Eddie
1.6K posts


Eddie
@Edouardmazza
Making life easier, one task at a time



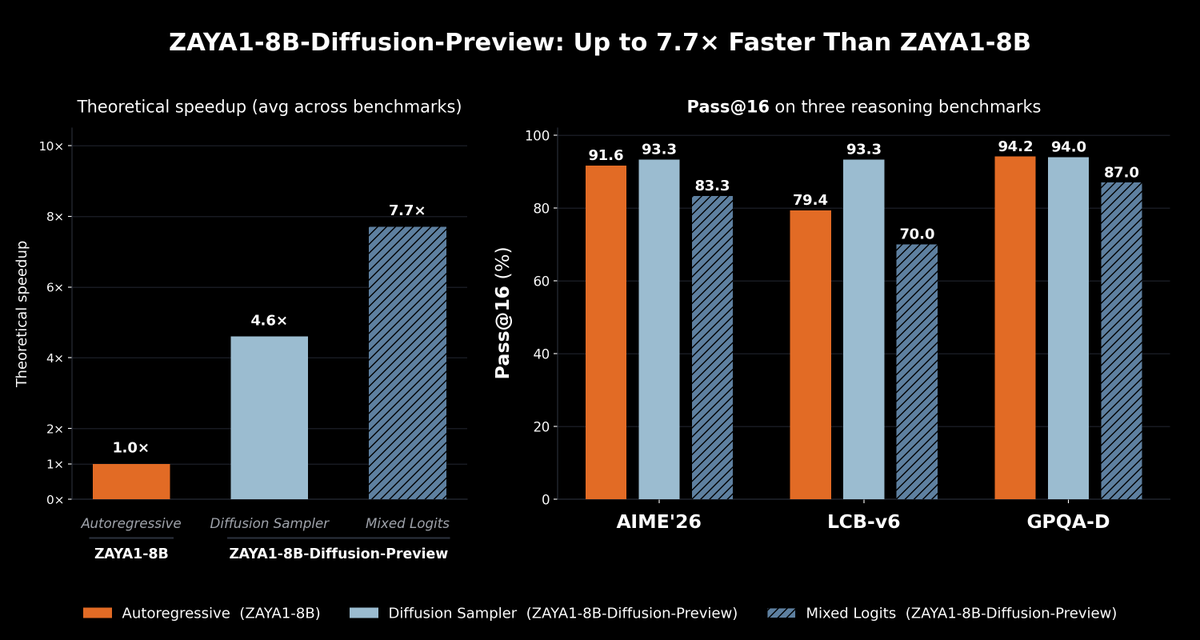
We present ZAYA1-8B-Diffusion-Preview, the first diffusion language model trained on @AMD. Autoregressive LLMs generate one token at a time; diffusion generates a block in parallel, speeding up inference. We show a 4.6-7.7x decoding speedup with minimal quality degradation 🧵






google book - a new AI ultrabook coming soon. hopefully it will be cheaper than MacBook Neo







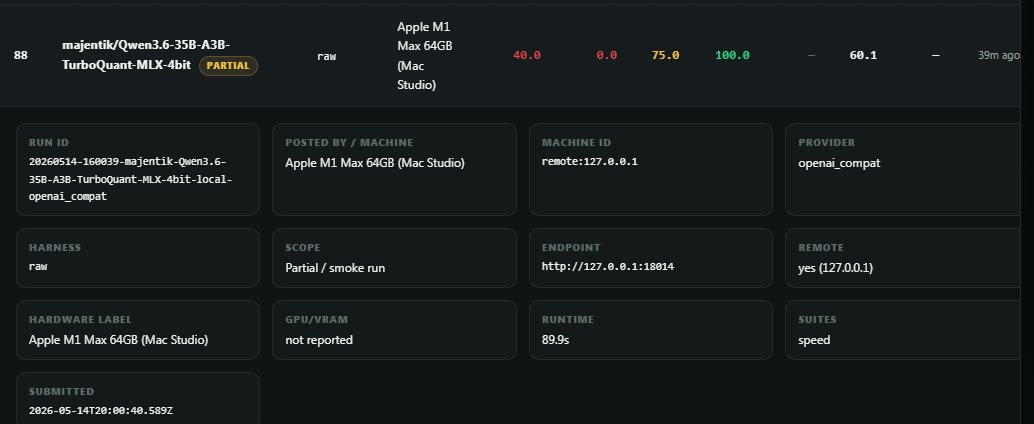
Two open-source MLX inference servers worth knowing about if you run LLMs on Mac: MTPLX (@youssofal) Uses a model's own MTP heads for speculative decoding. No draft model needed. ~63 tok/s on Qwen3.6-27B (M5Max). Mathematically exact sampling too; not just greedy prefix matching. oMLX (@jundot) Tiered KV cache that persists to SSD across restarts. Huge for coding agents where you're sending the same codebase context repeatedly. Also serves LLMs, VLMs, embeddings, rerankers, and audio simultaneously. They're solving different problems; MTPLX maximizes tok/s, oMLX maximizes workflow efficiency. Both have OpenAI + Anthropic-compatible APIs, both work with Claude Code/OpenCode/Cursor out of the box. Running both depending on the task. But, both worth checking out.

