
Lin Chen
25 posts

Lin Chen
@Lin_Chen_98
PhD in USTC | Large multimodal models |Research intern in Shanghai AI Lab
Katılım Kasım 2023
51 Takip Edilen58 Takipçiler

@Hellostone2024 @aasdt65lo3673 @detresfa_ Two nuclear bomb may not be enough. Cuz it tasted that from its American daddy.
English

@aasdt65lo3673 @detresfa_ So based on Japan's land area, two nuclear bombs are enough, or even one.
English

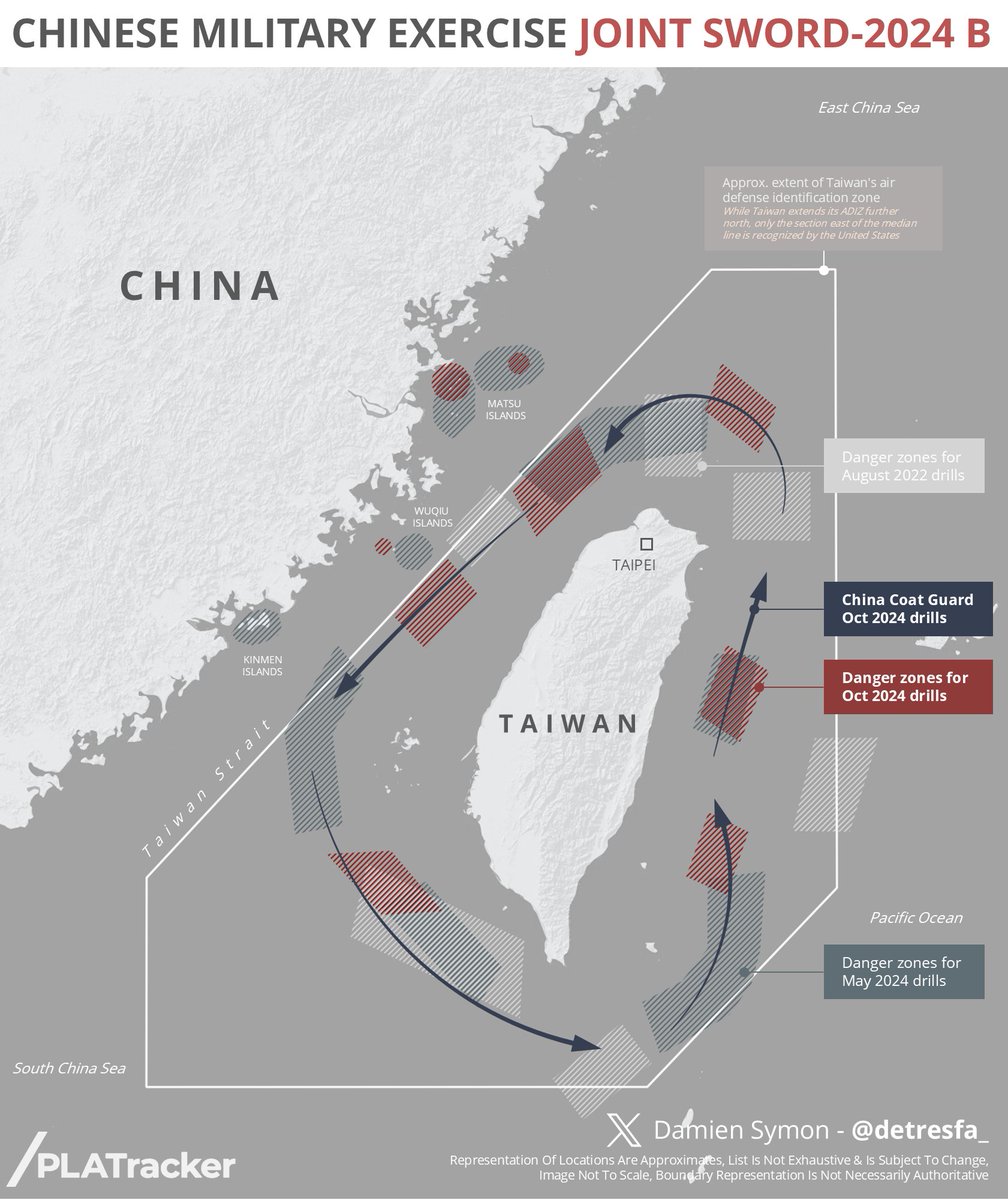
#Breaking - China's Eastern Theater Command has begun “Joint Sword-2024B" - a combined military drill using its army, navy, air force, rocket force & coast guard around Taiwan
English
@olusegini @jcokechukwu fucking genius! hope u can keep ‘intelligent’ forever.
English

