
David Jin
116 posts
David Jin
@DaviJin
Ph.D. student in CSE @MIT; B.S. in Physics & Data Science @Caltech & @GrinnellCollege
Katılım Haziran 2015
614 Takip Edilen104 Takipçiler

David Jin retweetledi


David Jin retweetledi

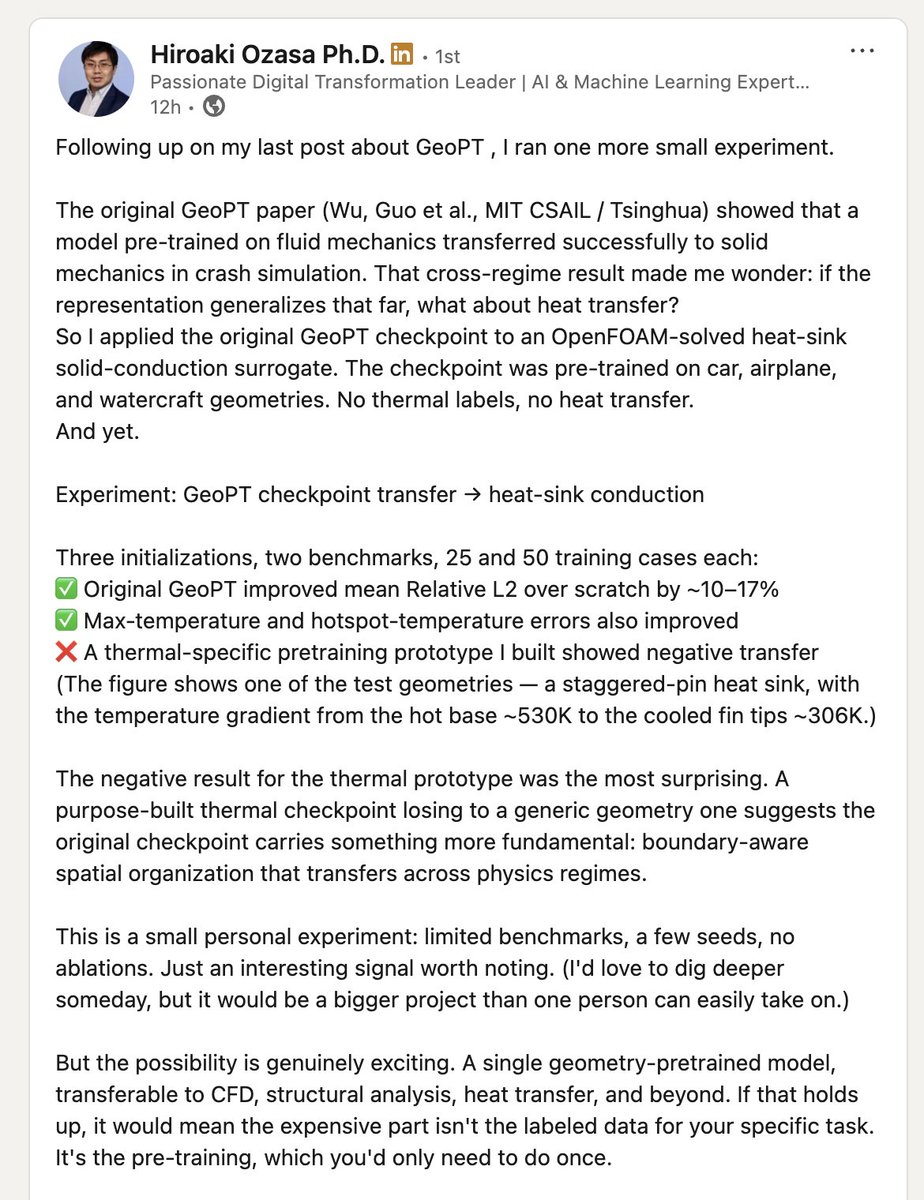
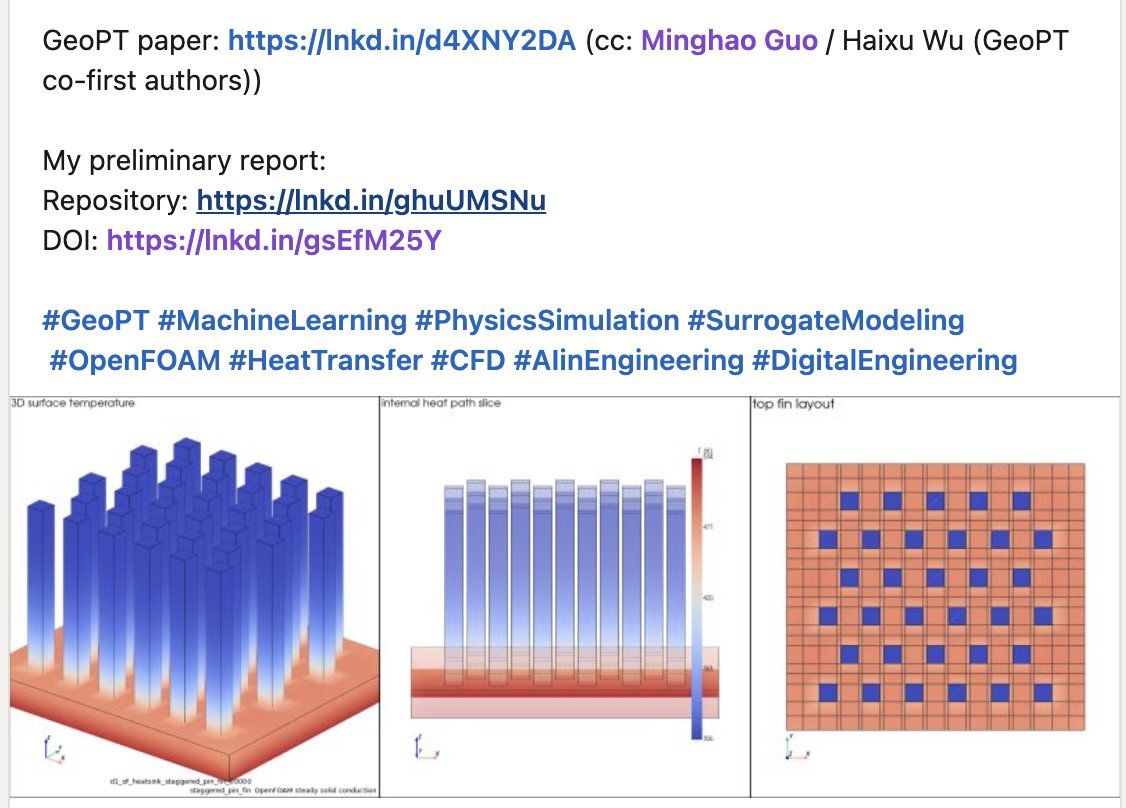
I was very excited to saw a really interesting independent GeoPT experiment from Hiroaki Ozasa.
He tested the original GeoPT checkpoint on a completely new OOD physics setting: heat-sink solid conduction / heat transfer.
This was not a benchmark from our paper. The GeoPT checkpoint was pretrained on car, airplane, and watercraft geometries.
No thermal labels.
No heat-transfer supervision.
No task-specific thermal pretraining.
And yet, it transferred.
Link to the post: linkedin.com/feed/update/ur…
English

