
Abhi Shamsundar
108 posts
Abhi Shamsundar
@Abhiramms2
Building enterprise networking products
Katılım Mayıs 2014
120 Takip Edilen91 Takipçiler

As speculated in the thread below, the DOJ finally settled with Juniper / HPE just 12 days before the trial was set to start.
They resolved the DOJ's concerns regarding the tiny bit of overlap in the transaction by divesting HPE’s Instant On campus business and licensing Mist software.
While this dragged on longer than it should have, it is ultimately a good result.
Disclosure: Long $JNPR in $ARB.to

Julian Klymochko@JulianKlymochko
Area of concern, WLAN, is a fairly limited segment of the proforma entity. How could they not come to a negotiated settlement here? $JNPR $HPE
English
@andylapteff Essentially I have used it for ZTP reasons for the most part. Coz the last thing a network admin wants to hear is a request for dhcp pool on VLaN 1 for ZTP reasons 😀
English
@andylapteff Similar logic can be applied to switches as well where you need in band management (oob isn’t available in most campuses) and you could ZTP access switches by configuring Distribution downlinks to have switch management VLaN as the native VLaN on the trunks.
English

Can someone help me understand why we need a native vlan?
My understanding is, the native vlan exists to transport untagged frames (frames without an assigned vlan).
Isn’t everything at layer 2 assigned a vlan? What untagged traffic is the native vlan helping us transport?
English
English

@jsnyder81 @Wirelessnerd @macpherson7 @Apple I'm going to start rotating the MAC addresses of my default gateways! That's not going to be a problem, is it?
English

“I have to agree that MAC rotation is a good idea” says @macpherson7 discussing the @Apple IOS 18 announcements. I think a lot of this room agrees. #WGCAmericas
English
Abhi Shamsundar retweetledi

My top pick on @theCUBE today was @ramirahim. He brought the insights. @zkerravala was on point & @furrier was in his element. Rami I hope to continue our convo on silicon. Thanks for sharing your views with our audience. #MWC24 youtu.be/u0eQMlQnmVM?si…