@jcokechukwu Taiwan has defeated China before...they will defeat them again
English

BREAKING: The Chinese military have completely surrounded Taiwan in a one-of-a-kind military exercise.
The PLA Exercise Joint Sword 2024B has the specific goal of "blockade and control of key ports and areas, strikes on sea and land targets".
We might see China's PLA stop and inspect Taiwan bound vessels.
Taiwan has put F-16 fighters on alert to patrol areas adjacent to the area where large-scale exercises of the Chinese PLA are being held.
Anti-ship cruise missile launchers are also located in the coastal zone.
Meanwhile Russian Defense Minister Andrei Belousov arrived in Beijing on an official visit for talks with the military and military-political leadership of China, — Russian Defense Ministry.
And in the Middle East, despite all the soft core posturing between Israel and Iran, something really big is cooking. It’s the timing of all these for me. I am convinced that it’ll be a miracle for us to escape ww3 - and I believe in miracles.

English

Introducing DuoAttention: Our new framework slashes both memory and latency for long-context LLMs without sacrificing performance! By applying full KV cache only to critical heads, we achieve:
⚡ 2.55x memory reduction
⚡ 2.18x decoding speedup
⚡ 3.3M tokens on a single A100 GPU
English






@Lin_Chen_98 Yes, we are indeed directly using your repo in our llava-next experiments. We will surely clearly mention and cite it when we do the arXiv update. Thanks for letting us know.
English
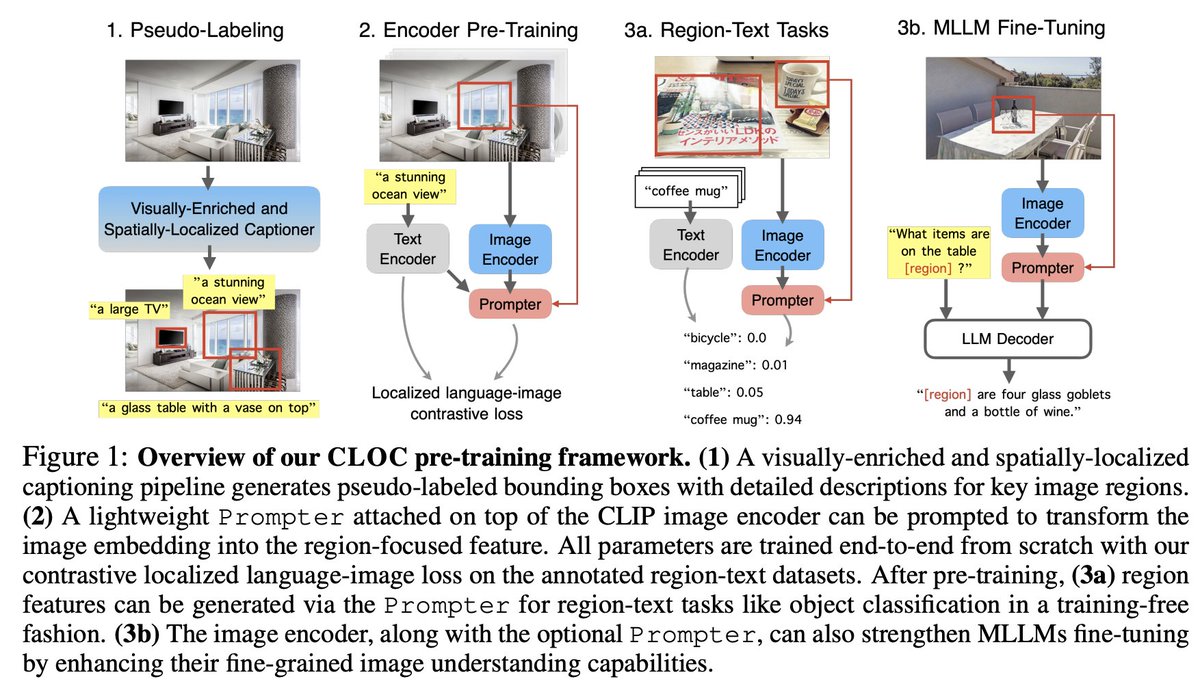
💡CLIP is the default choice for most multimodal LLM research. But, we know CLIP is not perfect. It is good at high-level semantics, but not for capturing fine-grained info.
🤩🤩 We present CLOC ⏰, our next-generation image encoder, with enhanced localization capabilities, and serves as a drop-in replacement for CLIP.
🚀🚀How to do that? We conduct large-scale pre-training with region-text supervision pseudo-labelled on 2B images.
🎁As a result, CLOC is indeed a better image encoder, not only for zero-shot image/region tasks, but also for multimodal LLM.
English
Lin Chen retweetledi

