Dan Shipper 📧@danshipper
BREAKING:
Proof—a new product from @every
It’s a live collaborative document editor where humans and AI agents work together in the same doc. It's fast, free, and open source—available now at proofeditor.ai.
It’s built from the ground up for the kinds of documents agents are increasingly writing: bug reports, PRDs, implementation plans, research briefs, copy audits, strategy docs, memos, and proposals.
Why Proof?
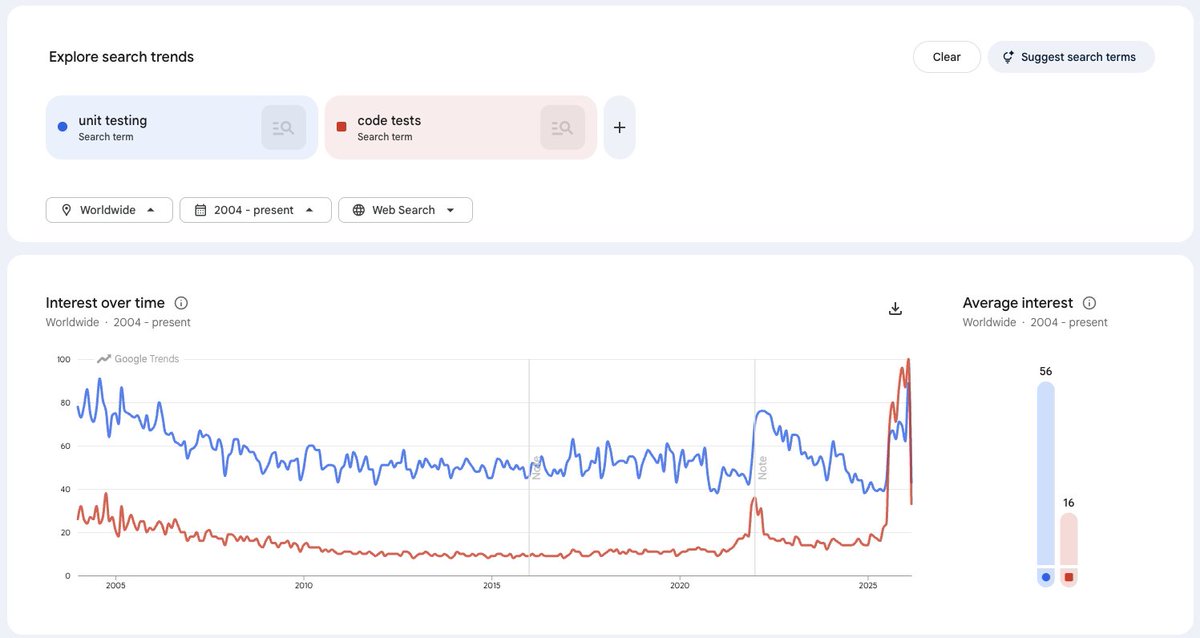
When everyone on your team is working with agents, there's suddenly a ton of AI-generated text flying around—planning docs, strategy memos, session recaps. But the current process for collaborating and iterating on agent-generated writing is…weirdly primitive.
It mostly takes place in Markdown files on your laptop, which makes it reminiscent of document editing in 1999.
Proof lets you leave .md files behind.
What makes Proof different?
- Proof is agent-native: Anything you can do in Proof, your agent can do just as easily.
- Proof tracks provenance: A colored rail on the left side of every document tracks who wrote what. Green means human, Purple means AI.
- Proof is login-free and open source: This is because we want Proof to be your agent's favorite document editor.
Check it out now, for free—no login required:
proofeditor.ai