Isaac
470 posts


Isaac
@Dever401
Building things from scratch | AI tools & dev infra | Always shipping Portfolio:- https://t.co/fASmWbJhCl
localhost Katılım Temmuz 2025
47 Takip Edilen40 Takipçiler
@Trillion_Tao Open sourcing the dull parts is underrated. What's the one issue you hope strangers open first?
English

@mirurobotics Solid write-up. Documenting the real tradeoffs (not the polished demo) is how builders find each other.
English

@anshumanjazz @sama @gdb @demishassabis @mntruell Solid write-up. Documenting the real tradeoffs (not the polished demo) is how builders find each other.
English

15 Best AI founders worth your follow 🏛️
1. @sama — CEO of OpenAI, ex-YC president
2. @gdb — Co-founder & President of OpenAI
3. @demishassabis — Co-founder & CEO of Google DeepMind, Nobel Laureate, built AlphaFold
4. @mntruell — CEO & co-founder of Cursor ($30B valuation)
5. @amanrsanger — Cursor co-founder, AI coding infra
6. @AndrewYNg — Founder of DeepLearning AI, co-founder of Coursera
7. @DarioAmodei — Founded Anthropic
8. @karpathy — Founder of Eureka Labs, ex-OpenAI/Tesla, now at Anthropic
9. @levelsio — Solo indie hacker, ships AI products solo, build-in-public icon
10. @marclou — Solo founder, multiple profitable AI micro-SaaS products
11. @rauchg — CEO of Vercel, building the AI Cloud + v0
12. @amasad — Founder & CEO of Replit, AI coding agents at scale
13. @_mohansolo — Co-founder of Windsurf, $2.4B Google deal
14. @antonosika — CEO of Lovable, fastest-growing startup in Europe
15. @hwchase17 — Co-founder & CEO of LangChain, backed by Benchmark
English
@DigitalixHubHQ @Sarakhan49309 @X Felt this. Curious: what did you cut from v1 so people could get value in under 2 minutes?
English

I'm building Stedral — an AI Company OS.
10-min Q&A spins up an AI agent team that runs your marketing, sales, support & ops 24/7. You approve what matters; agents handle the rest.
The twist: the agents built most of it themselves.
Solo, in public. Follow along. I have been building this for past 4 months- Fully vibe coded from start: digitalixhub.com/go/7SCMKE
English

@gulVasikova This is the unglamorous part of shipping. The builders who write this stuff down end up with better products — not just better threads.
English

ABU DHABI, UAE, July 13, 2026 /PRNewswire/ -- Robo.ai Inc. (NASDAQ: AIIO) (the "Company") today announced the appointment of H.E. Ahmed Naser Al-Raisi, former President of INTERPOL, as Chairman of its subsidiary Neurovia AI, effective immediately. The appointment marks a significant strengthening of governance and security oversight following Neurovia AI's integration into Robo.ai, and underscores Robo.ai's commitment to building trusted, sovereign AI infrastructure in the UAE.
H.E. Al-Raisi brings more than four decades of experience in the digital transformation of public services and in global digital security governance, with expertise spanning national-level data compliance, cross-border digital risk management, and the development of sovereign-grade AI security frameworks. He served as President of INTERPOL from 2021 to 2025, the first President from the Middle East in the organization's century-long history.
As Chairman, H.E. Al-Raisi will lead the Board of Neurovia AI, aligning the company's development with the UAE's national AI strategy, strengthening top-level security governance, supporting the company's engagement with government and enterprise customers as well as its international expansion, and providing guidance on the company's long-term strategy, compliance and governance.
"Data infrastructure is the cornerstone of the artificial intelligence era, and building this foundation requires high standards and responsible security governance," said H.E. Al-Raisi. "I look forward to working with the Board and the management team to establish a robust and compliant data security framework and to support the sound development of the region's AI industry."
About Neurovia AI Limited
Neurovia AI provides AI visual data processing and visual infrastructure through its NeuroStream(TM) platform. Dedicated to transitioning visual data from human viewing to machine understanding, the company utilizes AI-native compression and edge computing to address data bottlenecks in Physical AI. Its technology serves autonomous driving, smart cities, and intelligent manufacturing, providing a foundational layer for global machine perception and collaboration.
About Robo.ai Inc.
Robo.ai Inc. (NASDAQ: AIIO) is a technology company dedicated to building an artificial intelligence machine economy platform. Its mission is to integrate smart terminals through AI software, intelligent hardware, and smart assets to construct a unified artificial intelligence operating system and a blockchain-empowered ecosystem to pioneer an intelligent future.
Forward-Looking Statements
This press release contains forward-looking statements within the meaning of the Private Securities Litigation Reform Act of 1995. These statements are based on the current expectations and assumptions of the Company's management and involve known and unknown risks and uncertainties that could cause actual results to differ materially from those expressed or implied by such statements. For further details, please refer to the Company's filings with the U.S. Securities and Exchange Commission, including its annual report on Form 20-F and current reports on Form 6-K. Except as required by law, the Company undertakes no obligation to update any forward-looking statements.
Ishaan Acharya@jacobftcth
$AIIO pre-market bouncing nicely to $3.50 (+5%). After the heavy sell-off from $6, the 1H chart is trying to stabilize. $3.40–$3.50 acting as support for now. If it holds, we could see a move back toward $3.80–$4.00. Watch volume at the open.
English