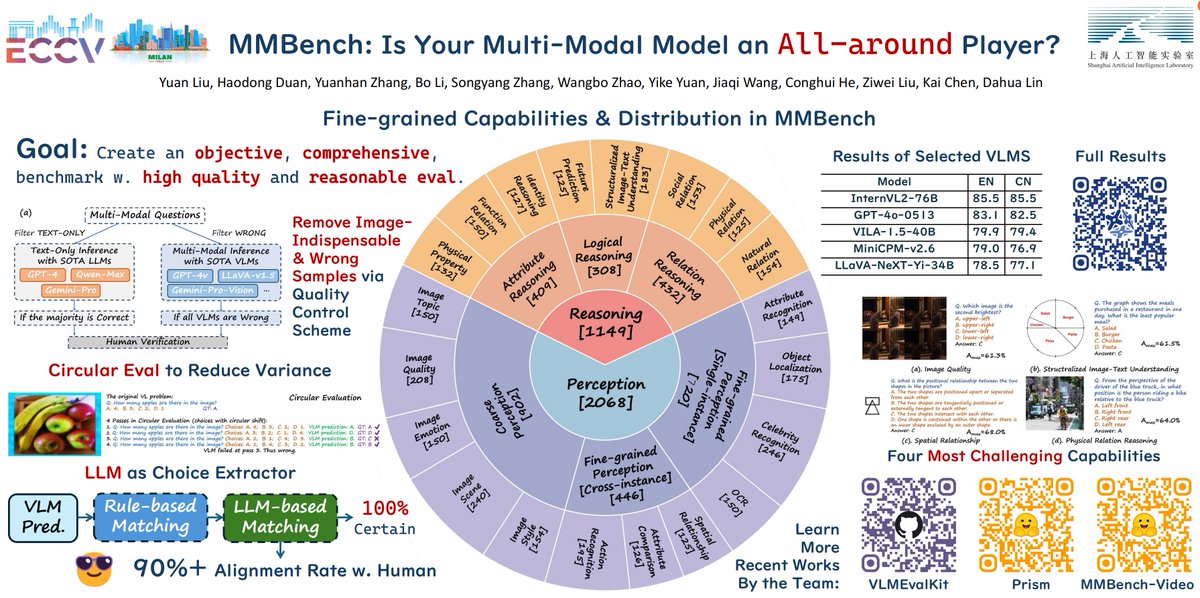
Excited to share several of our recent works:
1. MMBench (ECCV'24 Oral@6C, Oct 3, 13:30): A comprehensive mutli-modal evaluation benchmark adopted by hundreds of teams working on LMMs.
mmbench.opencompass.org.cn
2. Prism (NeurIPS'24): A framework that can disentangle and assess the perception and reasoning abilities of VLMs, and a potential cost-effective solution for vision-language tasks. arxiv.org/abs/2406.14544
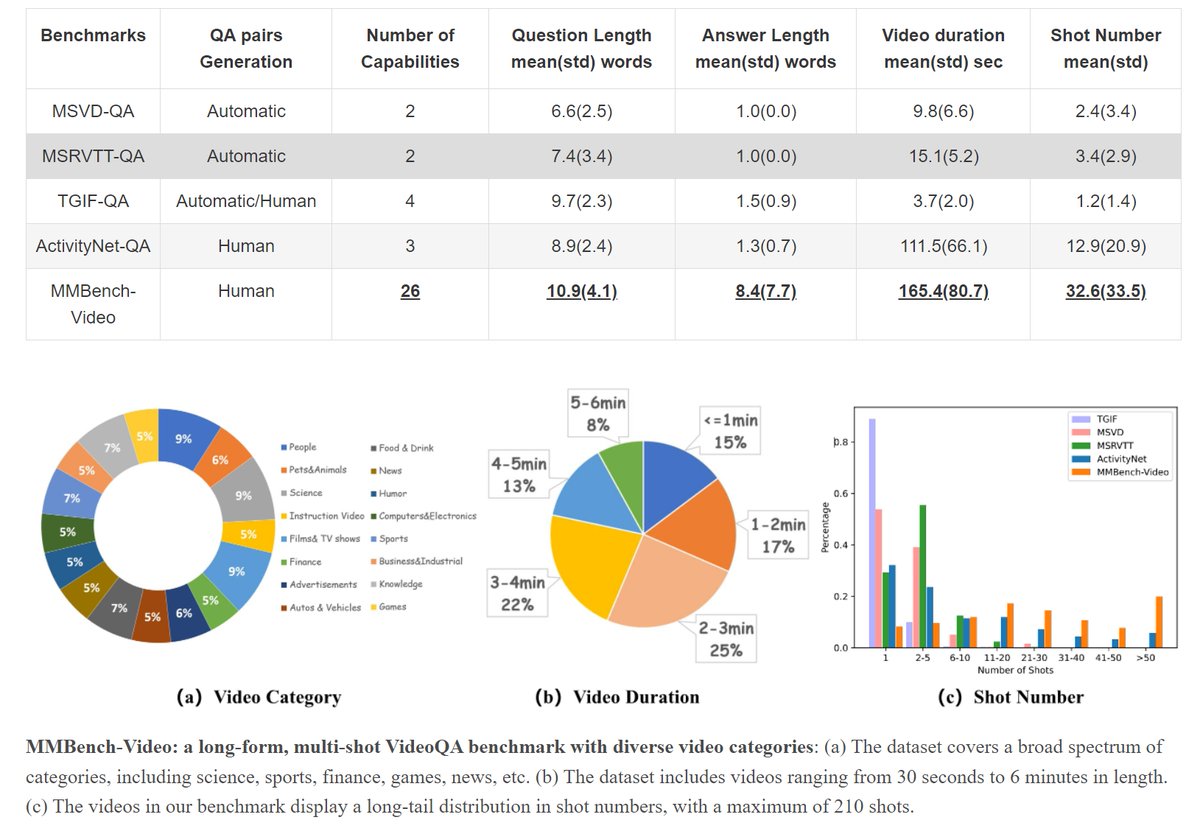
3. MMBench-Video (NeurIPS'24 Dataset): A Long-Form Multi-Shot Benchmark for Holistic Video Understanding. mmbench-video.github.io
4. VLMEvalKit (MM'24 OpenSource): An open-source evaluation toolkit of LMMs, supporting 100+ different LMMs and ~50 multi-modal benchmarks. github.com/open-compass/V…
If you want to learn more about our work or talk about LMM or other topics, I'm always happy to have a chat. Besides, our team also has openings for intern/full-time researchers and engineers. Feel free to DM me if you are interested.

