CKtalon
80 posts


@RealJosephus @suchenzang Seems like the corpus used to train the tokenizer isn’t as clean as the corpus used to train the LLM
English



this new "o200k_base" vocab for gpt-4o makes me want to clutch my pearls

English
@drummatick @laurensweitkamp @suchenzang With 200k vocabulary, it’s entirely possible to have many full words
English

@laurensweitkamp @suchenzang Which tokenizer? The whole idea behind sub-wording was to make we learn the representation better
English
@SashaMTL Just stating facts. BLOOM having 1131 citations despite being released in 2022 while Llama2 having 3855 despite being released 8 months later. BLOOM was just severely undertrained with the amount of limited compute they had, with way too much ambition to do so many languages.
English

@CKtalon Time will tell! But also, not very nice of you.
English
So LLaMa 3's carbon footprint is... huge? 🤯
They estimate it to be 2,290 tons of CO2eq, compared to 550t for training GPT-3 and 66t for training *all* of the BLOOM models (1B-176B) 🌬️


English


Waiting on a GPU and an electrician but this thing is about ready.
I’ve gotten a lot of questions about this AMD Epyc 7x4090 build, thinking of doing a Spaces on parts selection, etc if you guys think you’d be interested

English
@mov_axbx Lovely rig.
This week I managed to find 8x slim 3090 turbos. This let me squeeze them into a super server. Was planning to go open rig if I hadn’t found the turbos.

English

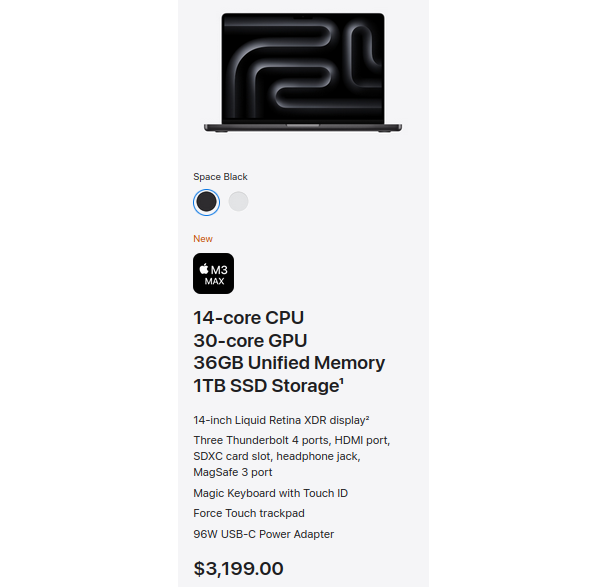
After 20 years of Linux loyalty, here I am, tempted by Apple's MLX for local inference
- ($3,199) MacBook Pro M3 Max
- ($2,500) 2x RTX 3090
Thanks, Apple MLX, for my existential tech crisis. 🙃

English

We’re giving you TWO ways to WIN a one-of-a-kind GeForce RTX 4080 SUPER signed by NVIDIA CEO, and founder, Jensen Huang 👀
If you’re at CES head to our partner booths to enter 👉 nvidia.com/en-us/geforce/…
Want to WIN here on social?
⚫Comment #RTXSUPER
⚫Like this post

English

@abacaj I have a 100m translation model I trained for 2 month+ on ~18B tokens infinite loop of epochs.
It got stuck.
Full stop, the loss doesn't move.
(No matter what trick I tried: batch_size, grad noise/clip, lr, w_decay..)
There is a HARD limit to finite params..
English
@charlieholtz @elevenlabs In the not-so-distant future, pairing this with the Meta Ray-Bans and have it narrate whatever you see will be mind-blowing.
English

David Attenborough is now narrating my life
Here's a GPT-4-vision + @elevenlabs python script so you can star in your own Planet Earth:
English

