
Dado retweetledi

My wife mentioned a nice private school over dinner this week
She said the campus was beautiful
I asked what's the tuition
She said we should look at it as an investment in him not a cost
I made a note
She said don't make a note
I said I always make notes
She said this isn't a deal
I said everything is a deal
She closed her eyes
She said we'd discuss it Saturday
I agreed
Saturday 7:02am
She came downstairs in her Saturday robe
Coffee in hand
I had my cargo shorts on
The dining room had been cleared
The projector was on
The analyst was at the head of the table
Quarter zip on, three iced coffees, a legal pad, and two laptops
He had been there since 6:44am
I texted him at 11:14pm Friday
The text said dining room 6:45am bring the model
He sent a thumbs up
My wife stopped in the doorway
She said what is this
I said you said you wanted to discuss it
She said this is not a discussion
I did not respond
She sat down anyway
The analyst stood
He said good morning ma'am
She did not respond
He sat back down
A printed deck in front of each seat
A fourth copy in case
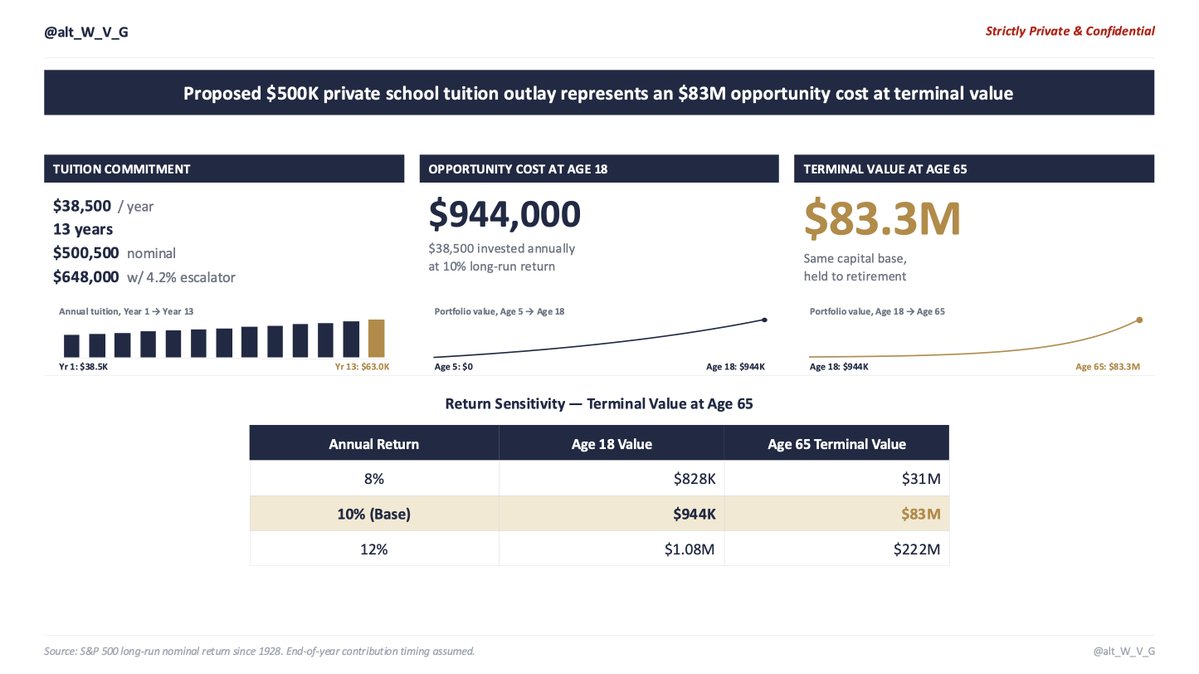
Slide 1 Tuition Schedule
$38,500 per year
Thirteen years
$500,500 nominal
Before escalators
The school has raised tuition 4.2% per year for a decade
With escalators $648,000
My wife said okay
I said I'm not done
Slide 2 Opportunity Cost
Even before escalators
$38,500 invested annually
10% nominal return
S&P long-run average since 1928
By his eighteenth birthday $944,000
My wife said we can afford it
I said I know that's not the slide
Slide 3 Terminal Value at Age 65
$83 million
She was quiet
The analyst slid the sensitivity tables across the table
8% return $31 million
10% return $83 million
12% return $222 million
She did not look
She said this isn't about money
I said it's always about money
She said no it isn't
I said then what is it about
She did not answer
She said you can't put a dollar value on his teachers his classmates his environment
I said I can the analyst already did slide 6
He flipped to slide 6
She did not look
She said the school is the best in the city
I said best is a feeling
She said it produces the best students
I said the students were already the best before they got there
She said our son deserves it
I said our son deserves $83 million
My son walked in
He is five
Dinosaur pajamas
He looked at the projector
He looked at the open deck on the table
He looked at slide 3
He said are we modeling pre-tax or after-tax
The analyst opened a new tab
My wife looked at the ceiling
He said what's the discount rate
The analyst set down his pen
She closed her eyes
He said is this the same return assumption from the 529 conversation
The analyst stopped typing
He looked at me
I did not say anything
She stood up
Sat back down
He said dad can I help
I said yes
He pulled up a chair
The analyst handed him a printout
He started reading
My wife watched him read
She watched him for a long time
She said his name
He looked up
She said do you like school
He said the work is too easy and the kids don't ask questions
She did not respond
She looked at the ceiling
She walked out of the room
The analyst started packing up
He said should I follow up Monday sir
I said no follow up needed
He'll be fine
Sent from my iPhone
English
