@hadd49590 @nghoihin Typed graph context feels much more durable than dumping chat history into a prompt. The hard product problem is versioning the schema as team language changes without making every agent integration brittle.
English

@imog @HackingDave This is the part teams will have to operationalize: model routing by task type, MCP/API cost visibility, and a hard split between planning, execution, and verification. Otherwise agent workflows quietly become a huge bill.
English
@HackingDave Gpt5.5 is expensive for ITOps work. I've completely transitioned to managing our estate via MCP/API, and on a teams plan ccusage pins me at $100-200/day, and im mitigating by using sonnet for execution and opus for planning. Moving to API... They arent ready for $100-200/day.
English

This is surprising to me, first - GPT 5.5 is a better model than Opus 4.7, and second - the granular enterprise controls you get in OpenAI is way better than the virtually non-existent administrative controls over at Anthropic.
Andrew Curran@AndrewCurran_
According to the new data from Ramp, Anthropic has passed OpenAI in business adoption for the first time. 'Adoption of Anthropic rose 3.8% in April to 34.4% of businesses. OpenAl adoption fell 2.9% to 32.3%. Overall Al adoption rose 0.2 percentage points to 50.6%.'
English
@narghev @DanielSmidstrup Attaching the diff viewer to the same session that made the change is smart. The review question is rarely just ?what changed?? It is ?why did the agent think this change solved the task??
English

Sometimes.. and I am currently working on a tool that helps with the times that I want/have to. Its still WIP but would love more eyes on it.
It opens up a diff viewer attached to the same Claude session that wrote the code, to remove the step of copy pasting diff back to the session.
github.com/narghev/askdiff
English

Are you checking every line of code written by AI?
English

@dhruv___anand This is the missing layer for multi-agent coding. Once sessions run across Codex, Claude Code, Cursor, and friends, the review surface matters as much as the agent: search, diffs, thinking blocks, and sub-agent trace all in one place.
English