Now seems like a good time to share that I’ve recently joined @thinkymachines to work on pretraining! Very excited to work on the future of human-AI collaboration with this amazing team.
Thinking Machines@thinkymachines
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way. We share our approach, early results, and a quick look at our model in action. thinkingmachines.ai/blog/interacti…
English
David Jin retweetledi
GeoPT is accepted at ICML 2026 🙌 #ICML2026
Minghao Guo@GuoMh14
Excited to share GeoPT: Scaling Physics Simulation via Lifted Geometric Pre-Training, which received the Best Paper Award at the ICLR 2026 Workshop on Foundation Models for Science. Can we scale neural physics simulation without scaling expensive solver-generated labels? (1/6) (The below results are all predicted by GeoPT.)
English

I am very happy to share that I successfully defended my PhD dissertation!
My deepest thanks to my wonderful advisors, @lexing_ying and @grantrotskoff, and to my committee, Profs. Emmanuel Candès, George Papanicolaou, and Julia Palacios.
Grateful for this milestone and excited for what lies ahead!

English
David Jin retweetledi

Excited to share that ARI (Assured Robot Intelligence) is joining @Meta!
When we co-founded ARI a year ago, the mission was clear: build humanoid intelligence for the real world.
Joining Meta Superintelligence Labs (MSL), we'll continue advancing frontier robotics models toward physical superintelligence in the physical world.
Huge thanks to my co-founders, the incredible ARI team, and our investors led by @aixventureshq for backing this from day one.
This is just the beginning.
Bloomberg@business
Meta Platforms Inc. has acquired Assured Robot Intelligence, a startup developing artificial intelligence models for robots, as part of a major initiative to build humanoid technology. bloomberg.com/news/articles/…
English
David Jin retweetledi

Just had a single-author paper accepted to #RSS2026!
arxiv.org/abs/2604.21456
Motivated by growing interest in differentiable world models and physics simulators, we ask whether there is a unified principle for combining sampling-based global “exploration” with gradient-based local “exploitation” in trajectory and policy optimization with differentiable dynamics.
By viewing control through the control-as-inference lens—recasting optimization as sampling from an unnormalized Boltzmann distribution defined by an energy function—Tempered Sequential Monte Carlo (TSMC) naturally integrates importance sampling with gradient-based Hamiltonian Monte Carlo.
The key idea behind TSMC is to define a tempering path that gradually transforms an easy-to-sample prior into a complex, multi-modal posterior—or equivalently, deforms a convex energy landscape into a nonconvex one (graduated non-convexity)!
We implement TSMC for both trajectory and policy optimization. On small- to medium-scale problems, it appears broadly applicable and compares favorably with state-of-the-art baselines.
Excited to explore whether TSMC can scale to large-scale planning with complex, high-dimensional dynamics!

