

Emily Capstick retweetledi

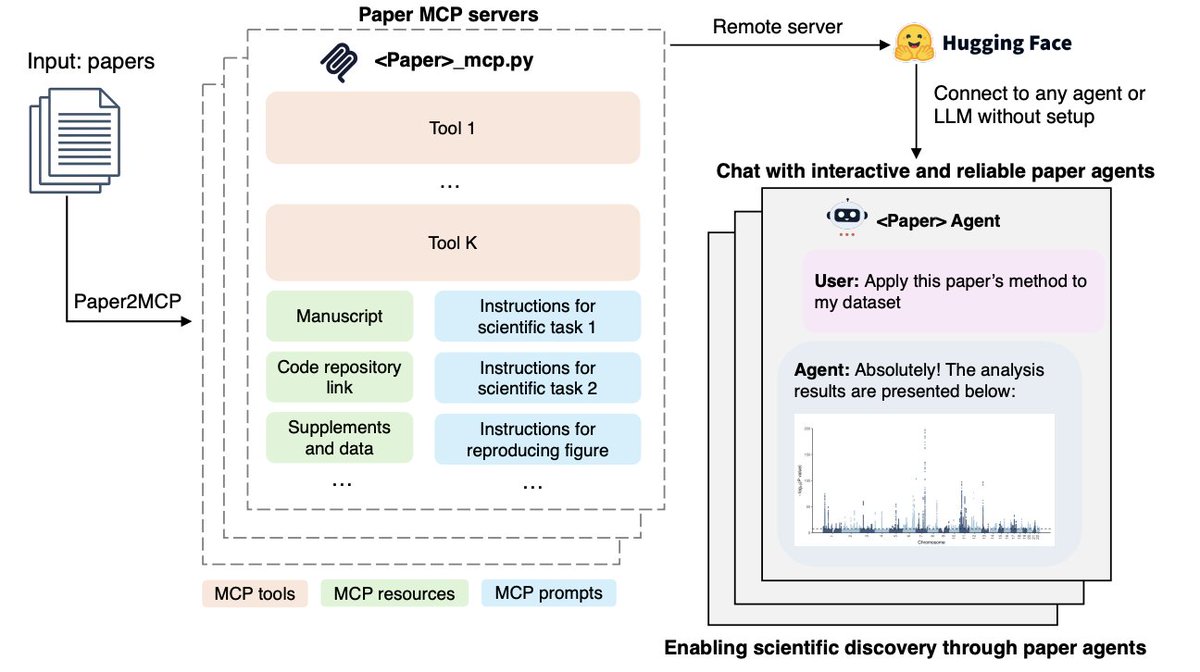
Holy shit...Stanford just built a system that converts research papers into working AI agents.
It’s called Paper2Agent, and it literally:
• Recreates the method in the paper
• Applies it to your own dataset
• Answers questions like the author
This changes how we do science forever.
Let me explain ↓
English



























