Sabitlenmiş Tweet

ICYMI, all of the sessions from #tvmcon are available for streaming! Catch up on the latest advances, case studies, and tutorials in #ML acceleration from the @ApacheTVM community. tvmcon.org
English
Apache TVM
685 posts

@ApacheTVM
Open deep learning compiler stack for CPUs, GPUs and specialized accelerators. Join us for the TVM and Deep Learning Compilation Conference https://t.co/i6MTbWYt87

This Saturday Jan 31 at Noon PST we have one of the founders of the whole field of ML Systems @tqchenml who will be giving a talk on tvm-ffi - an open ABI and FFI for ML systems which has grown tremendously in relevance with the explosion of Kernel DSLs youtube.com/watch?v=xMzcs6…
🚀 MLSys 2026 Contest - @nvidia Track is LIVE! Registration is now open for the FlashInfer-Bench Challenge! Submit high-performance GPU kernels for cutting-edge LLM architectures on NVIDIA Blackwell GPUs. Three Tracks * MoE (Mixture of Experts) * DSA (Deepseek Sparse Attention) * GDN (Gated Delta Net) Human experts AND AI agents welcome — evaluated separately. Let's see who builds the best kernels! 🤖 🎁 Prizes: Winners take home NVIDIA GPUs and are invited for presentation at MLSys 2026. ⚡ First 50 teams to register get free GPU credits from @modal - huge thanks for the sponsorship @charles_irl ! Whether you're a kernel wizard or building autonomous coding agents, we want to see what you've got. 🔗 Contest details: mlsys26.flashinfer.ai See you at MLSys 2026! 🔥



Just open-sourced VibeTensor — the first deep learning system fully generated by an AI agent, with 0 lines of human-written code: github.com/NVlabs/vibeten… It’s a working DL system with RCU style dispatcher, a cache allocator and reverse-mode autograd. The agent also invented a Fabric Tensor system — something that doesn’t exist in any current framework. The Vibe Kernel includes 13 kinds and 47k LOC of generated Triton and CuteDSL kernels with strong performance. VibeTensor was generated by our 4th-generation agent. It shows a “Frankenstein Effect”: the system is correct, but some critical paths are designed in inefficient ways. As a result, performance isn’t comparable to PyTorch. I haven’t written a single line of code since summer 2025. I started this effort after @karpathy 's podcast — I didn’t agree with his arguments, so Terry Chen and I began using it as a stress test for our agents. The “Frankenstein Effect” ended up exposing some of our agent’s limitations — but the direction is clear.

