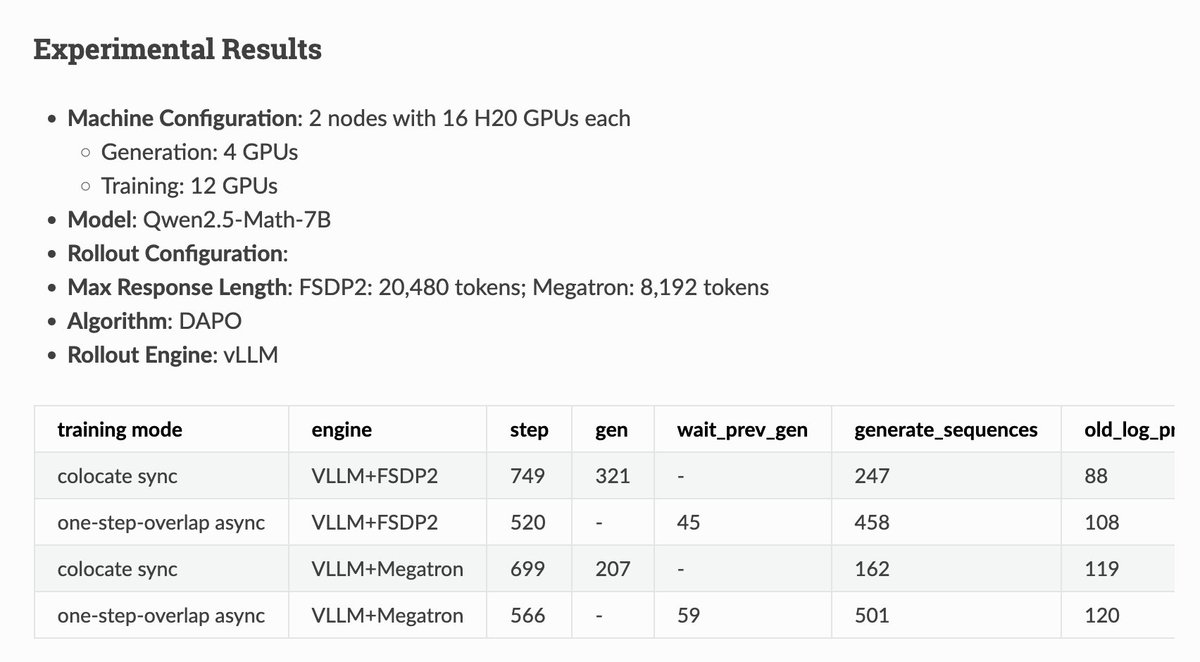
Sabitlenmiş Tweet

Introducing STERLING 💫: "Self-Supervised Terrain Representation Learning from Unconstrained Robot Experience" 💫 to be presented at CoRL 2023 in Atlanta! 😀
Project Page 🌎: hareshkarnan.github.io/sterling/
Paper 🗞️: openreview.net/pdf?id=VLihM67…
A thread 🧵
English