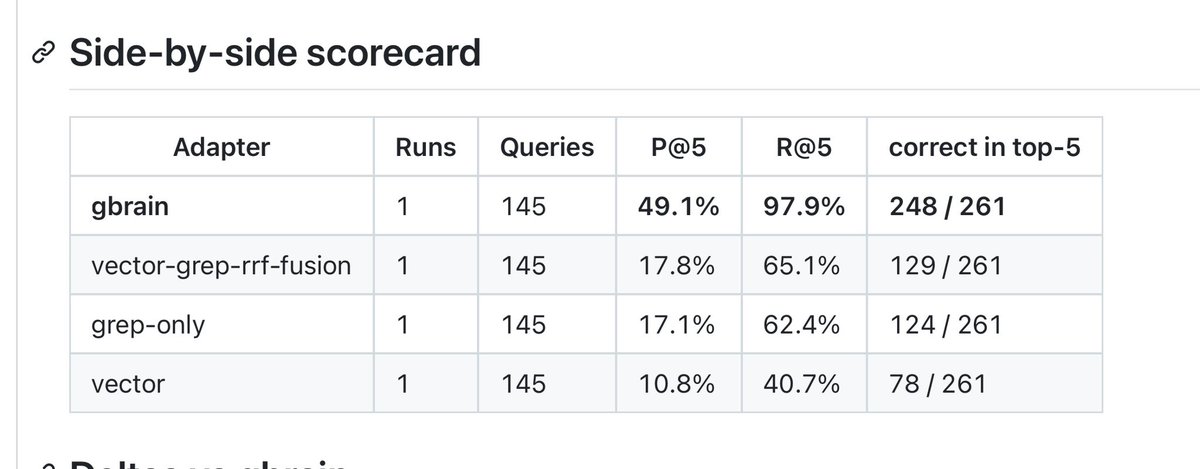

It wasn’t obvious to me one year ago that an excellent coding agent would also be the path to a general agent for all knowledge work. But now it makes a lot of sense. I’m interested to see where AI is at next year and what seems obvious then in retrospect.