English
🤯 Scientific pretraining done right!
Minghao Guo@GuoMh14
Excited to share GeoPT: Scaling Physics Simulation via Lifted Geometric Pre-Training, which received the Best Paper Award at the ICLR 2026 Workshop on Foundation Models for Science. Can we scale neural physics simulation without scaling expensive solver-generated labels? (1/6) (The below results are all predicted by GeoPT.)
English

English

@DaviJin @pfau @ziv_ravid Its not. Julia is also pretty good. But I think JAX is optimized for TPUs and TPUs are cheaper than GPUs on cloud.
English

@jaunelia1101 @pfau @ziv_ravid Sorry I was not being clear. I guess I am curious about why it is the only option
English
@DaviJin @pfau @ziv_ravid It has XLA. So you can do quantum mechanics with it which is a lot of linear algebra number crunching.
English

@ziv_ravid It's pretty much the only one you can use for serious scientific computing.
English
David Jin retweetledi

Prompt Learning does not scale for parallel agents.
More parallel agents 🤖 = worse prompts 😭
Why? Processing too many trajectories concurrently damages the prompt update process
🐝 We fix this with Combee :
→ preserves high-quality learnt system prompt
→ scales to more than 80 concurrent agents
→ up to 17× speedup without quality drop on top of ACE and GEPA
🥽Use Cases:
1. Prompt learning on large scale collected agent traces
2. Parallel agent learning online with fast knowledge sharing
Read more below to learn how agents actually learn at scale ⬇️

English
David Jin retweetledi

Code & Video demo: github.com/MikeZheng777/R…
MIT News: news.mit.edu/2026/ai-system…
Paper (JAIR): jair.org/index.php/jair…
English
David Jin retweetledi

