@trondw @NotebookLM @GoogleLabs Oh btw, roadmap request: NotebookLM MCP or CLI tool so I can wire up my Hermes agent to my saved YouTube, aggregate in NotebookLM, and then push into my PKM system
English
Grant Gochnauer
13.6K posts

@GrantGochnauer
Dad, Co-Founder & CTO at @Vodori, Engineer, Builder, Geek, Guitar, Music, LGBT, Philanthropy, ESTJ. Relentlessly Curious.


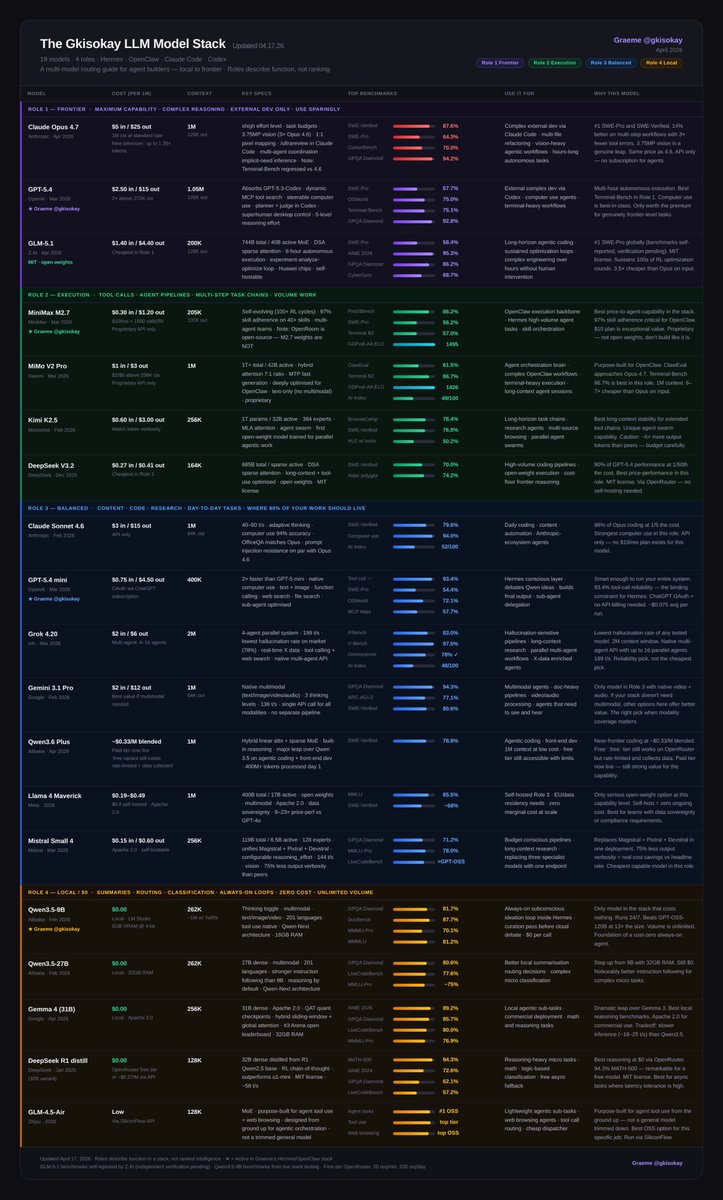
The LLM Cheat-Sheet for Hermes + OpenClaw Agents (04.12.26) The community has flagged Claude Opus 4.6 underperforming lately while GLM 5.1 has exploded on the scene to claim frontier capabilities. A lot has changed since the last version. Here's what moved: GLM-5.1 just proved its frontier capabilities with #1 SWE-Pro globally, 8-hour autonomous execution, and cheaper than Opus on input. It earns a Tier 1 spot. Grok 4.20 enters Tier 2 with the lowest hallucination rate of any tested model, a native multi-agent API running up to 16 parallel agents, and a 2M context window. Gemini 3.1 Pro drops to Tier 3. The price and multimodal story is strong, but the new frontier bar left it behind on reasoning. Mistral Small 4 joins Tier 3. One model replacing three specialist pipelines (reasoning, vision, agentic coding) at $0.15/M input. Apache 2.0. Here's the full landscape: 18 models in 4 tiers. Tier 1 - Frontier Models - Claude Opus 4.6: #1 agentic terminal coding; watch for inconsistency reports - GPT-5.4: superhuman computer use, real planning. and introduced a $100/month plan - GLM-5.1: #1 SWE-Pro globally, 8-hour autonomous execution, MIT license Tier 2 - Execution - MiniMax M2.7: 97% skill adherence, built for agents. API only, not open weights - Kimi K2.5: long-horizon stability, agent swarm - Grok 4.20: lowest hallucination rate on the market, native multi-agent, 2M context - DeepSeek V3.2: frontier reasoning at 1/50th the cost Tier 3 - Balanced - Claude Sonnet 4.6: 98% of Opus at 1/5 the cost - GPT-5.4 mini: 93.4% tool-call reliability, runs on OAuth - Gemini 3.1 Pro: best multimodal value, native video+audio in one call - Qwen3.6 Plus: near-frontier coding, completely free via OpenRouter - Llama 4 Maverick: open-weight, self-host at zero marginal cost - Mistral Small 4: one model replacing three; reasoning, vision, agentic coding, Apache 2.0 Tier 4 - Local / $0 - Runs on 32GB RAM or less - Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size - Qwen3.5-27B: stronger instruction following, 32GB RAM - Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready - DeepSeek R1 distill: best chain-of-thought at $0 - GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model Full breakdown with benchmarks, costs, and use cases in the table ↓