
AI Company eco-system is growing fast
Polsia: @polsia
Paperclip: paperclip.ing
Nanocorp: nanocorp.so
ZHC: zhc.company
What else am I missing?
English
Eisuke/叡佑
252 posts

@EisukeHirata
Exploring Human x AI | Solopreneur | Made in 🇯🇵 @eisuke_hrt






















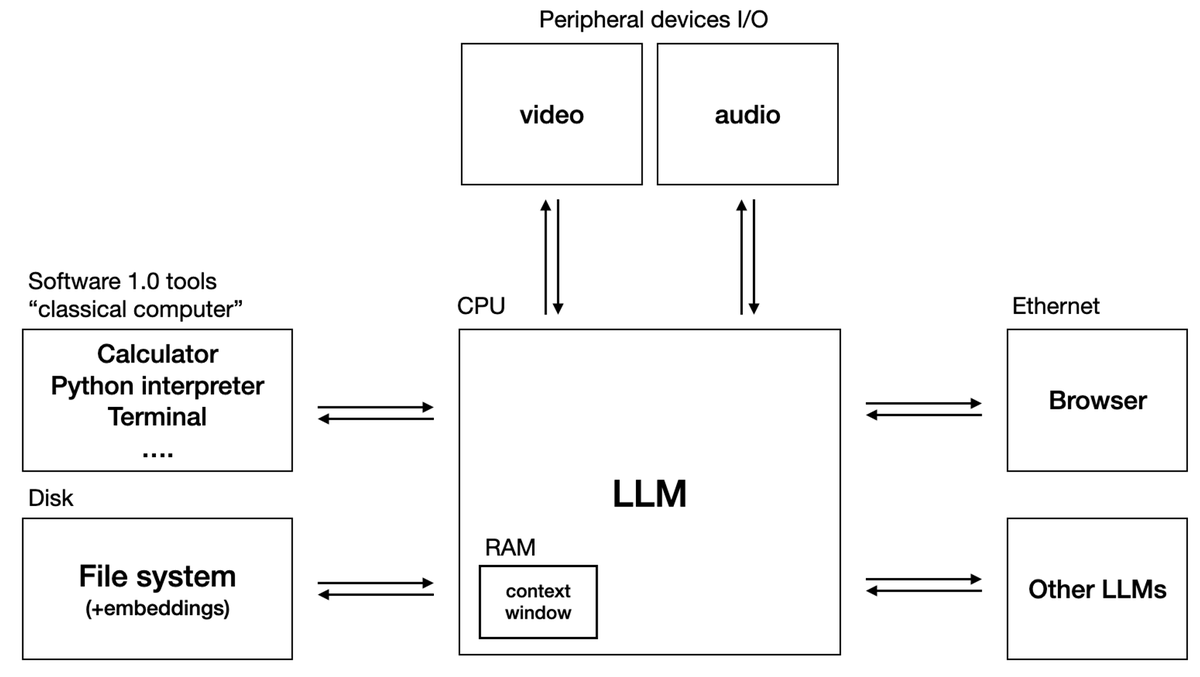



AI builders, #hivemind survey time! What are your current favorite go-to libraries and frameworks for your AI projects? The ones you couldn’t live without! Add name, short desc, and why below. 👇 Will summarize first 100~200 replies into an article ✍️