English
@JustinLin610 Amazing work! I’m crazy fans of Qwen series. Looooooking forward to your team’s future works!
English

Finally got some time to chat about these new models. We started the project of Qwen2.5 at the moment we released Qwen2. Through this process we did realize a lot of problems and mistakes that we made. In terms of pretraining, we simply focus on leveling up the quality and quantity of the pretraining data, just using a lot of methods that you are familiar with, like text classifier for recalling quality data, LLM scorers for scoring data so that we can strike a balance between quality and quantity. Along with the creation of expert models, we use them for synthetic data generation. In terms of posttraining, the user feedbacks helped us solve problems one by one and at the same time we are exploring how RLHF methods can help especially those of online learning. I hope you find them interesting and helpful for your research and work. Since now we are moving to the next stage to solve more difficult problems. For a long time we hope to build a multimodal multitask AI model or system and it seems that we are not that far from a good unification of modalities and tasks. Furthermore, shocked by o1, we think that we should dive into the research in the reasoning capabilities and see how smart an AI model or system can be. We hope that we can bring totally new stuffs to you very soon!
Qwen@Alibaba_Qwen
Welcome to the party of Qwen2.5 foundation models! This time, we have the biggest release ever in the history of Qwen. In brief, we have: Blog: qwenlm.github.io/blog/qwen2.5/ Blog (LLM): qwenlm.github.io/blog/qwen2.5-l… Blog (Coder): qwenlm.github.io/blog/qwen2.5-c… Blog (Math): qwenlm.github.io/blog/qwen2.5-m… HF Collection: huggingface.co/collections/Qw… ModelScope: modelscope.cn/organization/q… HF Demo: huggingface.co/spaces/Qwen/Qw… * Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B * Qwen2.5-Coder: 1.5B, 7B, and 32B on the way * Qwen2.5-Math: 1.5B, 7B, and 72B. All our open-source models, except for the 3B and 72B variants, are licensed under Apache 2.0. You can find the license files in the respective Hugging Face repositories. Furthermore, we have also open-sourced the **Qwen2-VL-72B**, which features performance enhancements compared to last month's release. As usual, we not only opensource the bf16 checkpoints but we also provide quantized model checkpoints, e.g, GPTQ, AWQ, and GGUF, and thus this time we have a total of over 100 model variants! Notably, our flagship opensource LLM, Qwen2.5-72B-Instruct, achieves competitive performance against the proprietary models and outcompetes most opensource models in a number of benchmark evaluations! We heard your voice about your need of the welcomed 14B and 32B models and so we bring them to you. These two models even demonstrate competitive or superior performance against the predecessor Qwen2-72B-Instruct! SLM we care as well! The compact 3B model has grasped a wide range of knowledge and now is able to achive 68 on MMLU, beating Qwen1.5-14B! Besides the general language models, we still focus on upgrading our expert models. Still remmeber CodeQwen1.5 and wait for CodeQwen2? This time we have new models called Qwen2.5-Coder with two variants of 1.5B and 7B parameters. Both demonstrate very competitive performance against much larger code LLMs or general LLMs! Last month we released our first math model Qwen2-Math, and this time we have built Qwen2.5-Math on the base language models of Qwen2.5 and continued our research in reasoning, including CoT, and Tool Integrated Reasoning. What's more, this model now supports both English and Chinese! Qwen2.5-Math is way much better than Qwen2-Math and it might be your best choice of math LLM! Lastly, if you are satisfied with our Qwen2-VL-72B but find it hard to use, now you got no worries! It is OPENSOURCED! Prepare to start a journey of innovation with our lineup of models! We hope you enjoy them!
English
English