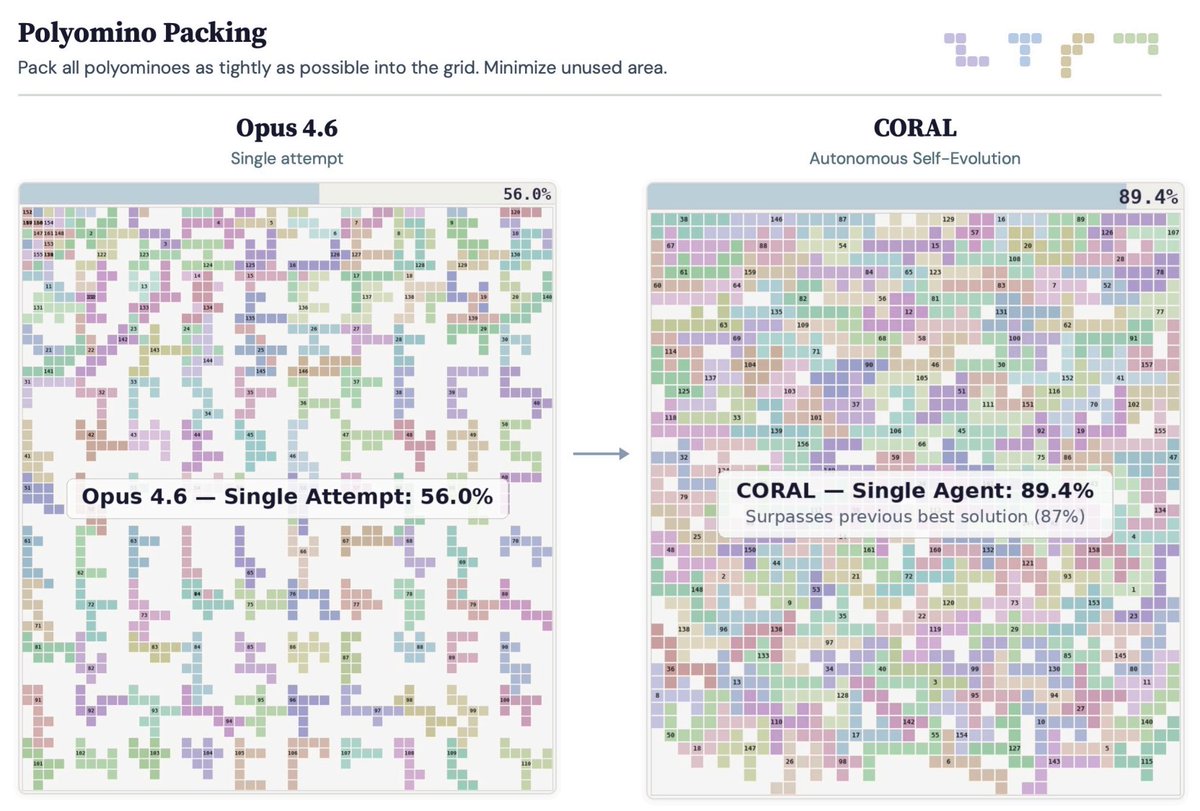
🚀The era of autonomous multi-agent discovery is arriving! @karpathy
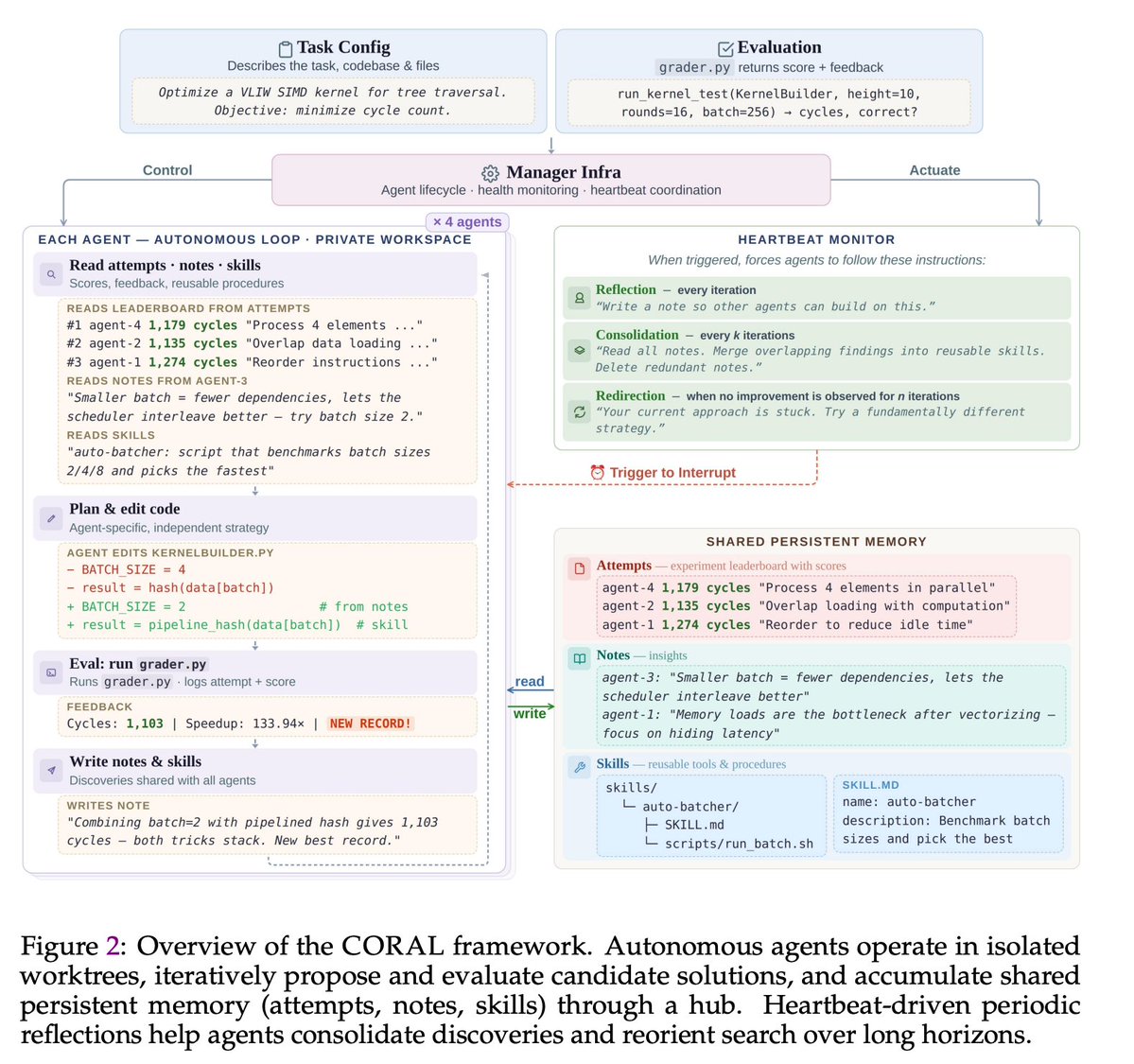
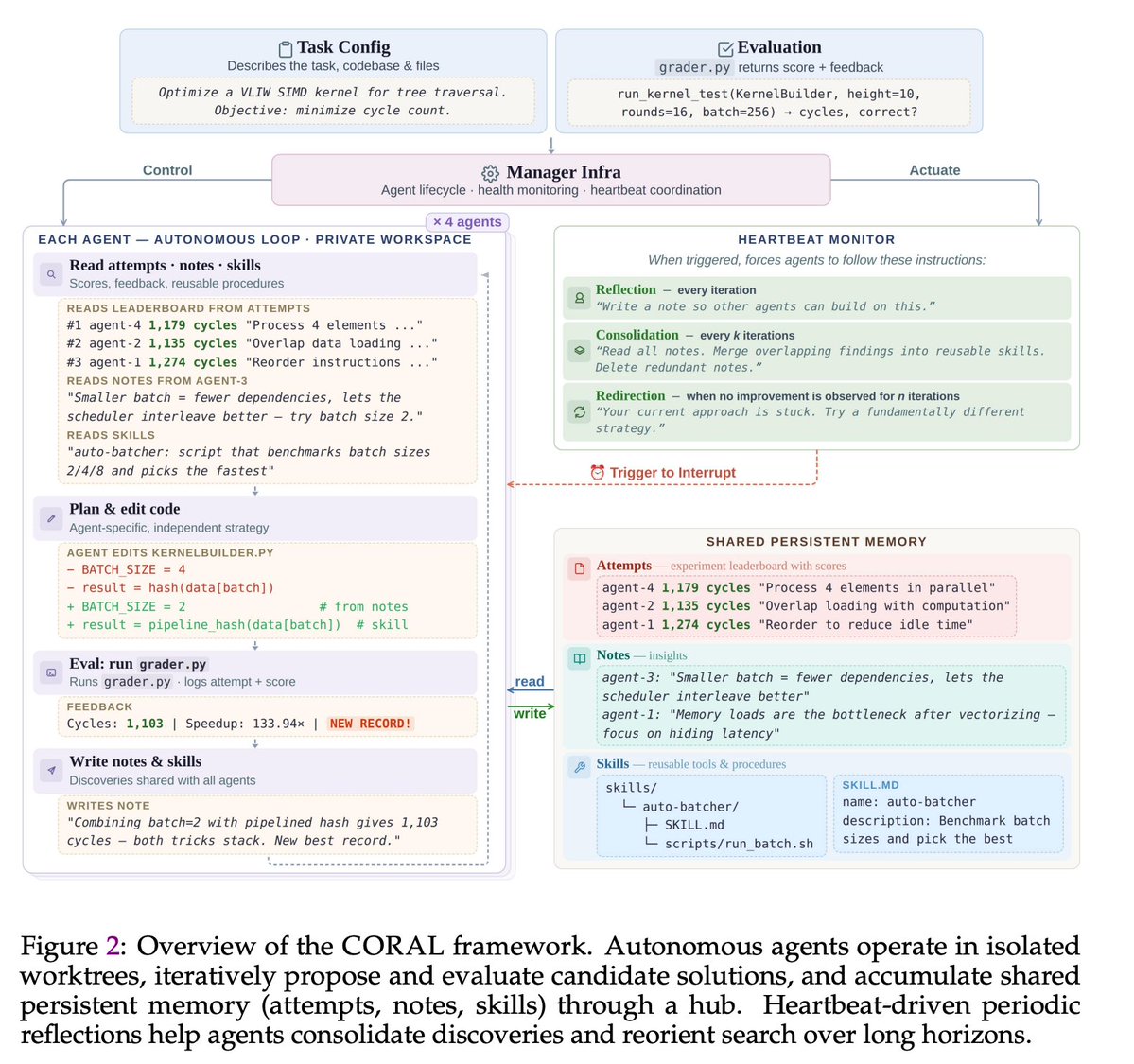
🪸Excited to share CORAL, our new work on autonomous multi-agent systems for open-ended scientific discovery.
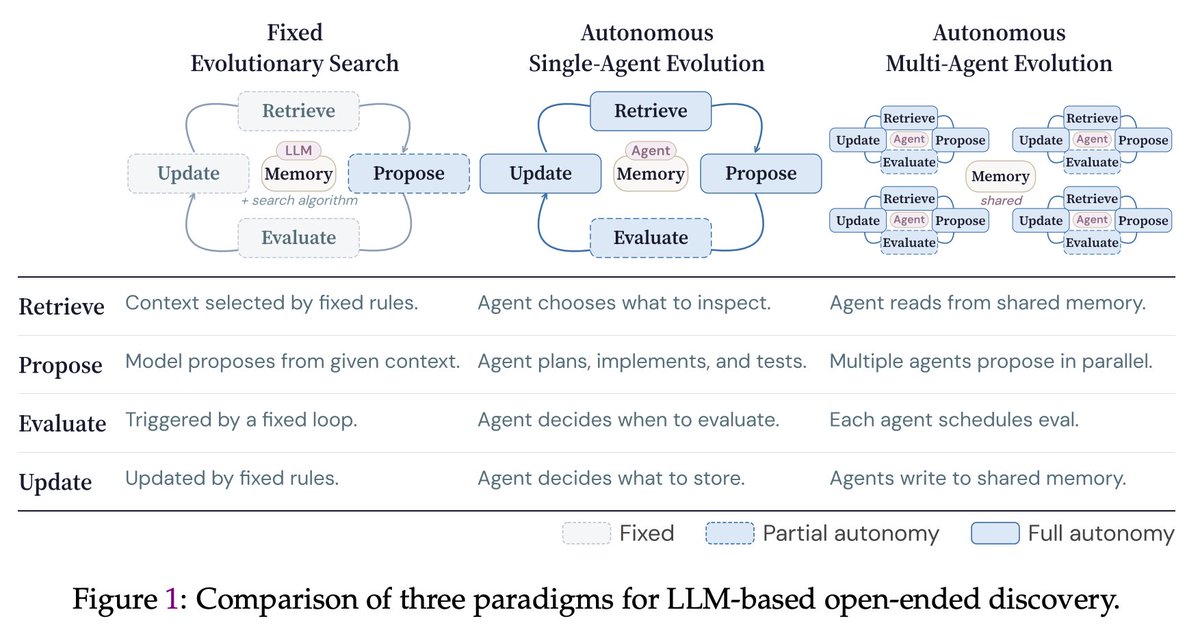
🙅♂️A key limitation of many current “self-evolving” frameworks is that agents still operate inside tightly constrained loops — they mutate solutions, but they do not truly decide how to explore.
