
David Longman
110 posts

BIG day for us!! Command Code is now one of the fastest-growing coding agent harness for open models. 3rd largest by usage.
In 24 days after public beta launch:
• $1M in annual run rate
• 1 trillion tokens of usage
• Over 9K customers
thank you for using me [⌐■_■]
Ahmad Awais@MrAhmadAwais
BIG day for us!! @CommandCodeAI has crossed $1M in annual run rate, 1 trillion tokens of usage, with over 9K customers, just 24 days after our public beta launch. we believe this makes it the fastest-growing coding agent harness for open models. 3rd largest by usage. Command Code is built around two ideas: 1. open models should be production-grade for coding. 2. your coding agent should learn your taste. we're building for taste and developer experience. so instead of making a soup of thousands of models, we build for the best ones, open or closed. the goal: a coding agent that feels like an iphone, opinionated and with taste, not a random android or a windows phone with no taste. on the first idea: open models. we fixed the "open models aren't good enough at tool calling" problem. our research came down to two things, quality and speed, and both trace back to one root cause: broken tool-calls that open models produce, especially when you use a bad harness. open-model tool-call failures are not deep, they are a small finite set of contract mismatches. so we repair them, with zero token loss. what started as 4 repairs is now the largest repair layer in the space: 36k tool-call fix variants. i wrote the idea up openly¹ a few weeks ago, and it has quietly become a de facto way people fix open models. developers have either adopted Command Code or used the same idea to build repair harnesses for nearly every top coding agent. i take that as more meaningful validation than anything we could say about ourselves. on the second idea: taste. Command Code builds your coding taste into skills, learned from your accepts, rejects, edits, prompts, and the corrections you repeat. over time it drifts away from generic code and toward how you actually ship code. it learns continuously, and while it is early, the direction feels right. net effect: developers using Command are writing production-quality code on open models, 10x to 100x cheaper, without fighting tool calls, while building repo and team-wide coding taste that compounds. i believe these numbers are a consequence of getting those two things right. what's next. we've applied the same repair idea to ai design slop, and bundled a /design capability² so every developer can level up their design work. the early response has been great. we have a big roadmap ahead of us. the feedback we hear most is that Command Code feels fundamentally different: an approach built on taste and repair. we're going open source next month. today we're a cli at the core, and we're also launching a full-fledged gui app, sandboxed background agents, and cooking up something fun i can't wait to share. we're growing too, hiring in sf and remote worldwide. check open roles on my profile bio. try it now. npm i -g command-code if you like engineering deep dives on how we're doing all this, i've linked some relevant posts below.
English
Yes $1 Go plan is cool. But more is coming.
Noon 12pm Monday, 1st June.
Command Code deal drop.
This one is gonna be crazy good!!

English
@MrAhmadAwais @CommandCodeAI Make command code ACP compatible please!
English

🚀 Better inference efficiency, lower costs, broader access.
MiMo-V2.5 Series API pricing is now permanently reduced — by up to 99% compared to previous pricing.
✨ Unified pricing across all context lengths.
MiMo Token Plans have also been upgraded:
• 5–8× more usable tokens at the same price
• Simpler and more transparent billing rules
🎁 As a thank-you to current users, all current Token Plan credits will be fully reset.
🎧 MiMo-V2.5-TTS remains free for a limited time.
⏰ Effective May 26 at 6:00 PM PDT.
These improvements are powered by continued inference optimization and serving efficiency upgrades across the MiMo stack.
🛠️ We’ll also publish a detailed technical blog on the inference optimizations later — stay tuned.


English
@JackWoth98 Allow us to use our subs elsewhere…. Like opencode etc…
English

How can we make the migration from Gemini CLI to Antigravity CLI easier?
One of my goals is to help folks move over as smoothly as possible.
So far I am hearing the following gaps are holding people back... ACP, more robust headless mode, subagents, Gemini CLI extensions... anything else?
I'll be working on some videos/resources this week so let me know where I can add clarity or details.
🧵I'll link a few existing resources
English
@TimJayas A day? On Pro, I used my Opus quota for the week in a single prompt. About 20 mins of runtime.
English


English

Command Code is now the 4th most used coding agent beating Kilo, OpenCode, Roo Code, and Hermes agent on Vercel AI Gateway!!
three reasons i could think why:
1. First of all, yes we're going open source soon
2. Our $1 Go plan with open models is the best AI coding deal on the market. Period.
3. While other agents only cater to top commercial models, Command Code is probably the best harness purpose built for open models.
More in my eng deep dives¹ on repair harness engineering below.

English
@cognition @cerebras Pretty sure I was in first 100 here and did not get anything?
English

@ericzakariasson Let me BYOK and use it for free. Then if I like it, maybe I subscribe.
English

how can we make cursor 3 better?
send us any bugs, feature requests, or feedback you have!

English

@nahcrof Awesome. Ever consider the Github style model, so something like Flash might consume 0.5x or even 0.25x requests?
English
@nahcrof Wow, nice. I even had my LLM look at your page and it was like "You pay for both requests + tokens" so I guess I wasn't the only "one" confused - lol
English

@LongmanDave If you have a monthly subscription then you get the number of daily requests you pay for “free”, if you exceed that limit then every request after is charged at paygo pricing if you have credits
English
for $5 a month you can have access to kimi-k2.6 and glm-5.1 at comparable speeds and with high concurrency
Joao Marcos@joaomviso
Por $60 dólares mensais você roda um LLM do nível do Opus 4.5 sozinho. Sem limite de tokens, sem cota, sem nerfarem seu modelo. Opensource. Esse modelo aqui: huggingface.co/unsloth/Qwen3.…
English
@nahcrof your page shows monthly fees, then token fees on the same page. am i paying both?? only one??