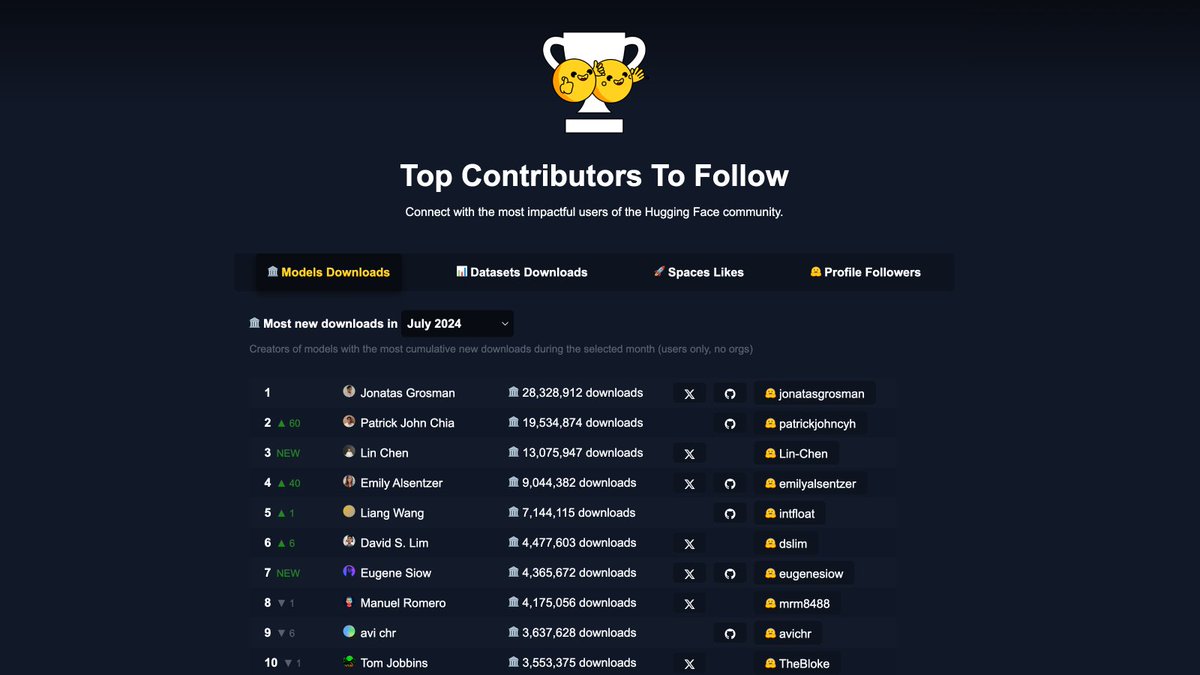
🤗 Here are the top 100 of @HuggingFace’s most impactful users of July 2024 (models, datasets, spaces, followers):
🏆 Top Contributors To Follow: huggingface.co/spaces/mvaloat…
-
🏛️ Top 10 Model Downloads: 👏 @jonatasgrosman, #PatrickJohnChia, @Lin_Chen_98, @Emily_Alsentzer, #LiangWang, @limsanity23, @eugene_siow, @mrm8488, #avichr, @TheBlokeAI
📊 Top 10 Dataset Downloads: 👏 @haileysch__, @nathanhabib1011, @lukaemon, #HaonanLi, @algo_diver, #YebHavinga, @princeton_nlp, @jonbtow, @moonares, #DanHendrycks
🚀 Top 10 Space Likes: 👏 @fffiloni, @flngr, @multimodalart, @_akhaliq, @yvrjsharma, @angrypenguinpng, @hysts12321, #NishithJain, @xenovacom, @radamar
🤗 Top 10 Profile Followers: 👏 @TheBlokeAI, @mervenoyann, @fffiloni, @_akhaliq, #LvminZhang, @teknium, @xenovacom, #Undi, @erhartford, #WizardLM
English
Thrilled to see myself in the #3 spot on HuggingFace’s most influential users for July!
I look forward to doing more impactful works to give back to the community in the future.
Matt Valoatto@mvaloatto
🤗 Here are the top 100 of @HuggingFace’s most impactful users of July 2024 (models, datasets, spaces, followers): 🏆 Top Contributors To Follow: huggingface.co/spaces/mvaloat… - 🏛️ Top 10 Model Downloads: 👏 @jonatasgrosman, #PatrickJohnChia, @Lin_Chen_98, @Emily_Alsentzer, #LiangWang, @limsanity23, @eugene_siow, @mrm8488, #avichr, @TheBlokeAI 📊 Top 10 Dataset Downloads: 👏 @haileysch__, @nathanhabib1011, @lukaemon, #HaonanLi, @algo_diver, #YebHavinga, @princeton_nlp, @jonbtow, @moonares, #DanHendrycks 🚀 Top 10 Space Likes: 👏 @fffiloni, @flngr, @multimodalart, @_akhaliq, @yvrjsharma, @angrypenguinpng, @hysts12321, #NishithJain, @xenovacom, @radamar 🤗 Top 10 Profile Followers: 👏 @TheBlokeAI, @mervenoyann, @fffiloni, @_akhaliq, #LvminZhang, @teknium, @xenovacom, #Undi, @erhartford, #WizardLM
English
Lin Chen retweetledi

