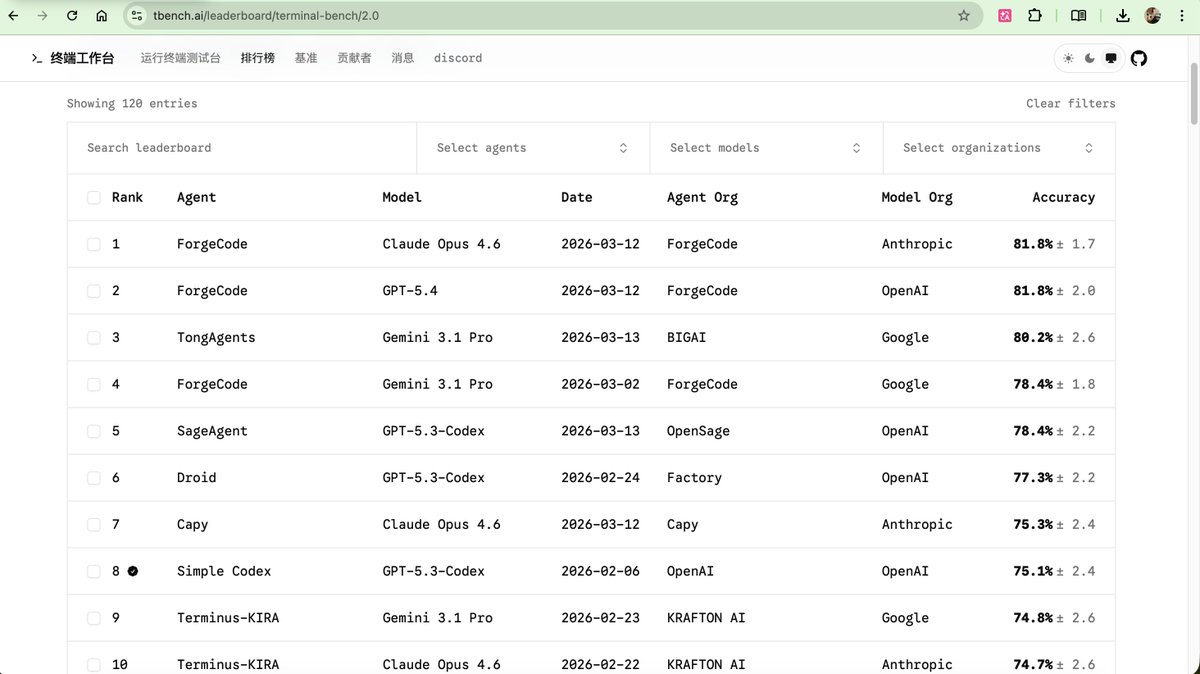
李牧Lab retweetledi

让 Claude Desktop 桌面端接入任意第三方 API 模型的本地代理工具
Kimi · MiniMax · 百炼 · 智谱 GLM · DeepSeek · mimo — 一键切换,无缝使用
github.com/Win-Hao/ModelL…
中文
李牧Lab
347 posts


@Limuchn
AI 产品经理 / Agent 架构师/ 独立开发者 不聊虚的概念,只做能用的 Agent,讲能听懂的 AI


In today's podcast, we sit down with indigox, the co-founder of Weibo, a social media platform (Like X in US). AI investor who has backed Anthropic, Cohere, #xAI, TogetherAI, Lambda, and #SpaceX. @BillSun_AI "I think everything is media, and that's the most important thing. You have to get attention, otherwise it's really hard to survive. Whether you're building a brand, running a fund, or making a product, it's all the same." Welcome to the Innovator Coffee, a podcast that bridges the gap between people and the world of AI and innovation. Follow us on Sportify, YouTube and Apple to like, share and comment. See full session below: youtube.com/watch?v=KWlFmD…


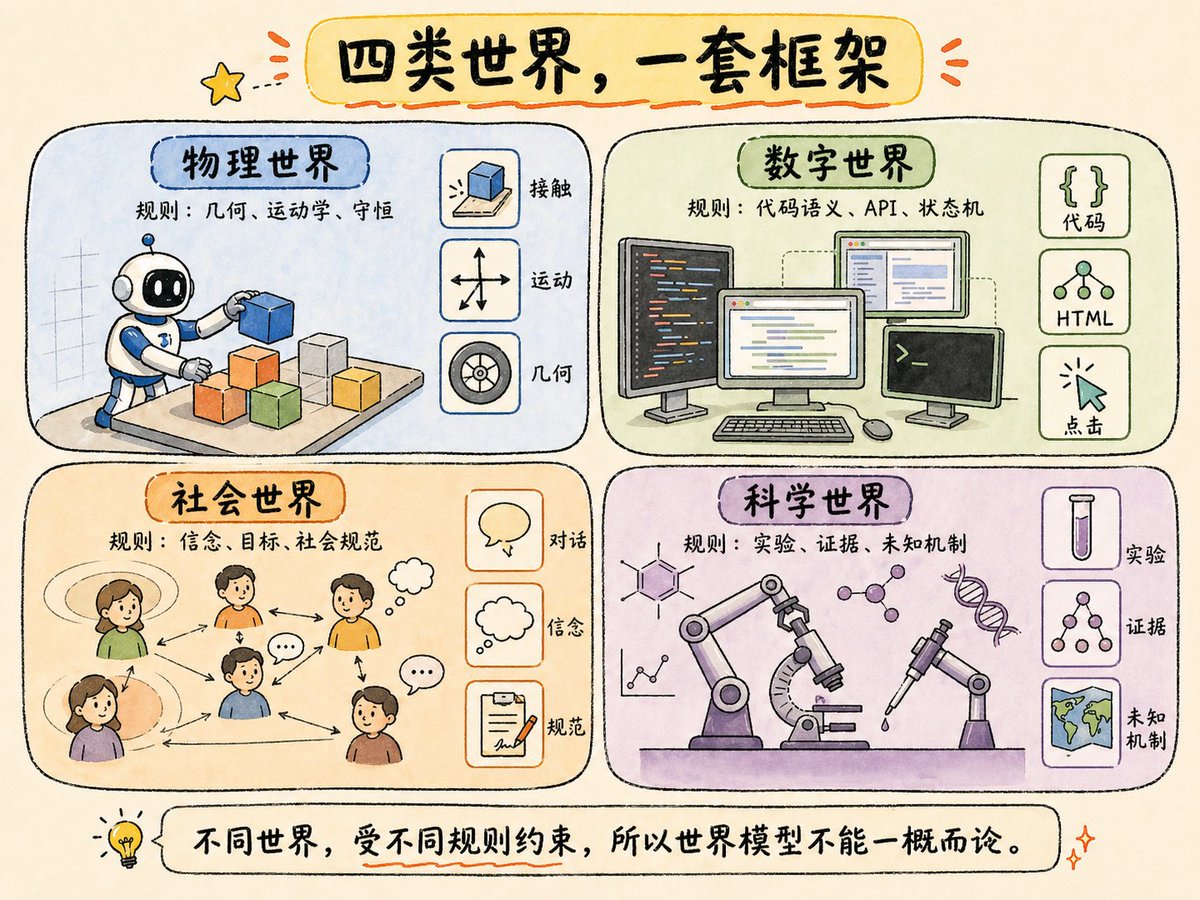
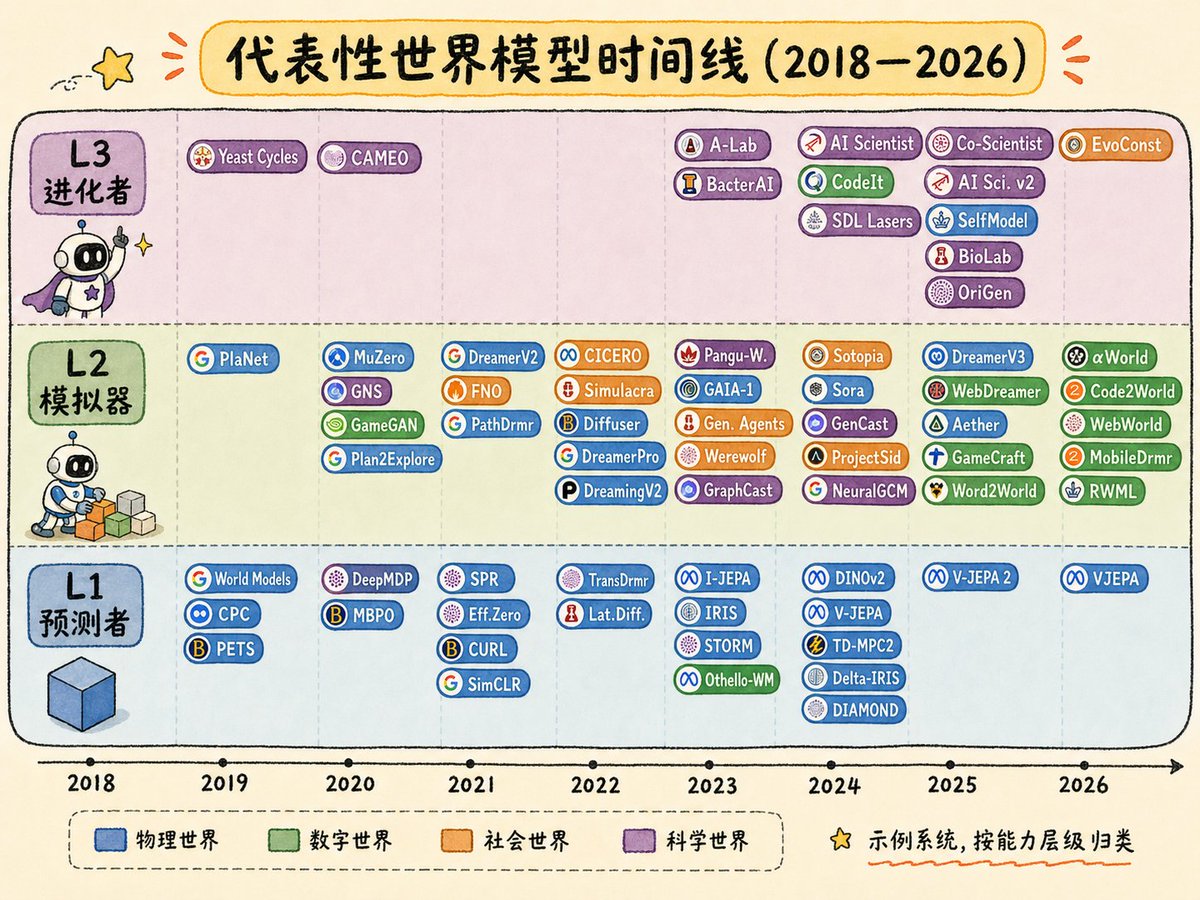
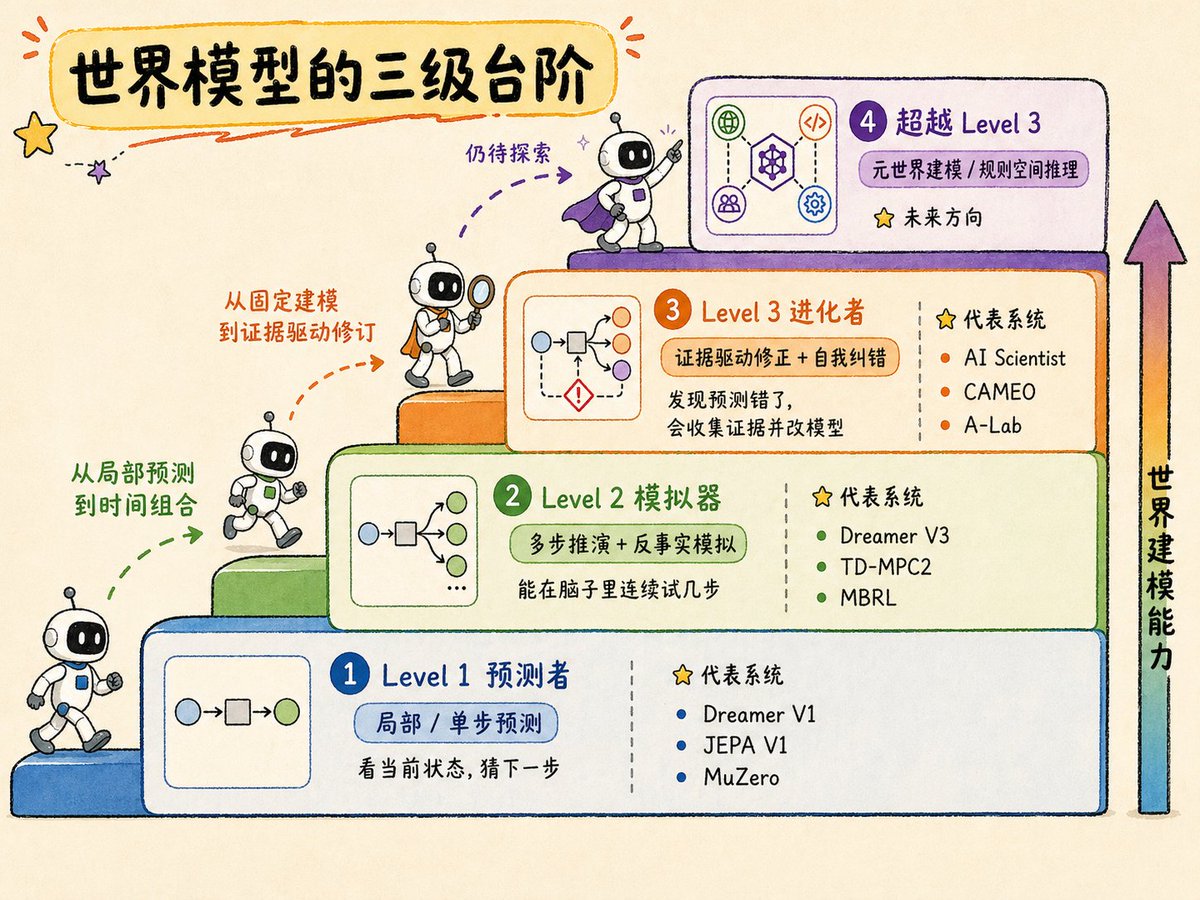
