Sabitlenmiş Tweet
@egmmx@threads/@𝗲𝘀𝘁𝗲𝗯𝗮𝗻@mastodon 🇺🇦
45.6K posts


@egmmx@threads/@𝗲𝘀𝘁𝗲𝗯𝗮𝗻@mastodon 🇺🇦
@esteban
エステバン – | Software Engineer at @lancedb. HBase Committer, ex-{Datahub, @redpandadata, @Cloudera, @SismologicoMX,@cires_ac,@GobCDMX}. Swim dad. All views mine.
Austin, TX Katılım Nisan 2007
4.9K Takip Edilen2.5K Takipçiler
Honestly people don’t appreciate this but coding agents such as Claude Code are really good with UML and C4.
English
This is a very primitive version of team of rivals paper from @acmurthy but this approach has proven to be quite reliable with the right consensus protocol. Over the last few weeks I’ve been pushing it to the limit and models such as Opus 4.6 can exploit its capabilities.
ᴅᴀɴɪᴇʟ ᴍɪᴇssʟᴇʀ 🛡️@DanielMiessler
Another feature we have in PAI is a /council skill. Problem: You want expert opinions but don't have access to them. /council creates multiple, relevant agent experts on the topic and HAS THEM DEBATE across multiple rounds and return the results to the thread.
English
@egmmx@threads/@𝗲𝘀𝘁𝗲𝗯𝗮𝗻@mastodon 🇺🇦 retweetledi

Restroom breaks are going to be very long now. 🤣
Boris Cherny@bcherny
🤯 You can now launch Claude Code sessions on your laptop *from your phone* This blew my mind the first time I tried it
English
@bcherny Thank you! weekends are the most productive to explore for me!
English

Quick thank you to everyone who's been building with Claude Code, both the early crowd and everyone who showed up this year. It’s only thanks to your feedback that we can make the product a little better every day.
English
@egmmx@threads/@𝗲𝘀𝘁𝗲𝗯𝗮𝗻@mastodon 🇺🇦 retweetledi
We doubled Claude usage on weekends, and outside 5–11am PT on weekdays for the next 2 weeks.
Claude@claudeai
A small thank you to everyone using Claude: We’re doubling usage outside our peak hours for the next two weeks.
English
@karpathy “small flowers crack concrete” – Sonic Youth.
English

I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
github.com/karpathy/autor…
Part code, part sci-fi, and a pinch of psychosis :)

English
@egmmx@threads/@𝗲𝘀𝘁𝗲𝗯𝗮𝗻@mastodon 🇺🇦 retweetledi

Karpathy just open-sourced autoresearch.
One GPU. 100 ML experiments. Overnight. You never touch the code — just write a Markdown file.
The bottleneck isn't compute. It's your program.md.
gli.st/z3iakp3f
English
Few months ago I was ignored when I said that we should prepare for agentic scale, @levie is right, this is the future we have to build, I hope his voice and leadership in the enterprise are heard. The firehose is here and unstoppable.
Aaron Levie@levie
English
English

I'm still on the fence on Codex vs Claude Code.
But one thing Codex does significantly better is context compaction.
With Codex, I can mostly continue working after compaction.
With Claude Code, I often had to toss out the chat and start a new one.
English
@egmmx@threads/@𝗲𝘀𝘁𝗲𝗯𝗮𝗻@mastodon 🇺🇦 retweetledi
🎶 I've been using voice mode to write much of my CLI code this last week
Can't wait to hear what you think.
Thariq@trq212
Voice mode is rolling out now in Claude Code. It’s live for ~5% of users today, and will be ramping through the coming weeks. You'll see a note on the welcome screen once you have access. /voice to toggle it on!
English
@egmmx@threads/@𝗲𝘀𝘁𝗲𝗯𝗮𝗻@mastodon 🇺🇦 retweetledi

what watching anthropic vs. the department of war feels like
English
@bcherny 👋🏻 got some ideas for y’all besides github is there like a suggestion box? or DM? thanks!
English
Thank you for fixing it. It was truly driving me crazy.
English
@KUTX the RDS system in the FM has been awfully delayed or completely of by 2 songs. 😞
English
@luisdans You can reasonable do compliance investigation with Claude. +1 legal is on the top of that list.
English

