Sabitlenmiş Tweet

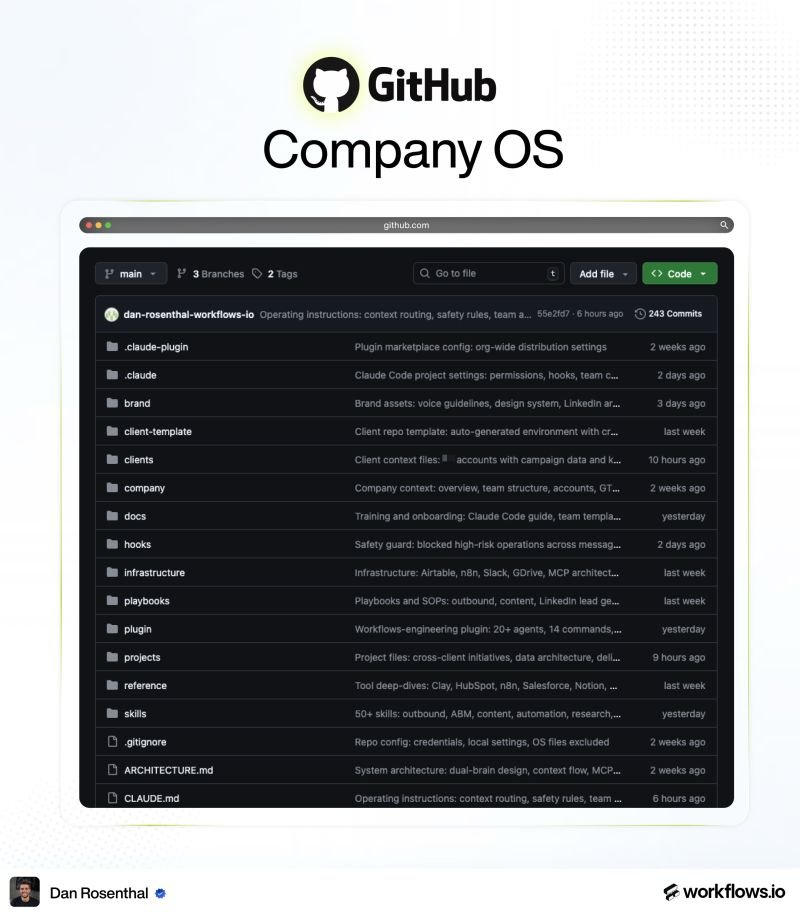
At Archimedes we push AI code generation to the daily limit — dozens of parallel Claude sessions across the team, real production modules. At that scale you hit a wall nobody talks about.
Here's what we found and what we built 👇
English