🚀 Our new preprint is out: Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond It also reached #1 on Hugging Face Daily Papers 🎉 @huggingface @HuggingPapers @_akhaliq Joint work from @HKUST, @NUSingapore, @UniofOxford, @NTUsg, @CUHKofficial, @HKUniversity, @UW and more. arXiv: arxiv.org/abs/2604.22748 HF: huggingface.co/papers/2604.22…







😅嗯,bb-browser,badboy browser,坏孩子浏览器来了,真的很丧良心,但真的很好用。 现在你可以用 bb-browser site 的方式直接拉到任何网站的信息,目前支持 Reddit、Twitter、GitHub、Hacker News、小红书、知乎、B站、微博、豆瓣、YouTube,50+ 个命令,我会持续更新。 当然能做到信息获取这件事不稀奇,我也是看到 @jakevin7 的 twitter-cli 的启发,才做的。但 bb-browser 的实现方式非常丧良心 — 我是通过 Chrome 插件 + CDP 直接操控你真实的浏览器。不是无头浏览器,不是偷 Cookie,不是模拟请求。你已登录了,它就直接用你的登录态。它直接在浏览器 console 里面跑 eval,以前爬虫最麻烦的登录态、还有各种鉴权都没有了😂。(这种方式真的。。。太作弊了,我都能想到哪些大厂前端发现我在这么搞,会怎么骂我,因为真的很难防) 另外我还在命令行里面埋了 guide 命令,也就是说你只要装了 bb-browser CLI 或 MCP,跟你的 Agent 说"我需要把 XX 网站 CLI 化",它就能帮你做了!!


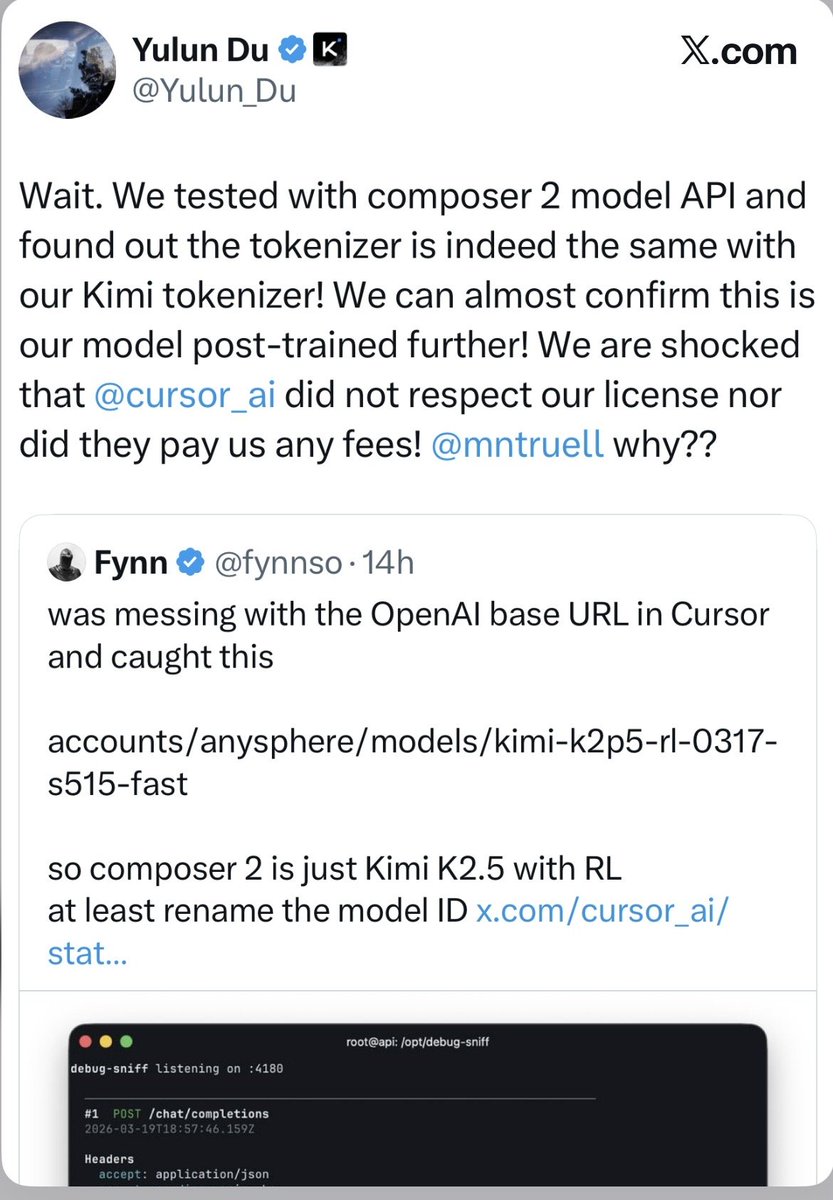
Cursor is raising at a $50 billion valuation on the claim that its “in-house models generate more code than almost any other LLMs in the world.” Less than 24 hours after launching Composer 2, a developer found the model ID in the API response: kimi-k2p5-rl-0317-s515-fast. That’s Moonshot