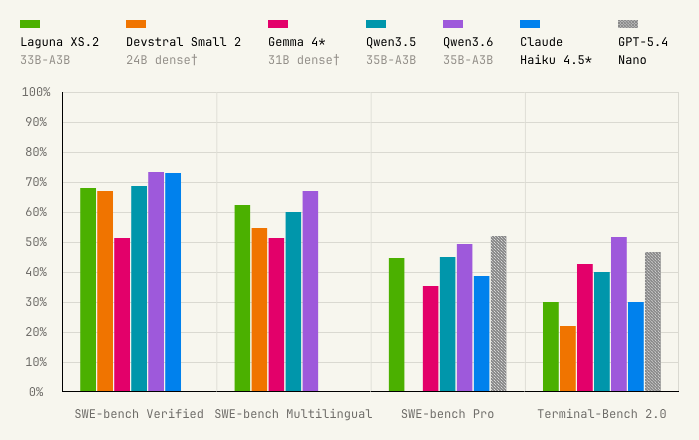
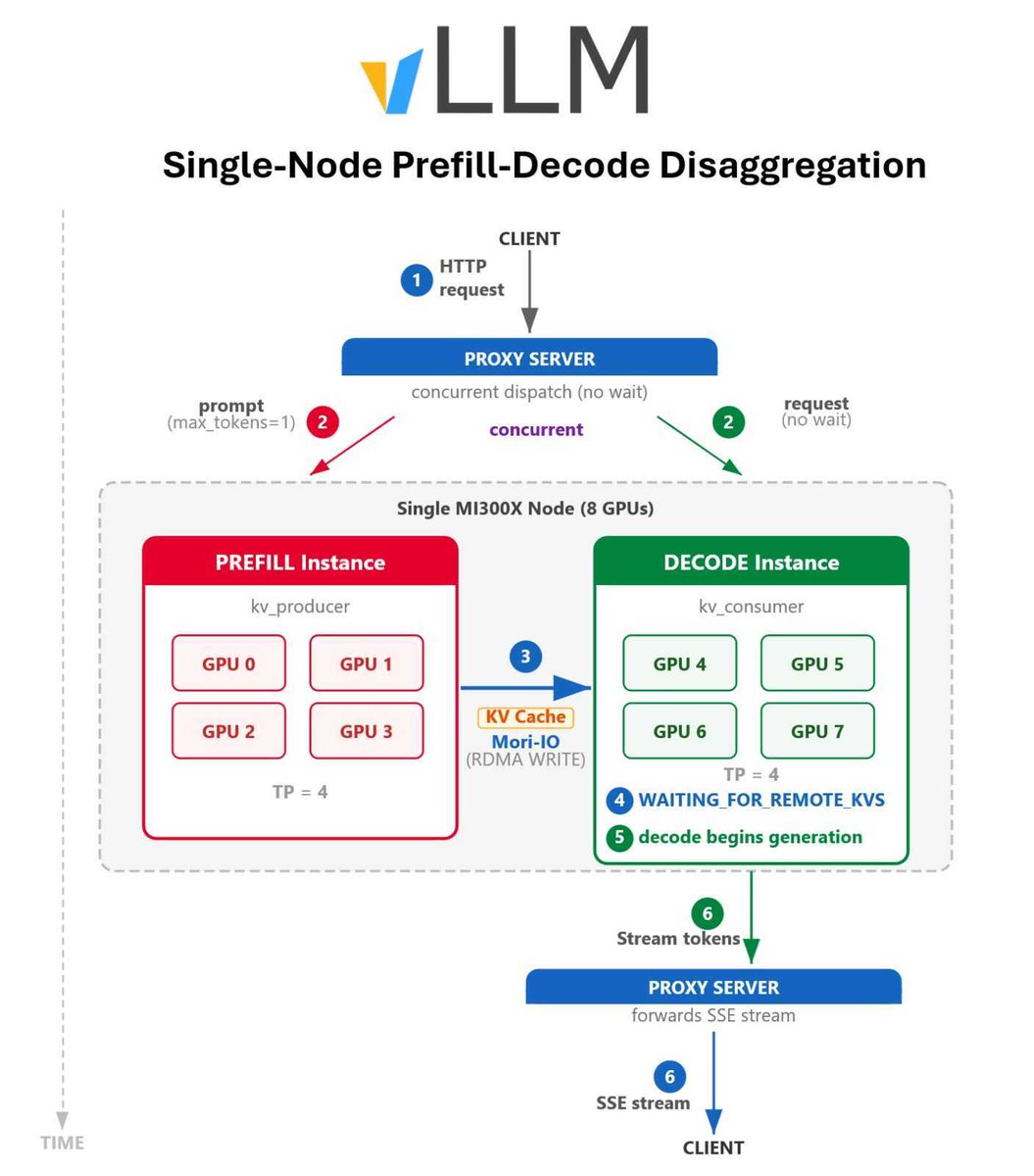
Sabitlenmiş Tweet

✈️ Heading to ICLR 2026 in Rio 🇧🇷! Happy to connect and chat about foundation model pretraining & mid-training, efficient and hybrid architectures, synthetic data generation, and agentic/coding capabilities 🌴 DM me if you're around!
English