Sabitlenmiş Tweet

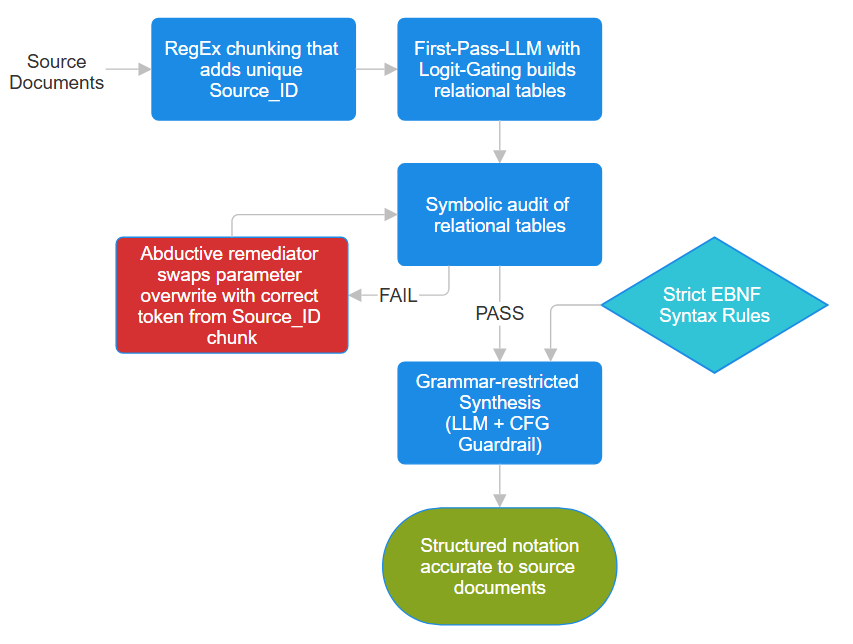
Built MedEvidence on one promise: zero fabricated PubMed citations.
Today I ran it through 30 clinical cases.
Here's what I found 👇
English
Ilya Babashin
210 posts

@ILYA_babay
Building MedEvidence — PubMed AI for clinicians.Every citation real & verifiable. No hallucinations.Backend eng.Building in public. https://t.co/ohkssWvvtU

















Just saw a comment that said “I’m a student. Can someone tell me an alternative to ChatGPT?” HELLO??? YOUR BRAIN?????? the fuck?????????