@BramVanroy OpenNMT does have most of those implemented since they are also now supporting LLMs. Marian looks dead, perhaps due to lowered importance by MSFT in preference of LLMs.
English
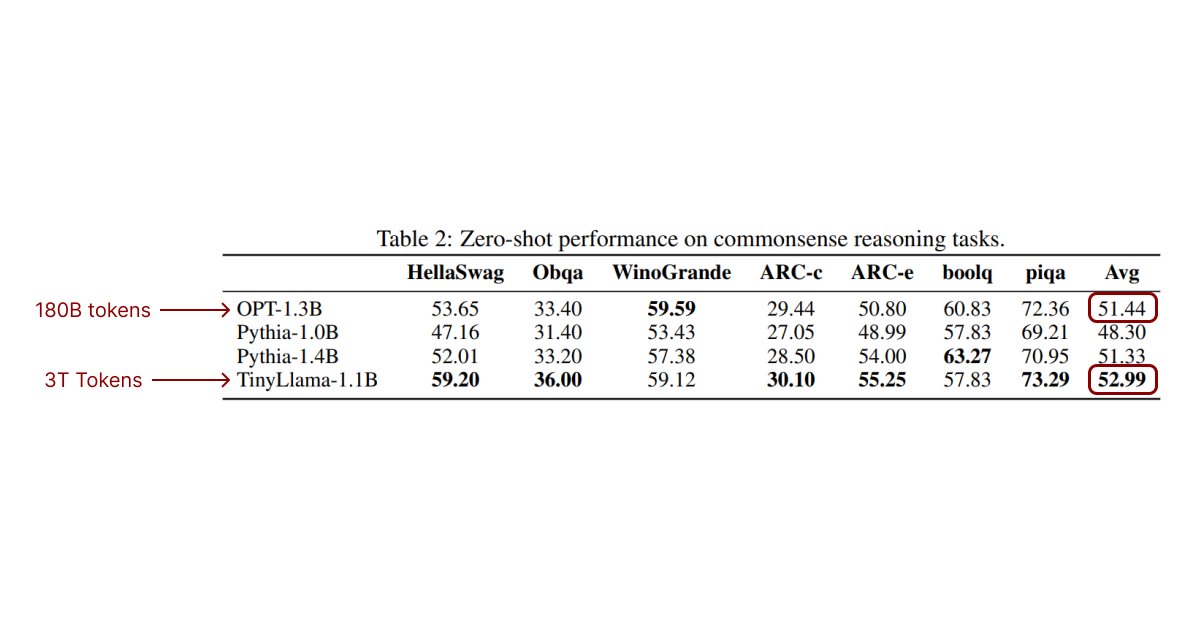
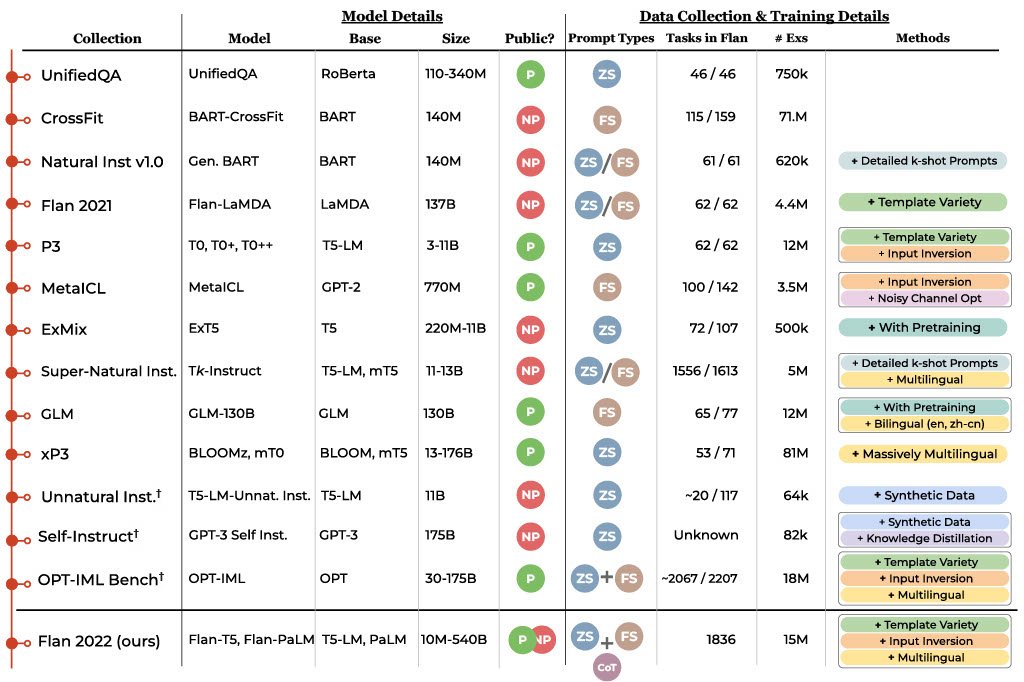
The most powerful open source instructions dataset:
Flan.
378 Million samples. (~300GB) [1]
- Link: huggingface.co/datasets/Open-…
Why should you care? 🤔
- Flan is an incredibly powerful dataset [2] and some famous models trained on it (FlanT5, UL2..) hold the top positions on various leaderboards to this day.
- The main reason for it is the quality and diversity of the data.
- It is huge: Ever wondered "What would happen if we just merged all instructions datasets together into a single huge one?", this is basically the motivation behind the Flan dataset.
- It is balanced (!!) which promotes the models trained on it to generalize better to arbitrary tasks down the line.
Flexibility:
- Zero-Shot vs Few-Shot: For many of the tasks you can fetch the same task either for Zero-Shot: No solved for demonstration or Few-Shot.
- Chain of thought built in on some of the tasks.
The "next step"..
A small part of Flan had been augmented with additional explanations in the past.
The result of this was the first model ever to rival ChatGPT on vicuna's benchmark.
And again..
This was just a small part of Flan..
----
[1] ai.googleblog.com/2023/02/the-fl…
[2] arxiv.org/pdf/2301.13688…
(* This paper is a must if you are building text datasets)
English
@Science_boy_H @huggingface I’m suspecting QLoRA or LoRA doesn’t help for adding/increasing a model’s second language capabilities
English