YouTube
English
Abhi Shamsundar retweetledi

Large Language Models, How to Train Them, and xAI’s Grok
When OpenAI released ChatGPT in November 2022, it took the world by storm, reaching over a million users in only 5 days. This kind of viral attention was previously unheard of in AI, driven by how closely the underlying language model seemed to replicate human intelligence.
Since then, there has been an explosion in AI activity, ranging from applications built on top of ChatGPT which seek to improve efficiency for mundane tasks, to new chatbots like xAI’s Grok which aim to replace ChatGPT altogether.
This explosion happened so quickly that few of us really took a step back to understand the basics. So we wanted to sit down and understand how LLMs work to figure out how new entrants like xAI will compete.
So what is an LLM?
A large language model is a type of neural network that can ingest strings of text and then predict the next sequence of words. Intelligent chatbots like ChatGPT are specialized versions of these language models that have been trained for the specific purpose of generating responses to questions.
To understand and generate text like humans, there are a few things that language models must be able to do:
1. Understand the meanings of various words
2. Understand the context of words in relation to other words
3. Remember long strings of these words
4. Do all of the above very quickly
Until recently, even the best-in-class language models struggled to do all four. They were either slow and inefficient to train, had poor memory, or were bad at recognizing context. This resulted in models that failed to effectively replicate human abilities.
In 2017, a new type of architecture called a “transformer” was introduced that promised to solve many of these issues. Two key breakthroughs, “positional encoding” and “self-attention” made this architecture much more efficient to train and better at recognizing the context of words.
As language models were trained with more compute power and data using this architecture, new capabilities emerged. Today, models can reason about topics, write code, and even understand information across multiple modalities including images and audio.
But how do LLMs work?
LLMs work by first taking a string of words and representing them as sequences of numbers called vectors. Each number within the vector captures the meaning of a word in relation to other words. Think of this like a graph. When two words are closely related, they’re mapped closely together.
The position of each word in the sentence is also represented as a vector, allowing the model to capture context without needing to process each word serially - a key development that made transformers much more efficient than previous models.
The “self attention” layer, which is what transformer models are known for, then allows the model to hone in on relevant words to further improve contextual awareness. Take the following sentence:
“Yesterday, I went to the bank to deposit money.”
The word “money” allows the model to understand that the sentence refers to a money bank, not a river bank.
So how do you build an LLM?
Large language models like ChatGPT and Grok are built in two key stages:
1. The training stage, which feeds the model billions (and often trillions) of words so that the model can learn what different words mean and how closely they are related, with the goal of eventually generating text by predicting the next word.
2. The fine-tuning stage, which trains this pre-trained model to perform a particular kind of task like answering questions.
Stage 1: Training the model
To train a language model to generate text, you first need to collect a massive amount of data on which to teach the model to predict the next word. This is achieved by scraping the internet for text data from a diverse range of sources, and then cleaning this up to remove duplicates, spelling errors and issues that you don’t want the model to learn.
Once the training dataset is assembled, it is then turned into a series of incomplete sentences that are used to train the model to predict the next word.
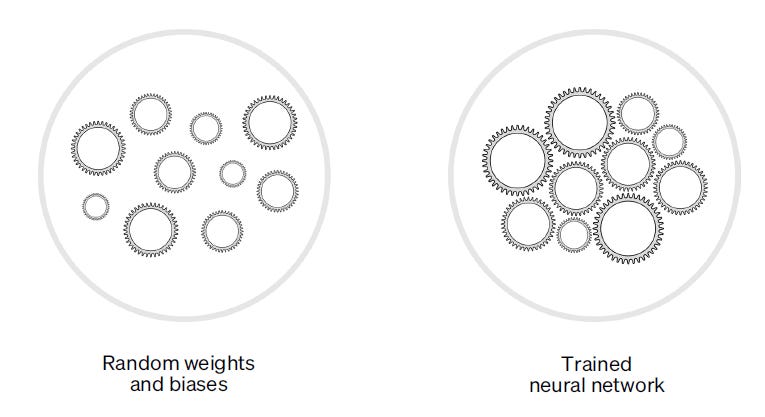
Language models are types of neural networks that use layers of nodes to generate their predictions. Nodes are like gears in a machine. Individually, they lack meaning, but when trained to work together, nodes can understand and interpret complex data like language.
Initially, the connections between nodes will be assembled randomly, so the model’s prediction will also be random. But as the model is trained, the nodes learn to predict the output that we want to see by adjusting the weights and biases that connect them together.
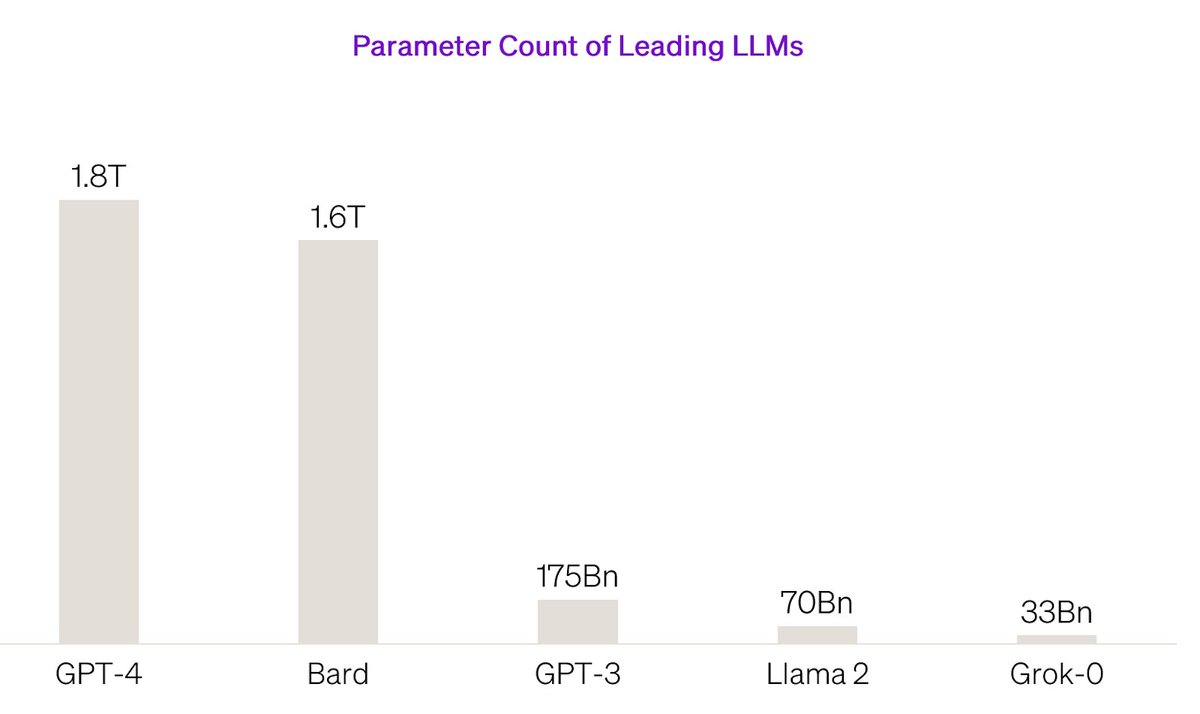
The number of weights and biases that a model uses to make a prediction is called its “parameters”. The more parameters there are, the more complex the model. While this often leads to better performance, it also comes at the cost of higher latency and computational demand. Newer language models like Grok aim to outperform larger models using fewer parameters by improving on the architecture of models and leveraging higher quality training data.