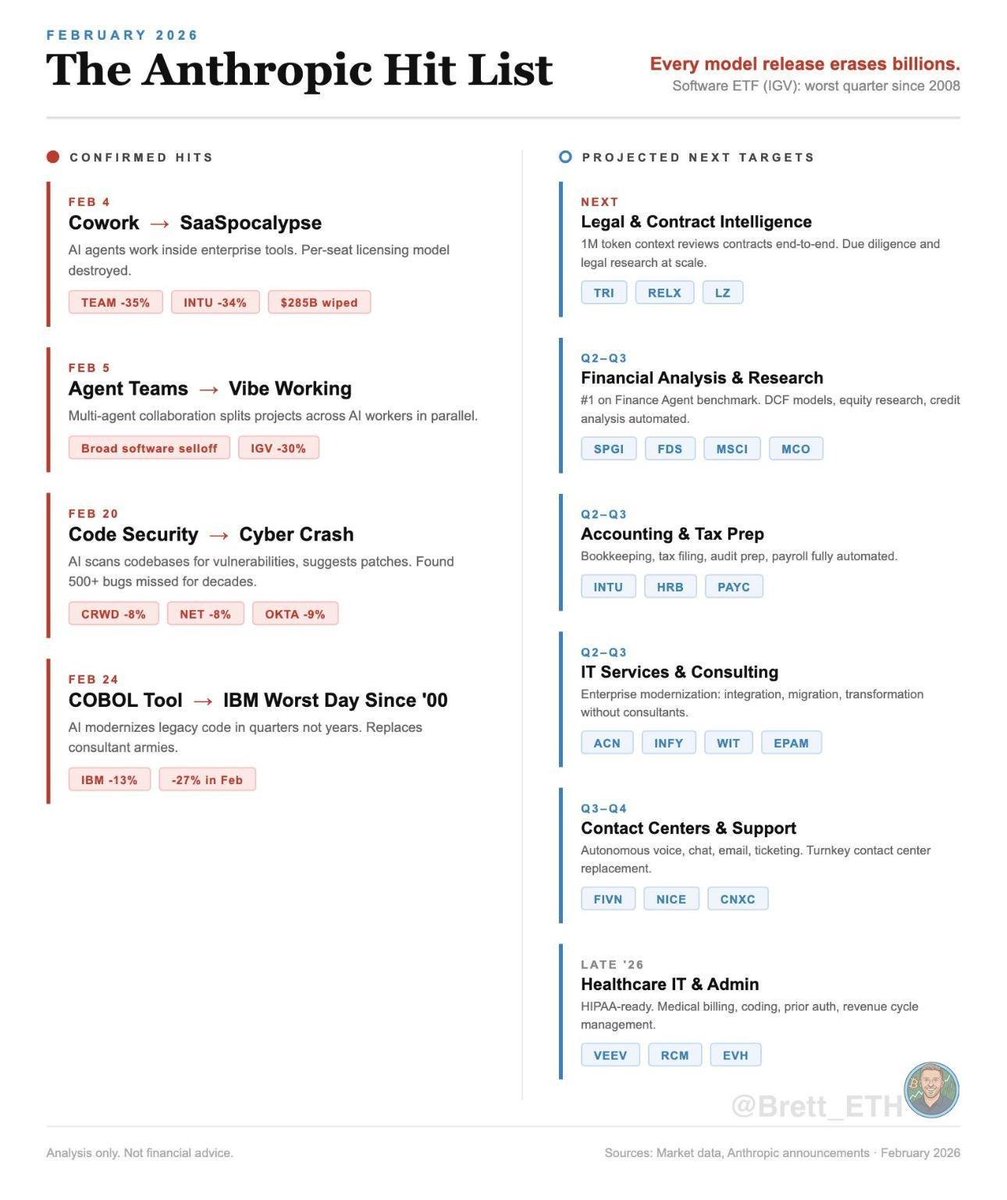
@egmmx@threads/@𝗲𝘀𝘁𝗲𝗯𝗮𝗻@mastodon 🇺🇦 retweetledi

We just posted a paper solving Erdos #846, which was solved by an internal model at OpenAI (cdn.openai.com/infinite-sets/…). While the problem can also be derived from an earlier paper in the literature, the proof by the internal model was one of the first instances where I smiled reading the proof.
English