I just finetuned Llama2 on Arabic dataset using Qlora and sfttrainer
GitHub link : github.com/h9-tect/llama2…
@huggingface link : huggingface.co/HeshamHaroon/l…
English
@DanielSMatthews @nearcyan Text isn’t one to one. More of a translated summary
English

@nearcyan So if you fed the original and the translation into an AI training session you'd have an AI that did a good job of translating Chinese original science to English?
English


@ID_AA_Carmack But this is twice the FLOPs for three times the cost, right?
English

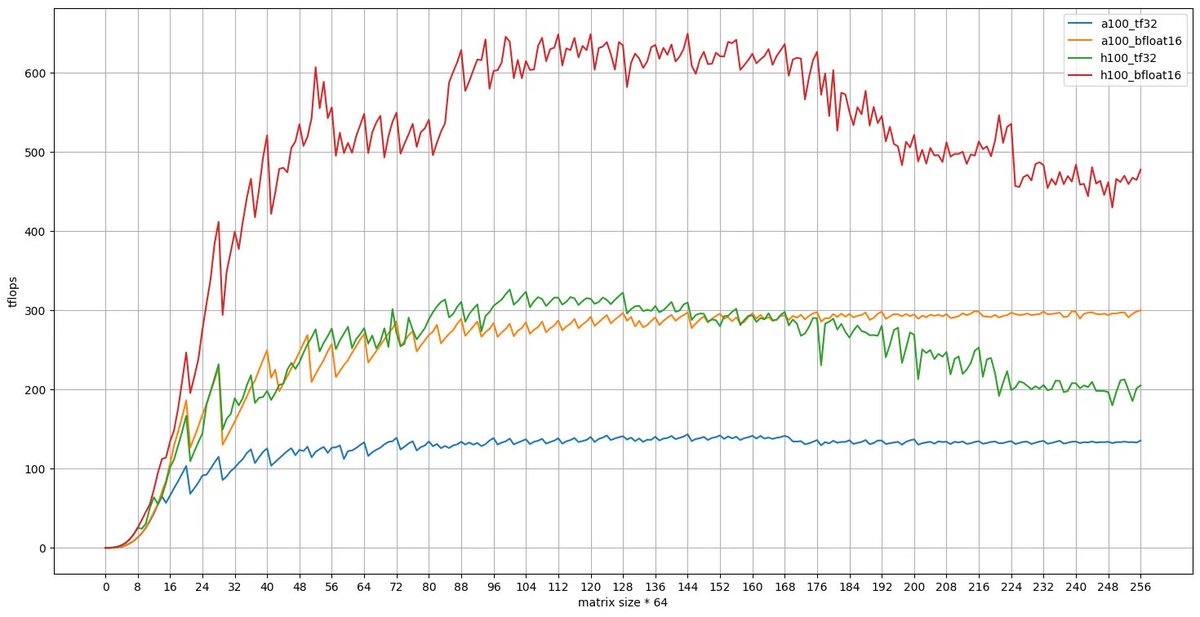
H100 GPUs are very fast!
For those unfamiliar with GPU matrix multiplies, the jaggies in the graph relate to packing occupancy, and are not noise. You can’t just divide theoretical teraflops by your problem size and get accurate times.
English
@e270889o @ID_AA_Carmack Plenty of ram, but slow compute-wise. Apple’s CoreML is too opaque to developers, so the Neural Engine hasn’t been usable in an obvious way yet.
English
I’m a little surprised there isn’t more excitement around Nvidia’s 256 GPU unified memory NVLink clusters, but I have heard from a couple places that it is considered constraining. I wonder if the optics are that your cluster isn’t serious with less than a four figure GPU count.
English

