
JaMarco
9.5K posts

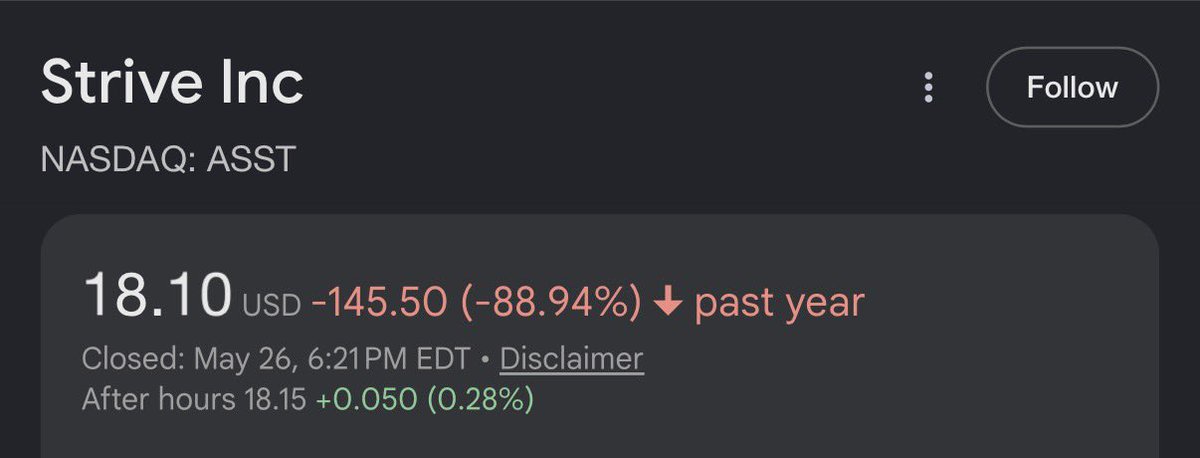

Bitcoin treasury companies just keep stacking. Strive hits 16,500 BTC — now the 7th largest publicly traded holder. The playbook Michael Saylor wrote is now an industry. Sound money wins.
English

internet-computer:native and filecoin:native are pumping together again. You know what this means. Unfortunately.
English


@rahmbotrades "No one on the current operating team has previously run a data center business"
what about this guy? linkedin.com/in/stefan-kasa…
English


No one talks about how expensive AI video creation is.
God 😭😭
English
@mikealfred When are you going to report this person for insider trading?
English

Someone big is walking CIFR up in the overnight market again. Whoever this is never seems to miss. Big week likely.
English


I'm not convinced that DeepMind ever actually figured out how reasoning works. The models have been useless since they introduced it.
English

@JKeynesAlpha I saw some of these robots in Miami. Man were they clunky. Couldn't move in a straight line. And seemingly not very "smart". I know it's early but I wasn't very impressed
English



This 4 minute video may change your life.
We figured out how to use AI to make you wealthier.
The more you use Silvia, the faster your net worth grows.
Try it: cfosilvia.com
English
English

@JaMarc0 @Sam_Badawi He has huge tech short as of 3/31 and took a bath on unity software and snowflake holdings. Sold AMD before exploded higher and too many holdings to begin with. He’s a clown
English

Gavin Baker built a massive position in $ALAB around the AI infrastructure theme, and the stock has now crossed $300. He thinks AI is different and that we are NOT in a bubble.
He expresses this thesis behind many of his top holdings, including $NVDA, $MU, and $AMZN.

English
@Iseeghostsl @CaniacBombs but I thought firing terrible Cora was going to fix everything?
English


@NickCRadio wait a minute, I thought Cora was the reason they were bad?
English

This Red Sox team is unbearable to watch. I've seen enough. They're going nowhere. Here's the checklist:
- Fire Breslow
- Try to get Theo to run the deadline. If not, Romero.
- Sell at the deadline
- Name a new GM who knows what he's doing
- Let that GM hire the next manager
English


@APompliano “Rich people are flocking to it”. Ridiculous statement.
English

@andrewdfeldman Unfortunately it costs more to produce and run than it generates in ROI.
English

When the chip on your shoulder is the largest chip the world has ever seen.

English
@seunosewa So when K20 comes out (and its closed source) this will still be viable?
English

@JaMarc0 You can just keep training your trained model. Cursor is based on Kimi K2.5. When Kiki K2.6 came out, Cursor didn't start over. They just kept improving their fork.
English
Cursor Composer 2.5:
1. Proves that you don't need to train a model from scratch. Best to take a good open source model and just keep training it more and more.
2. Is a big problem for the frontier AI companies. Cursor has the best UX for AI coding and now it's the most economical. People are starting to notice.
3. What looks good: a) $20 claude-pro/chatgpt-plus with $60 cursor. b) Just cursor. $20, $60, $200, since Cursor also provides frontier models.
English
@P_Sharkenstein @OWHistory Really? Shutting down or going to another chain?
English

@OWHistory something to do with odin fun, they may be leaving icp🤔
English
‼️‼️‼️ WTF IS GOING ON WITH #ckBTC supply ??? It dropped sharply? Chain fusion is a failure or what ???
internet-computer:native
English

$GLXY has got to spin off its power assets ASAP
Cc @novogratz
ChelApples@ChelApples
@RHouseResearch @NicolasFlamelX Hmm, inaugural thesis of $GLXY for new account seems to have failed, forcing a pivot to promoting the "phony, promotional" tickers with a documented history of grift that prior account used to dump all over, but now pumps... How to reconcile? Btw "500% in a month" or year? 🥸
English