他这东西能看出来啥反思…
他intp能发展成这个样子推油们不如去看DSM-5来分析一下他…
Pure Nomad@realPureNomad
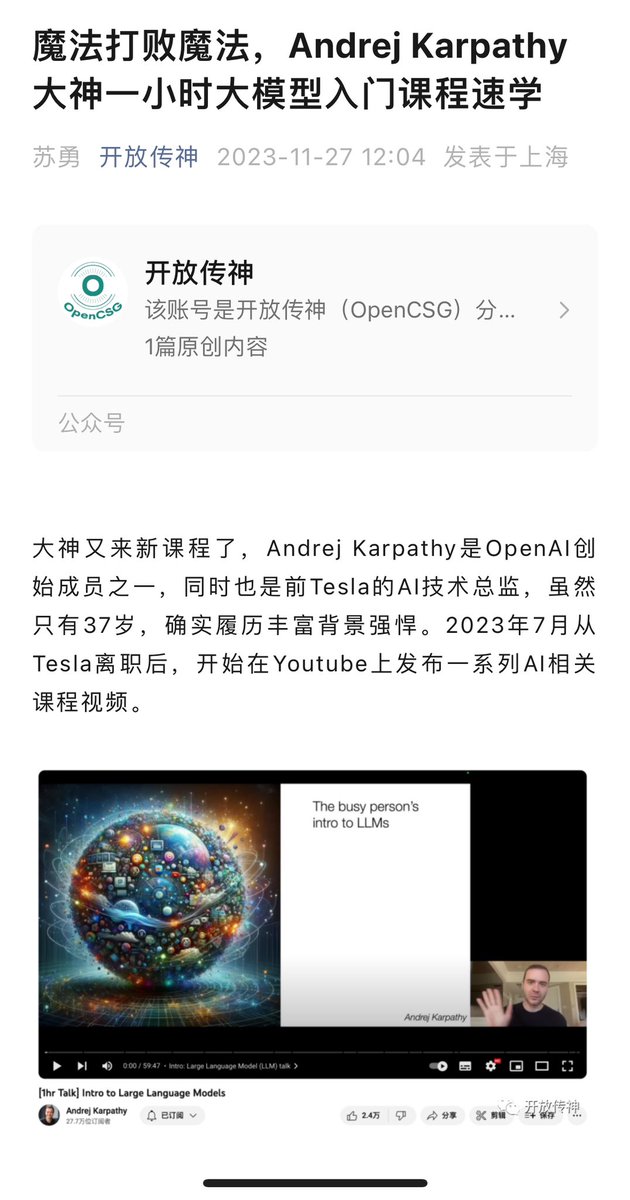
一口气看完了李新野的新作。 虽然表面上是在传播知识,实际上是对前女友和家庭成员的报复与泄愤(极端行为可由童年 Trauma 创伤解释)。但不得不说,它仍然有几分吸引人之处:其一,娱乐性十足;其二,的确也蕴含着对当下社会发人深省、震耳欲聋的反思。
中文
M007
113 posts

一口气看完了李新野的新作。 虽然表面上是在传播知识,实际上是对前女友和家庭成员的报复与泄愤(极端行为可由童年 Trauma 创伤解释)。但不得不说,它仍然有几分吸引人之处:其一,娱乐性十足;其二,的确也蕴含着对当下社会发人深省、震耳欲聋的反思。



6款可用于LLMs的爬虫工具/方案: 最近爬虫工具很多,整理了一个工具集合 1、Crawl4AI Crawl4AI可将语义标记的数据块提取成 JSON 格式,提供干净的 HTML 和 Markdown 文件,用于 RAG(检索增强生成)、微调以及 AI 聊天机器人的开发 Crawl4AI提供爬取功能和多 URL 支持,可轻松集成为库或服务器,并提供了 Docker 容器来简化设置 特点: 1、高效且提取有价值数据 2、适合LLM格式(JSON、清理后的 HTML、Markdown) 3、支持同时多个 URL 4、用 ALT 替换媒体标签 github:github.com/unclecode/craw… 2、FireCrawl FireCrawl能够抓取任何网站的所有可访问子页面,无需站点地图,并将内容转换为干净的Markdown格式 FireCrawl 与传统的网页爬虫工具不同,即使网站使用JavaScript动态生成其内容,FireCrawl 也能有效的进行抓取 此外,还提供了易于使用的API,使开发者能够通过简单的API调用实现内容的爬取和转换 github:github.com/mendableai/fir… 3、Scrapegraph-ai Scrapegraph-ai使用 LLM 和直接图形逻辑为网站和本地文档(XML、HTML、JSON 等)创建抓取流程 用户只需要指定想要提取的信息类型,ScrapeGraphAI 库就能自动执行数据抓取的任务 github:github.com/VinciGit00/Scr… 4、Markdowner 一个快速的开源工具,可以将网站转换为 Markdown 数据 支持自动爬虫、详细模式、javascript网站等 易于扩展和自托管,运行成本低 github:github.com/dhravya/markdo… 5、Jina Reader Jina Reader可以将任何 URL 转化为 LLM 所需Markdown格式 可以针对这些内容集成不同的模型,支持 API github:github.com/jina-ai/reader 6、Skyvern 支持自然语言进行网页导航、过时/电商网站的数据爬取、填写表单等复杂多步操作 支持绕过 CAPTCHA/Authentication 等验证操作 支持API 调用/Debug 模式 github:github.com/Skyvern-AI/sky… #Crawl4AI #FireCrawl #Scrapegraphai #Markdowner #JinaReader #Skyvern














"This is a common pattern in C programming when you have nested structures and you want to retrieve the parent structure from a pointer to the nested structure."