AI’s Kimi K2.5 with reinforcement learning appended. A developer named Fynn was testing Cursor’s OpenAI-compatible base URL when the identifier leaked through the response headers. Moonshot’s head of pretraining, Yulun Du, confirmed on X that the tokenizer is identical to Kimi’s and questioned Cursor’s license compliance. Two other Moonshot employees posted confirmations. All three posts have since been deleted. This is the second time. When Cursor launched Composer 1 in October 2025, users across multiple countries reported the model spontaneously switching its inner monologue to Chinese mid-session. Kenneth Auchenberg, a partner at Alley Corp, posted a screenshot calling it a smoking gun. KR-Asia and 36Kr confirmed both Cursor and Windsurf were running fine-tuned Chinese open-weight models underneath. Cursor never disclosed what Composer 1 was built on. They shipped Composer 1.5 in February and moved on. The pattern: take a Chinese open-weight model, run RL on coding tasks, ship it as a proprietary breakthrough, publish a cost-performance chart comparing yourself against Opus 4.6 and GPT-5.4 without disclosing that your base model was free, then raise another round. That chart from the Composer 2 announcement deserves its own paragraph. Cursor plotted Composer 2 against frontier models on a price-vs-quality axis to argue they’d hit a superior tradeoff. What the chart doesn’t show is that Anthropic and OpenAI trained their models from scratch. Cursor took an open-weight model that Moonshot spent hundreds of millions developing, ran RL on top, and presented the output as evidence of in-house research. That’s margin arbitrage on someone else’s R&D dressed up as a benchmark slide. The license makes this more than an attribution oversight. Kimi K2.5 ships under a Modified MIT License with one clause designed for exactly this scenario: if your product exceeds $20 million in monthly revenue, you must prominently display “Kimi K2.5” on the user interface. Cursor’s ARR crossed $2 billion in February. That’s roughly $167 million per month, 8x the threshold. The clause covers derivative works explicitly. Cursor is valued at $29.3 billion and raising at $50 billion. Moonshot’s last reported valuation was $4.3 billion. The company worth 12x more took the smaller company’s model and shipped it as proprietary technology to justify a valuation built on the frontier lab narrative. Three Composer releases in five months. Composer 1 caught speaking Chinese. Composer 2 caught with a Kimi model ID in the API. A P0 incident this year. And a benchmark chart that compares an RL fine-tune against models requiring billions in training compute without disclosing the base was free. The question for investors in the $50 billion round: what exactly are you buying? A VS Code fork with strong distribution, or a frontier research lab? The model ID in the API answers that. If Moonshot doesn’t enforce this license against a company generating $2 billion annually from a derivative of their model, the attribution clause becomes decoration for every future open-weight release. Every AI lab watching this is running the same math: why open-source your model if companies with better distribution can strip attribution, call it proprietary, and raise at 12x your valuation? kimi-k2p5-rl-0317-s515-fast is the most expensive model ID leak in the history of AI licensing.