In CORAL, we push toward genuine autonomy:
Agents decide
🔍 what to explore
🧠 what knowledge to store
♻️ which ideas to reuse
🧪 when to test hypotheses
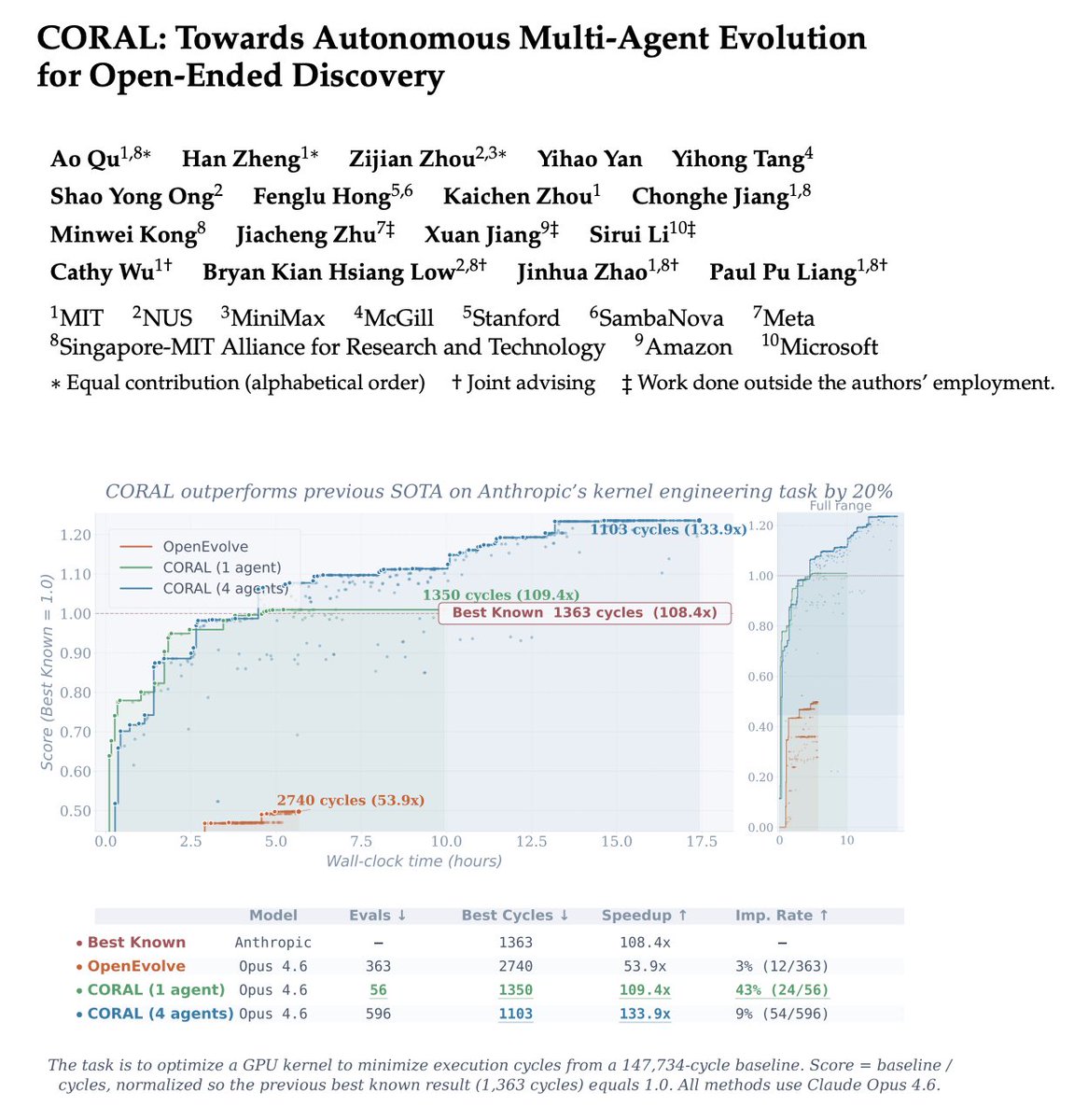
🔥One of the most interesting findings:
A single autonomous agent already outperforms fixed evolutionary search, but the biggest gains emerge when multiple agents form a research community.
💪Over 50% of breakthroughs in multi-agent runs come from building on other agents’ discoveries. This suggests that knowledge reuse and collaboration are central to scalable automated discovery.
🏅Across 10+ difficult tasks in algorithmic discovery and system optimization, CORAL achieves state-of-the-art performance while improving efficiency by 3–10×.
📄 Paper: arxiv.org/abs/2604.01658…
💻 Code: github.com/Human-Agent-So…
💡AlphaXiv: alphaxiv.org/abs/2604.01658
#agentic #llms #selfevolvingagent #multiagent #autoresearch #alphaevolve