English
English

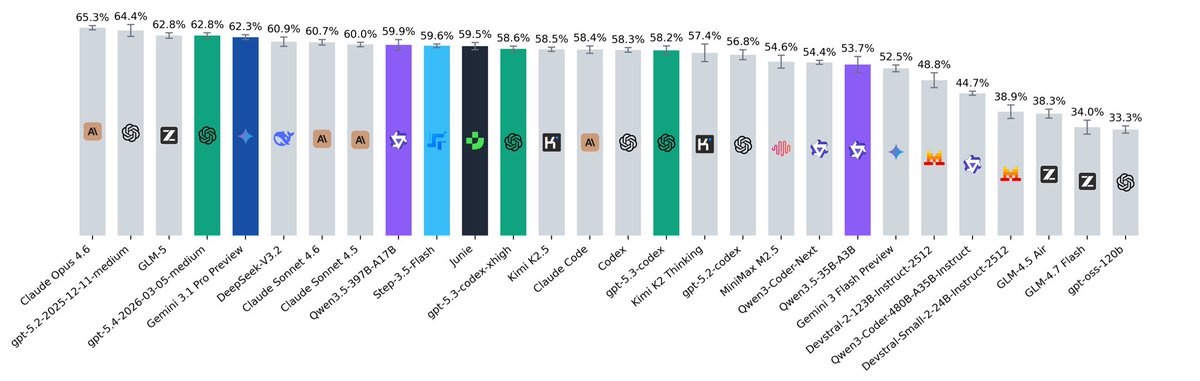
🚨 SWE-rebench update!
SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub every month.
updates:
> we removed demonstrations and the 80-step limit (modern models can now handle huge contexts without getting trapped in loops!).
> we added auxiliary interfaces for specific tasks like in SWE-bench-Pro to evaluate larger tasks fairly, ensuring valid solutions don't fail just because of mismatched test calls.
insights:
> Top models perform similarly. Among open-source options, GLM @Zai_org shows strong results, and StepFun @StepFun_ai is very cheap for its performance level ($0.14 per task).
> GPT-5.4 shows high token efficiency, it ranks in the top 5 overall but uses the lowest number of tokens (774k per task)
> Qwen3-Coder-Next & Step-3.5-Flash benefit massively from huge contexts. Qwen is an extreme case, averaging a wild 8.12M tokens.
> We evaluated agentic harnesses (Claude Code, Codex, and Junie) and found a few things. Even in headless mode, they sometimes ask for additional context or attempt web searches. We explicitly disabled search and verified their curl commands to ensure they aren't just pulling solutions from the web.
🏆 You can find the full leaderboard here:
swe-rebench.com
👾 Also, we launched our Discord!
Join our leaderboard channel to discuss models, share ideas, ask questions, or report issues: discord.gg/V8FqXQ4CgU
English
@theo Suggestion - when you promo, include more whole-app screenshots!
English

I hope you guys know that I tried pretty much every T3 Code alternative before building it.
I wanted something good, reliable, performant and OSS.
Best anything else hit was 2 out of 4. We hope to be the first to hit all four.
English
@bridgemindai Like I said in my last message to you, how can your benchmark be meaningful if any model can finish it in under 5 seconds?
English

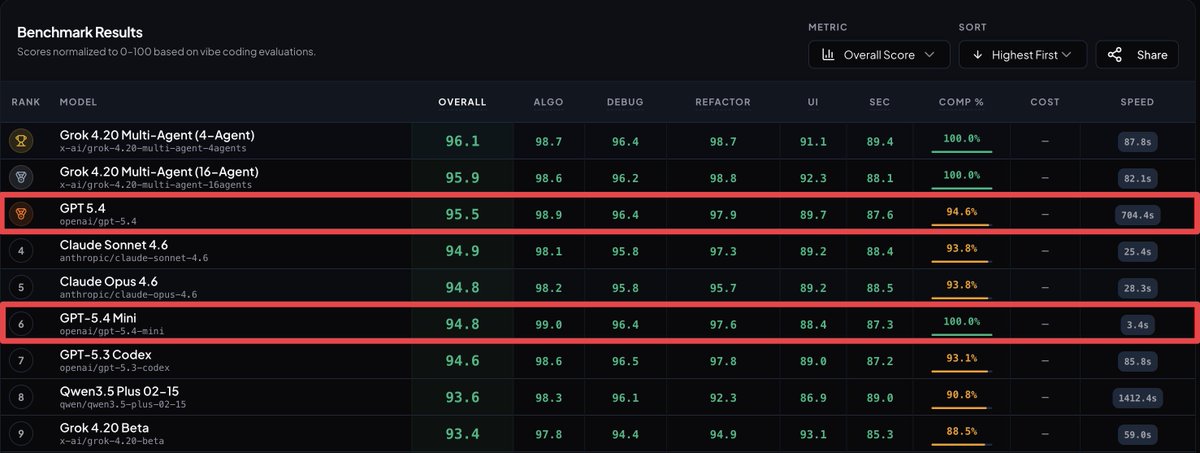
GPT 5.4 Mini completes BridgeBench tasks in 3.4 seconds.
GPT 5.4 takes 704.4 seconds.
207x faster.
100% completion rate.
Overall score 94.8 vs 95.5.
0.7 points of intelligence lost for a 207x speed increase.
Ranked #6 overall.
Ahead of GPT 5.3 Codex.
Ahead of Grok 4.20 Beta.
OpenAI got the mini model right this time.
bridgemind.ai/bridgebench
English