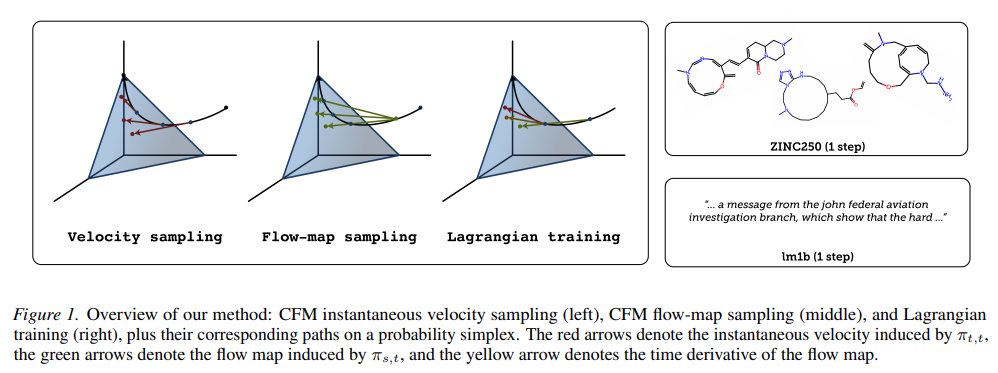
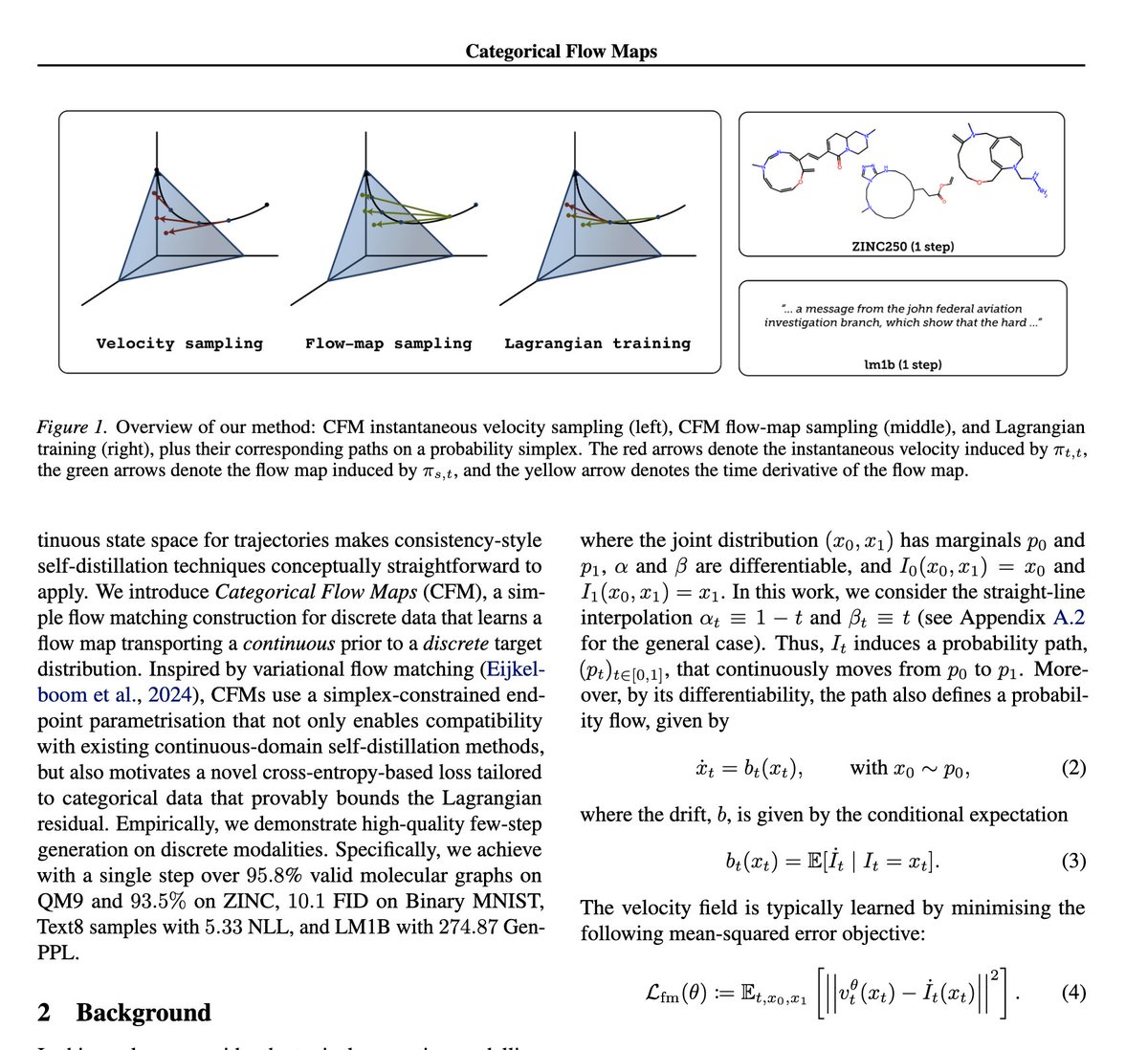
Sabitlenmiş Tweet

You like discrete diffusion, but it's too slow? 🥀
You like test-time inference, but it's for continuous methods? 😩
We fixed it.
Introducing Categorical Flow Maps: continuously sample discrete data in a single step 🚀💫
How? 🧵⬇️
💪 Co-led with @FEijkelboom, @daan_roos_
English