English
David Jin retweetledi

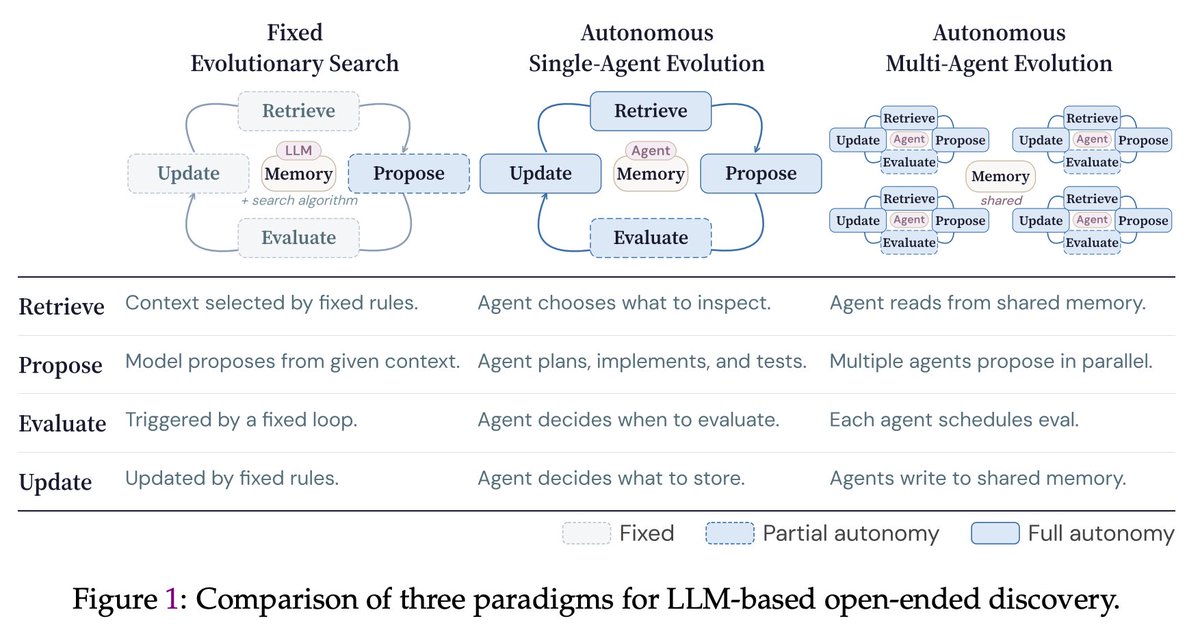
🚀 The era of autonomous multi-agent discovery has begun.
Most “self-evolving” scientific discovery frameworks are still tightly constrained:
LLMs often just perform one-step mutations inside fixed evolutionary search loops.
But that is not real autonomy.
Agents still cannot truly decide:
🔍 what to explore
🧠 what knowledge to store
♻️ which past attempts to reuse
🧪 when to test
With CORAL, we ask:
❓ What happens if we give agents much more autonomy to explore the scientific frontier?
💡 Our answer:
A single autonomous agent already outperforms fixed evolutionary search.
But the bigger leap comes when multiple autonomous agents form a research community:
🤝 They explore different directions
🧠 accumulate reusable knowledge and skills
💬 communicate with each other
🌍 and push the frontier together
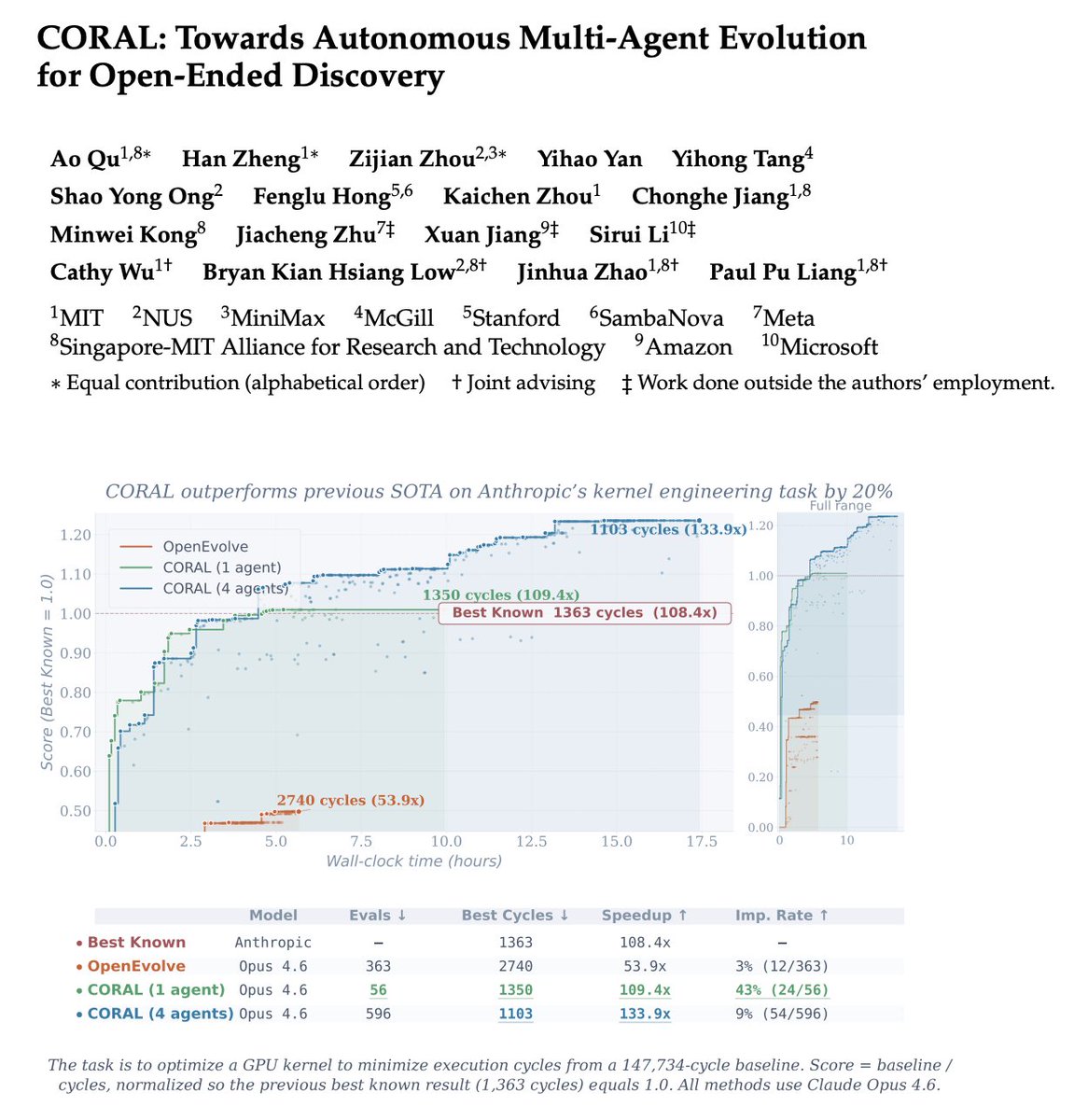
We introduce CORAL, the first framework for autonomous multi-agent evolution for open-ended discovery.
🥇 Across 10+ tasks in algorithmic discovery, system optimization, and kernel engineering from Frontier-CS, ADRS, AlphaEvolve, etc, CORAL achieves SOTA and improves search efficiency by 3–10× over prior fixed evolutionary-search frameworks.
🔬 Why does autonomy help?
Our analysis shows two main reasons:
🧪 Local verification: agents run local tests before expensive evaluations, which is especially powerful for coding tasks.
♻️ Knowledge reuse: on knowledge-intensive tasks like polyominoes and kernel engineering, agents create and reuse knowledge artifacts at far higher rates than on simple tuning/search tasks like circle packing.
✨ Even more exciting:
Over 50% of multi-agent breakthroughs come from building on other agents’ discoveries.
Multi-agent exploration is also far more diverse than single-agent search.
We believe CORAL opens up an exciting new space for automated discovery systems.
📬 If you are interested in collaborating, let’s talk.
📄 Paper: arxiv.org/abs/2604.01658…
💻 Code: github.com/Human-Agent-So…
💡AlphaXiv: alphaxiv.org/abs/2604.01658
#agentic #llms #selfevolvingagent #multiagent #autoresearch #alphaevolve
English
Check out CORAL, a multi-agent framework that evolves more effectively and efficiently than the competition. Go CORAL!
fly51fly@fly51fly
[LG] CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery A Qu, H Zheng, Z Zhou, Y Yan… [MIT & NUS] (2026) arxiv.org/abs/2604.01658
English
@Ji_Ha_Kim Amazing! I was also thinking about rational iteration and had similar result but I did not have a good cholesky implementation. This is impressive!
English

