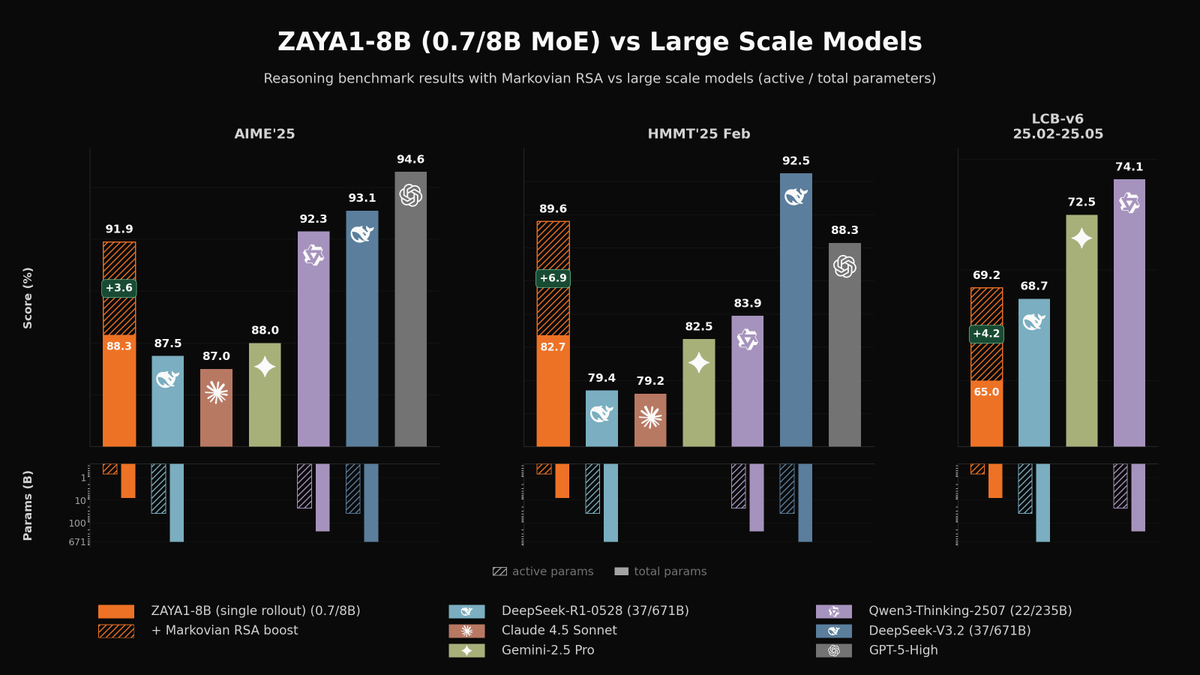
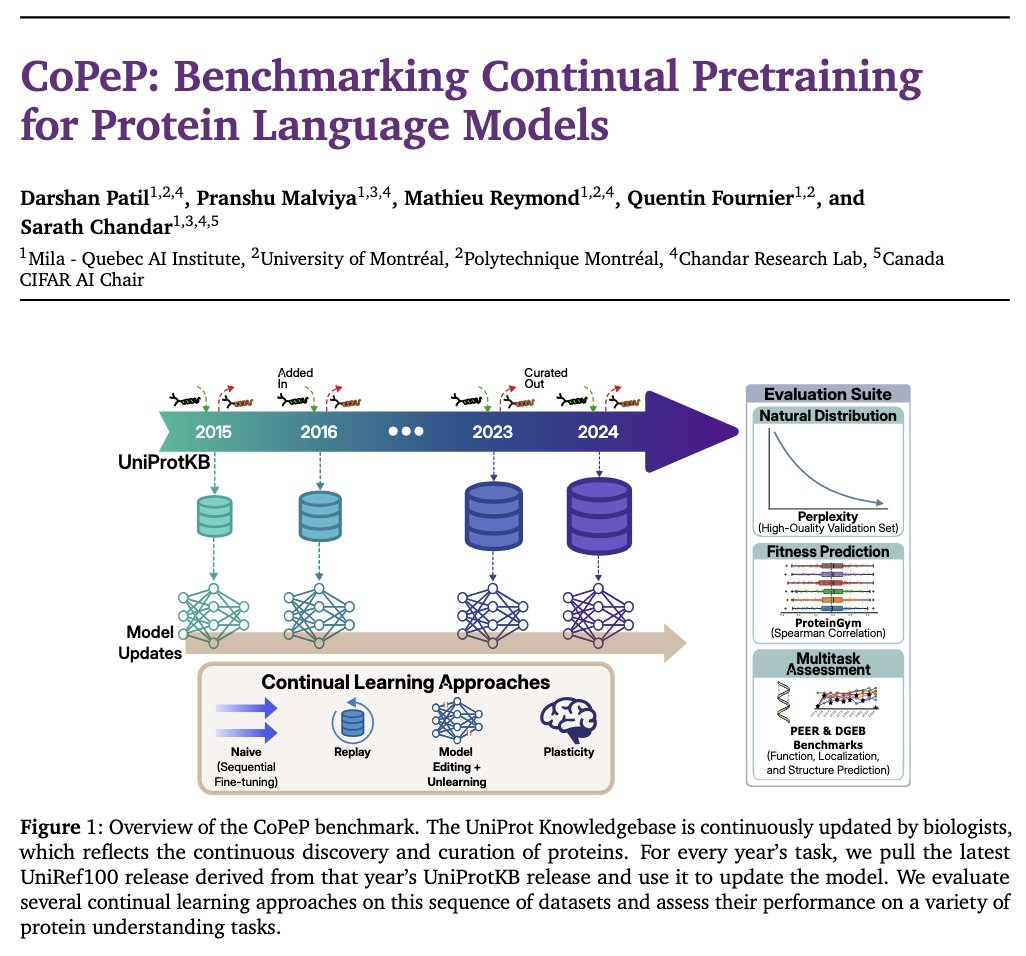
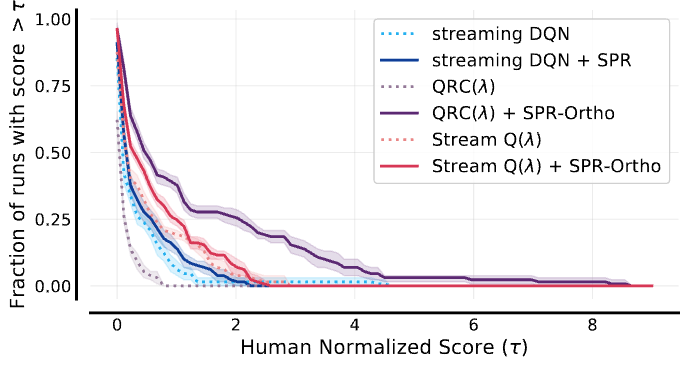
Sabitlenmiş Tweet

Long reasoning without the quadratic tax: The Markovian Thinker makes LLMs reason in chunks with a bounded state → linear compute, constant memory and it keeps scaling beyond the training limit.
1/6
GIF
Milad Aghajohari@MAghajohari
Introducing linear scaling of reasoning: 𝐓𝐡𝐞 𝐌𝐚𝐫𝐤𝐨𝐯𝐢𝐚𝐧 𝐓𝐡𝐢𝐧𝐤𝐞𝐫 Reformulate RL so thinking scales 𝐎(𝐧) 𝐜𝐨𝐦𝐩𝐮𝐭𝐞, not O(n^2), with O(1) 𝐦𝐞𝐦𝐨𝐫𝐲, architecture-agnostic. Train R1-1.5B into a markovian thinker with 96K thought budget, ~2X accuracy 🧵
English