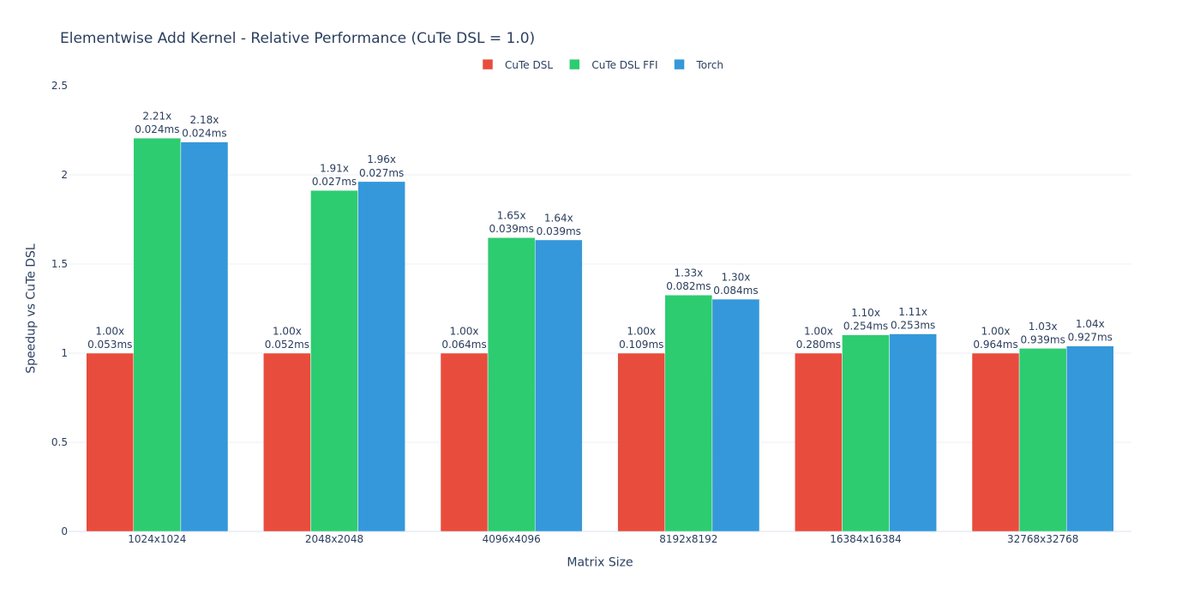


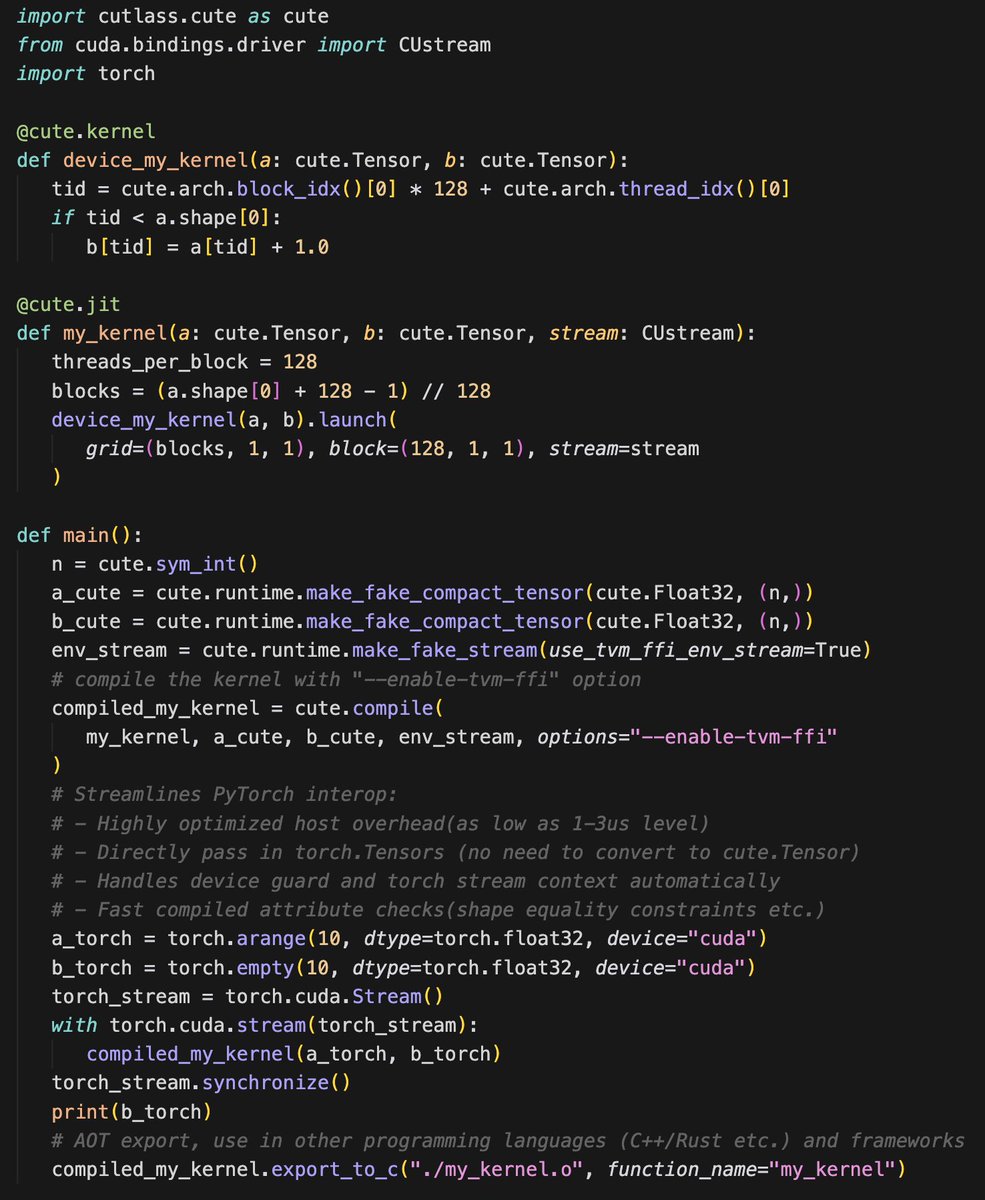
CuteDSL 4.3.1 is here 🚀 Major host overhead optimization (10-40µs down to a 2µs in hot loops_, streamlined PyTorch interop (pass torch.Tensors directly, no more conversions needed) and export and use in more languages and envs. All powered by apache tvm-ffi ABI

🚀 tilelang now fully embraces tvm-ffi! 💡 Not only is the compiler deeply powered by tvm_ffi, we've also replaced old pybind parts with tvm_ffi too. ⚙️ With host codegen moving attribute checks from Python → C++, CPU overhead dropped 2.1×–3.8×, compile speed boosted 2.1×–3.3×!

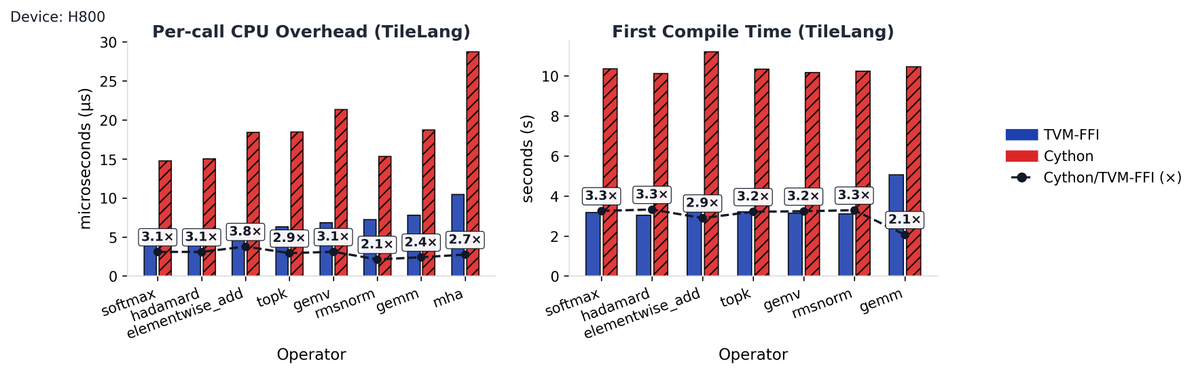
🚀 tilelang now fully embraces tvm-ffi! 💡 Not only is the compiler deeply powered by tvm_ffi, we've also replaced old pybind parts with tvm_ffi too. ⚙️ With host codegen moving attribute checks from Python → C++, CPU overhead dropped 2.1×–3.8×, compile speed boosted 2.1×–3.3×!


📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…

📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…

📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…