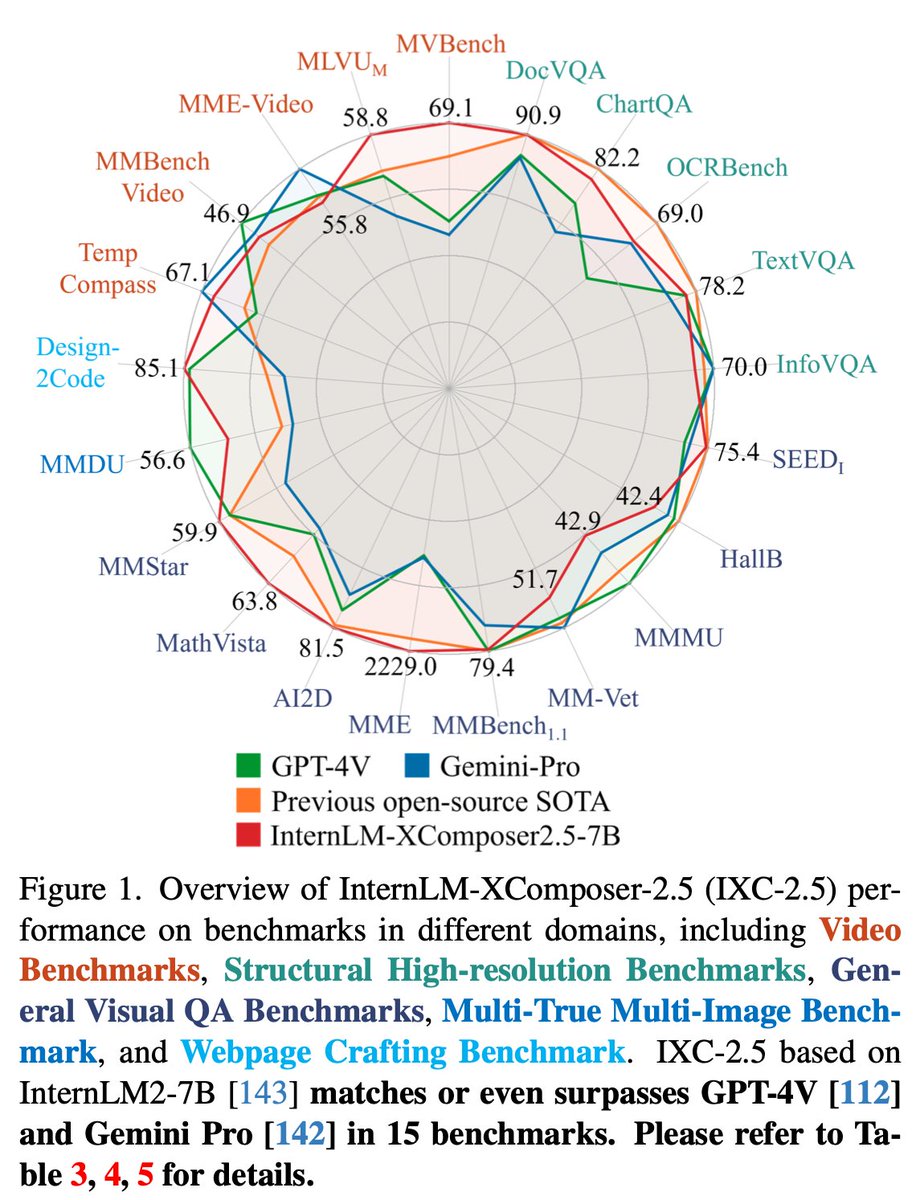
New SoTA VLM: InternLM XComposer 2.5 🐐
> Beats GPT-4V, Gemini Pro across myriads of benchmarks.
> 7B params, 96K context window (w/ RoPE ext)
> Trained w/ 24K high quality image-text pairs
> InternLM 7B text backbone
> Supports high resolution (4K) image understanding tasks
> Video understanding and multi-turn, multi-image chat supported too
> Bonus: Capable of generating web pages (w/ prompt) and high quality text-image articles :O
GG InternLM team, first a SoTA 7B LLM followed by a SoTA 7B VLM! ⚡
Demo and model checkpoints below!
English
Lin Chen retweetledi

