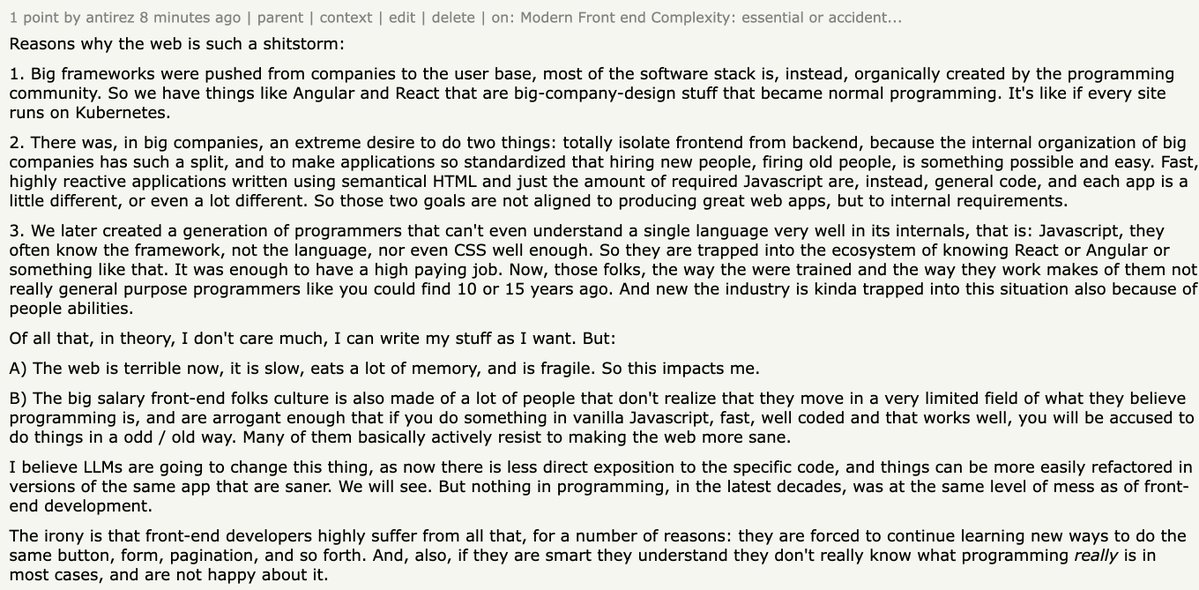
@VictorTaelin Gemini 3.1 pro being number 2 doesn’t sit well with me. I have exclusively used Gemini-Cli & codex-cli and codex-cli just solved way more issues.
English
Sebastian
1.5K posts



With GPT-5.5, Codex now gets more of the job done across the browser, files, docs, and your computer. We've expanded browser use so Codex can interact with web apps, and test flows, click through pages, capture screenshots, and iterate on what it sees until it completes the task.