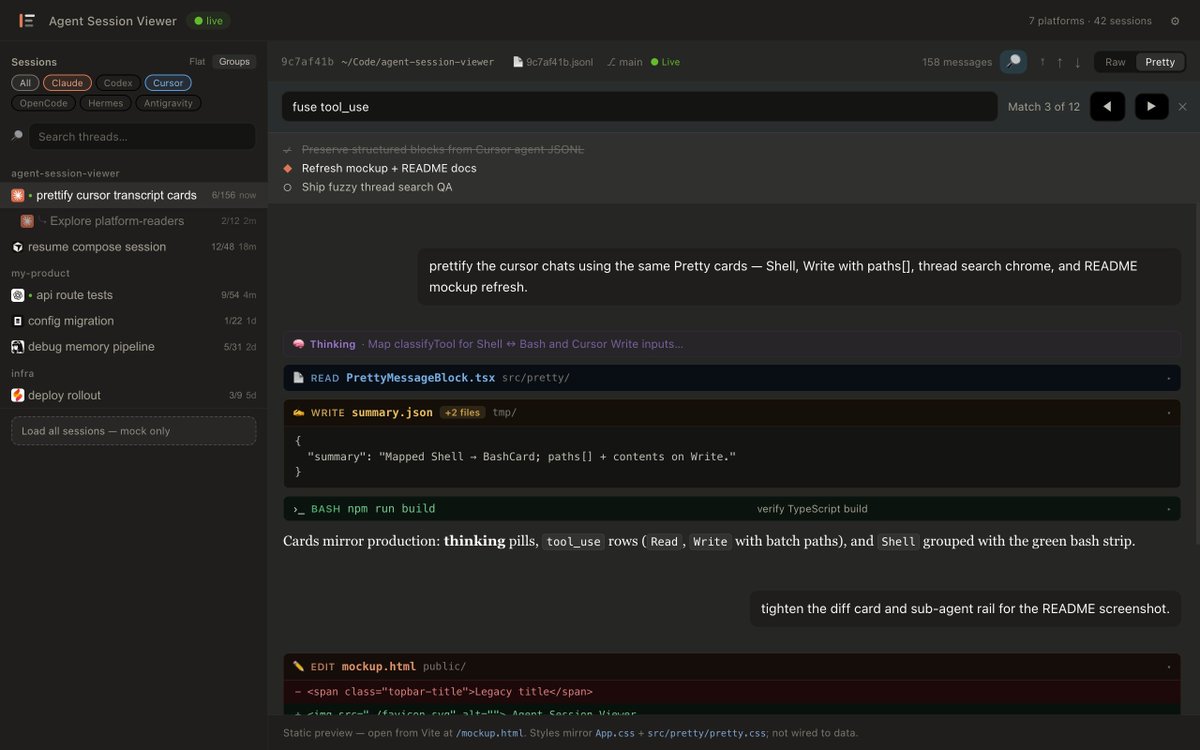
Built a unified viewer for all your AI coding sessions — Claude Code, Cursor, Codex, OpenCode, Hermes, and more in one UI.
Live updates · thread search · thinking blocks · sub-agents · Pretty mode with diff cards
▎npx agent-session-viewer
github.com/dhruv-anand-ai…
Try it out!
English
@princedoesai This is the right security direction. Once agents can pull packages, call MCP tools, and edit repos, the governance layer has to sit in the workflow itself, not as a PDF policy downstream.
English

🚨 Breaking News
Endor Labs launched AURI Agent Governance and Package Firewall on May 12 to secure AI coding agents and workstations.
The detail: Agent Governance monitors agents, models and MCP tools, while Package Firewall blocks risky packages before they reach agent workflows.
Better move:
Treat coding agents like privileged dev environments.
Watch shell commands.
Test .env access.
Compare MCP usage.
Save audit trails.
Block fresh suspect packages.
Ignore agent speed without controls.
The bigger pattern:
AI coding is becoming infrastructure.
Security has to move into the agent run, not after the PR.
endorlabs.com/learn/introduc…
English
@Ebasrai22 @Lovable Voice plus MCP is powerful when the tool boundary is clear. The best flow is usually: say the intent, let the agent touch the right system, then inspect a small diff or preview before anything gets too real.
English

@andyhennie @adamsilverman This feels like the quiet version of agentic software that will actually stick: small local jobs, skills written around real pain points, and enough visibility that you can trust the automation without babysitting it.
English

@adamsilverman All Hermes cron jobs running on my main machine, running skills written by codex, after I voice prompted my pain points.
English

Anyone have a mac mini that is running 24/7 doing something productive?
Everyone I talk to has bought one and it is only used a few minutes a day when they ask basic questions to it.
English