InternLM-XComposer-2.5
A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output
We present InternLM-XComposer-2.5 (IXC-2.5), a versatile large-vision language model that supports long-contextual input and output. IXC-2.5 excels in various text-image comprehension and composition applications, achieving GPT-4V level capabilities with merely 7B LLM backend. Trained with 24K interleaved image-text contexts, it can seamlessly extend to 96K long contexts via RoPE extrapolation. This long-context capability allows IXC-2.5 to excel in tasks requiring extensive input and output contexts. Compared to its previous 2.0 version, InternLM-XComposer-2.5 features three major upgrades in vision-language comprehension: (1) Ultra-High Resolution Understanding, (2) Fine-Grained Video Understanding, and (3) Multi-Turn Multi-Image Dialogue. In addition to comprehension, IXC-2.5 extends to two compelling applications using extra LoRA parameters for text-image composition: (1) Crafting Webpages and (2) Composing High-Quality Text-Image Articles. IXC-2.5 has been evaluated on 28 benchmarks, outperforming existing open-source state-of-the-art models on 16 benchmarks. It also surpasses or competes closely with GPT-4V and Gemini Pro on 16 key tasks.
English
Lin Chen retweetledi

InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output
- Excels in various text-image tasks w/ GPT-4V level capabilities with merely 7B LLM backend
- Opensourced
arxiv.org/abs/2407.03320

English
@Gradio @Gradio Could you tweet about our ShareCaptioner-Video demo for generating detailed captions for videos?
Link: huggingface.co/spaces/Lin-Che…
English

Built our @Gradio app and deployed ShareCaptioner-Video on @huggingface Spaces with ZeroGPU. Now, you can try to generate detailed caption for your own video. Have fun!
huggingface.co/spaces/Lin-Che…
AK@_akhaliq
ShareGPT4Video Improving Video Understanding and Generation with Better Captions We present the ShareGPT4Video series, aiming to facilitate the video understanding of large video-language models (LVLMs) and the video generation of text-to-video models (T2VMs)
English
Thanks for @_akhaliq sharing our work!
We sincerely hope this series can help the video-language community!😆😆
AK@_akhaliq
ShareGPT4Video Improving Video Understanding and Generation with Better Captions We present the ShareGPT4Video series, aiming to facilitate the video understanding of large video-language models (LVLMs) and the video generation of text-to-video models (T2VMs)
English
Looking forward to working on a longer version together!
You can preview our ShareGPT4Video project in the following link!
sharegpt4video.github.io
Bin Lin@LinBin46984
📣📣📣We are excited to announce the release of Open-Sora Plan v1.1.0. 🙌Thanks to ShareGPT4Video's capability to annotate long videos, we can generate higher quality and longer videos. 🔥🔥🔥We continue to open-source all data, code, and models! github.com/PKU-YuanGroup/…
English
@LinBin46984 Thanks, bro! Looking forward to working on a longer version together!😍😍
English

🤩🤩🤩The awesome ShareGPT4Video page here: sharegpt4video.github.io
English
📣📣📣We are excited to announce the release of Open-Sora Plan v1.1.0.
🙌Thanks to ShareGPT4Video's capability to annotate long videos, we can generate higher quality and longer videos.
🔥🔥🔥We continue to open-source all data, code, and models!
github.com/PKU-YuanGroup/…
English