During the training process, the language model learns to map the relationships between words and predict the next word in a sequence. But it still needs to learn how to perform specific tasks like responding to questions. This is the role of fine-tuning.
Stage 2: Fine-tuning the model
To build a chatbot that can respond to questions, pre-trained models are trained on thousands of examples of prompts in the desired question-answer format until the model can predict an appropriate response to a given question.
Then, once the model can predict answers in the desired format, human feedback is used to rank several of the model’s possible responses from best to worst in a process called “reinforcement learning from human feedback” (RLHF). This feedback is used to train a second “reward model” to guide the LLM to predict the best response.
Companies building new language models today face two major challenges. The first is that exponential increases in the amount of data used to train a new model only result in linear improvements in performance. So with an abundance of data available for training, all else equal, models eventually converge towards a single level of performance.
The second is a lack of context. Many models like ChatGPT lack context beyond their training period, meaning that they have no awareness of information and events beyond a given date. When asked about information after this period, they either refuse to answer, or worse still, hallucinate and provide a convincing but made-up response.
So, if you want to build a chatbot that is constantly improving and context-aware, how do you do it?
A new entrant to the race: xAI and Grok
xAI launched its new chatbot Grok on November 4th, 2023, just four months after the company was officially announced. Grok’s initial model, Grok-0, demonstrated impressive performance with limited resources, directly competing with Meta’s LLaMA 2 model using half the complexity (70 billion vs. 33 billion parameters). Its next iteration, Grok-1, showcased even better results, surpassing all other models in its compute class including GPT-3.5, which took OpenAI several years to achieve.
What makes xAI’s model unique is its access to a proprietary and constantly-evolving dataset of tweet activity, which generates over 12 terabytes of data daily, containing extensive data on human interactions and current events in multiple formats (text, images and even audio), and distributing its model to an existing user-base of more than 500mm MAUs on X.
Access to this dataset of constantly updated information can help to minimize hallucinations and provide more context-aware responses when presented with questions about recent events. xAI can quickly retrieve information from reputable sources on X, and use the wisdom of crowds to interpret the sentiment around a given topic, allowing the model to provide more context-aware responses to queries.
Having access to this data in multiple formats such as images and audio can also help xAI’s model achieve a deeper and more nuanced understanding of the world. For example, understanding a person’s facial expressions while they are speaking results in a much richer interpretation of their speech than just an audio recording. In the same way, leveraging multi-modal inputs on X can help xAI’s model to better understand the context of news and other world events.
The final differentiator is distribution. xAI already has built-in distribution through the X platform, which has more than 500mm monthly active users. Assuming modest uptake, this allows xAI to rapidly improve its models through much faster reinforcement learning from human feedback loops than other models, providing the company with another set of proprietary data that can help propel its model further than competitors.
Conclusion:
As the foundational layer of language models is becoming increasingly difficult to improve with more data, the quality of the data that these models are trained on becomes a key differentiator. xAI’s Grok benefits from a vast dataset of diverse and up-to-date information in multiple formats, as well as a pre-existing user base of 500mm people to rapidly improve its models. With high quality real-time data and the capital to scale, Grok has the opportunity to become the most up-to-date, customizable and context-aware language model in the race to achieve AGI.
Disclaimer: The views and opinions expressed above are current as of the date of this document and are subject to change without notice. Materials referenced above will be provided for educational purposes only. None of the above will include investment advice, a recommendation or an offer to sell, or a solicitation of an offer to buy, any securities or investment products.