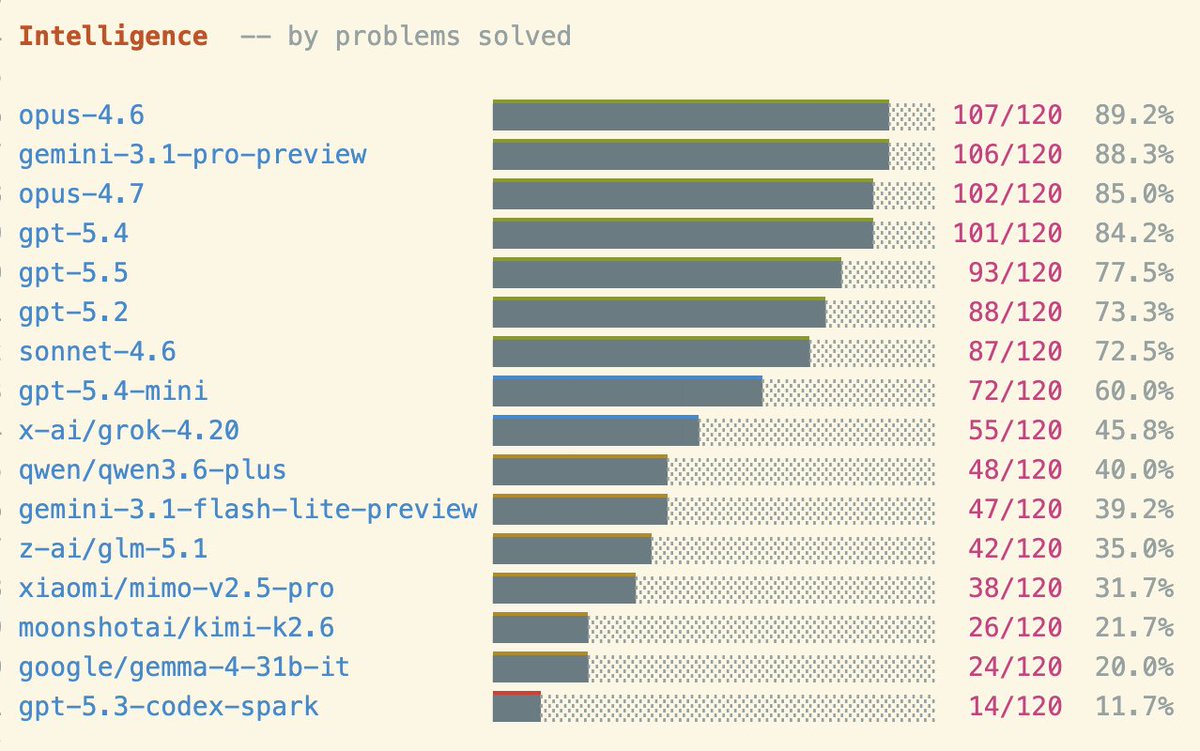
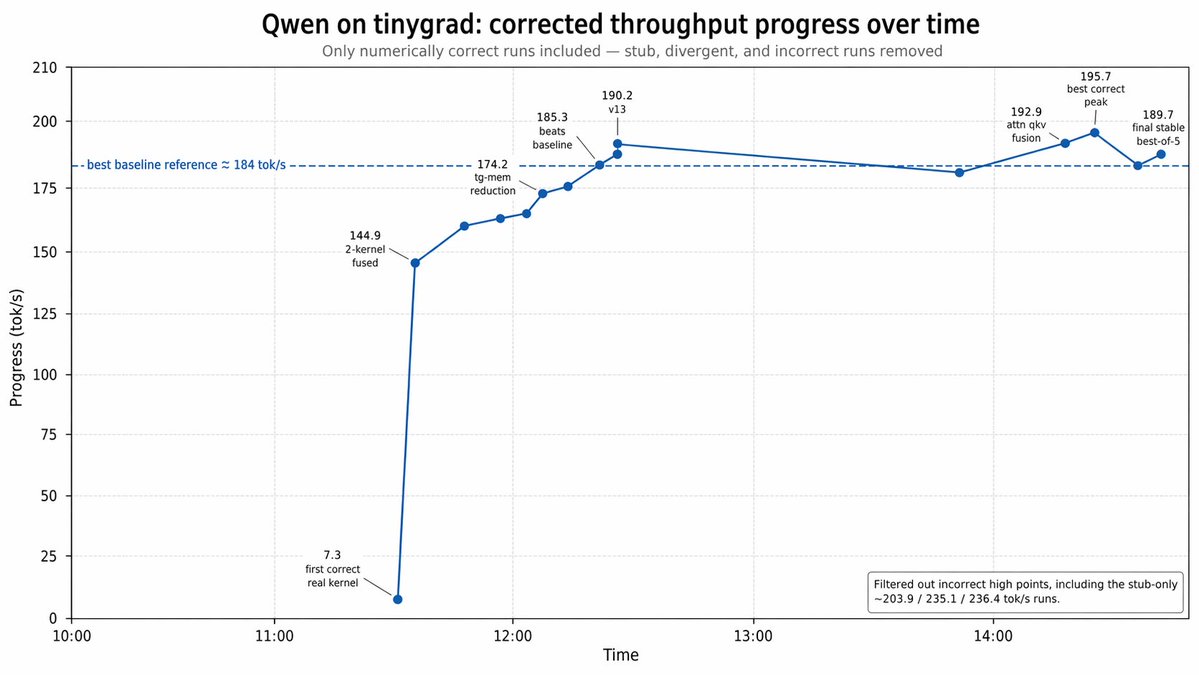
We set out to replicate Kimi's 193 tok/s Qwen3.5-0.8B on M3 Max. Our baseline is already 178 tok/s, beating LMStudio (160) and llama.cpp (140) out of the box, but with tinygrad's custom kernel feature Claude cranked it to 195.7!

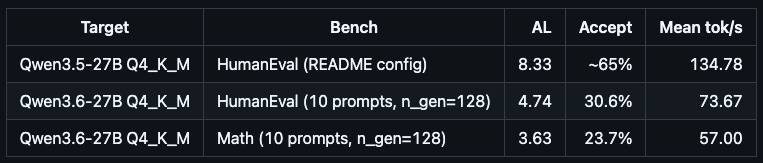


Shocking result on my pelican benchmark this morning, I got a better pelican from a 21GB local Qwen3.6-35B-A3B running on my laptop than I did from the new Opus 4.7! Qwen on the left, Opus on the right





did they really have to rub it in with the title like this

The degree to which you are awed by AI is perfectly correlated with how much you use AI to code.

HTML in Canvas API is NUTS
@ivanfioravanti Im pretty sure it’s about this PR github.com/ggml-org/llama… documented how to use here: #n-gram-mod-ngram-mod" target="_blank" rel="nofollow noopener">github.com/ggml-org/llama…

The founder of Postman says you have to kill your existing org chart, especially if you're still operating with a pre ai hierarchy arrangement. The modern org chart, according to @a85: - wide span of control (even within exec team) - work directly with ICs, not through layers - either you're building, or you're selling Projects are led by staff/principal engineers with high agency. They see across the board as well as deep in the stack. Product managers are building APIs and prototyping in Claude instead of writing PRDs. Designers are shipping PRs through Cursor directly instead of relying solely on Figma. Everyone is building. And the management's job is to develop better judgment.


Let me demonstrate the true power of llama.cpp: - Running on Mac Studio M2 Ultra (3 years old) - Gemma 4 26B A4B Q8_0 (full quality) - Built-in WebUI (ships with llama.cpp) - MCP support out of the box (web-search, HF, github, etc.) - Prompt speculative decoding The result: 300t/s (realtime video)