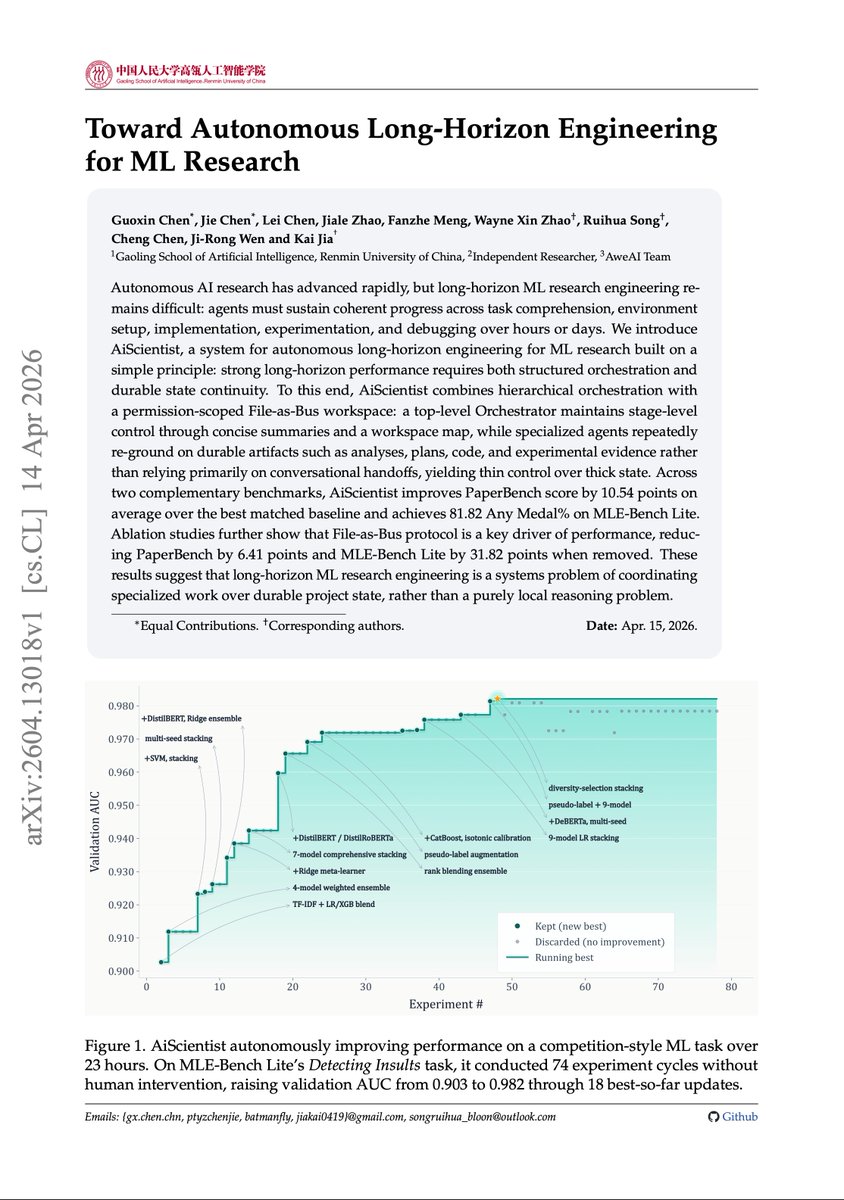
Long-horizon AI research agents are mostly a state-management problem. It is not enough for an agent to reason well in the next turn. ML research requires task setup, implementation, experiments, debugging, and evidence tracking over hours or days. This new paper introduces AiScientist, a system for autonomous long-horizon engineering for ML research. The key idea is to keep control thin and state thick. A top-level orchestrator manages stage-level progress, while specialized agents repeatedly ground themselves in durable workspace artifacts: analyses, plans, code, logs, and experimental evidence. That "File-as-Bus" design matters. AiScientist improves PaperBench by 10.54 points over the best matched baseline and reaches 81.82 Any Medal% on MLE-Bench Lite. Removing File-as-Bus drops PaperBench by 6.41 points and MLE-Bench Lite by 31.82 points. Why does it matter? Autonomous research agents need durable project memory, not just longer chats. Paper: arxiv.org/abs/2604.13018 Learn to build effective AI agents in our academy: academy.dair.ai