English
17th of July marks an important milestone personally, its been 17 years of working in the enterprise networking space in various capacities as QA, TAC, Solutions Engineering and now PM. I have started penning my thoughts down as a series
lnkd.in/gH6v8cwJ
English
@GjermundRaaen Very sorry to hear this. Wish you a speedy recovery
English

Sorry to, but I have severe lung cancer.
It was discovered 6 weeks ago and after a lot of medical surveys and tests it is concluded that the tumor is ROS1+ lung cancer.
Yesterday I startet on targeted therapy with pills.
My hope is that those pills does a good job.
English
@malief46 @HypergeekWiFi @DoubleTree especially if it’s a subsidiary like Home2 suites, when they refused the room and were rude, the customer care said they couldn’t do much sent me a voucher for a day.
English

@HypergeekWiFi @DoubleTree I called AMEX, don’t really think they will be able to do anything but they started a dispute. Tbh I’m more concerned about the lack of accountability for his actions from Hilton. Very disappointing.
English
So learned something about @HiltonHotels policy. If a manager of their hotels is
rude and unprofessional to you to the point that either he cancels your
reservation or you have to do it because of their behavior, they will charge you
and there is no accountability.
English
@FieldDayHunt Base wired assurance covers campus fabric architecture builds
English

@Abhiramms2 Does the Mist Campus Fabric need Marvis VNA subscription or is it covered in Wired Assurance?
English


We are looking for a Technical Product Manager, Following are some of the key skills we are looking for:
- Familiarity with API, Automation of deployments
- Large scale wired/wireless/wan deployments
- Strong Wired networking background - EVPN/VXLAN will be a plus
English
@JonesyChris Hey Chris - happy to help. Please ping me if you have time tomorrow, we can take a look at this together.
English

Anyone do much playing with Juniper switches connected to Mist cloud? having issues getting dynamic port configuration to work with plain MACs, for devices that don't do LLDP, LLDP via name/ID work fine.
English
@Robb_404 I guess you don’t have the quieter faster 4100. Shame …
English
A little hide the home IDF behind the piano action 😂
Lots of designing and #3Dprinting of mounts.

English

Finally cracked open my bottle of Crowded Barrel Phoenix. It’s very different for sure.

English
@jsnyder81 @JuniperNetworks Great to hear from you, it was an exciting time at #NFD30 this year. Lots of things that you helped us are now officially GA. Hope you are doing well and how’s the new role ?
English
Finally catching up on @JuniperNetworks campus fabric. from #NFD30.
Congrats @Abhiramms2 Pods and service blocks look awesome.
English

Something reminded me of this video so I really had to search and re-tweet 😂
Alex Cohen@anothercohen
Product managers helping the team ship a new feature
English
@malief46 @JuniperNetworks Thanks Ali - hope you enjoyed the presentation.
English