Very cool! I worked on this recently, and I actually used an identical approach early on. But I believe there is a significantly better approach - a **single** minimax rational iteration can beat 5 polynomial steps!

Jack Zhang@jcz42
We made Muon run up to 2x faster for free! Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition. Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangular X matrix, we iterate on the small, square, symmetric XX^T Gram matrix to reduce FLOPs. This allows us to make more use of fast symmetric GEMM kernels on Hopper and Blackwell, halving the FLOPs of each of those GEMMs. Gram Newton-Schulz is a drop-in replacement of Newton-Schulz for your Muon use case: we see validation perplexity preserved within 0.01, and share our (long!) journey stabilizing this algorithm and ensuring that training quality is preserved above all else. This was a super fun project with @noahamsel, @berlinchen, and @tri_dao that spanned theory, numerical analysis, and ML systems! Blog and codebase linked below 🧵
English
David Jin retweetledi

🚀 Linear Attention is unlocking million-token context windows by dropping computational complexity from O(N^2) to O(N), but software is increasingly bottlenecking the hardware.
Meet cuLA (CUDA Linear Attention): hand-written kernels using CuTe DSL & CUTLASS C++ to extract maximum performance on NVIDIA GPUs. A drop-in replacement for FLA designed to push hardware to its absolute limits.
English