Max 🏴☠️
1.8K posts


Max 🏴☠️
@Maximillion_R
Unfiltered tokens straight out of my own neural network. Some weights, all bias. 🔥 Nomadic sort of VT'19→TX→SD→EC→SF→SEA→SF


A Chipotle burrito costs $15. Ground beef is $7 a pound. Inflation is financially crippling Gen Z. Once again, an out-of-touch rich boomer is lecturing young people.



State of SF housing: this entire room is available for $2775/mo. (The bathroom is behind the wall)




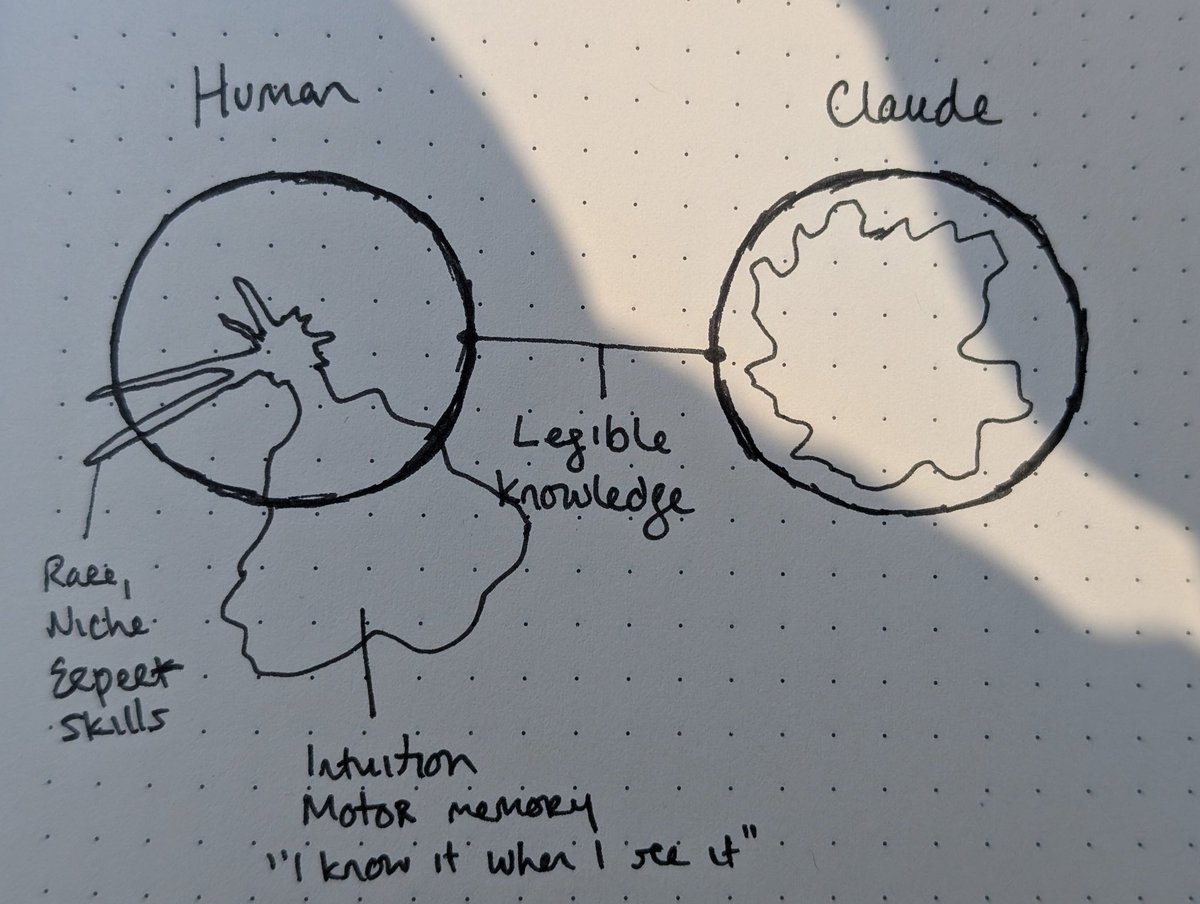
Just because anyone can build software now doesn't mean software is dead. Anyone can bake bread in their home right now, yet 99% of us still choose to buy it from someone else. Simple products are complex! I will always be happy to pay someone to handle the nuances.





@iamgingertrash @0xSero @itsalltruffles Yes please do! What a great purchase! Thank you! @itsalltruffles @iamgingertrash 🦾


Chinese quant built a simulation of how SPX price reacts to any global event. He’s already made over $100k - with full blockchain proof. He knows exactly where price will go. More than 40 years of SPX trading history have been loaded into MiroFish simulator (18k stars on GitHub) AI analyzed every single moment in that trading history. Now this guy has a fully functional SPX price prediction system. His wallet: @moisturizer?via=cvxv666" target="_blank" rel="nofollow noopener">polymarket.com/@moisturizer?v…
Dozens of successful SPX price-prediction trades and hundreds of tests across other stock markets. Here’s exactly what you need to replicate his stack: - market data APIs (SPX price, use Alpha Vantage or Quandl) - data pipeline (use Python) - feature engineering (for output signals like RSI, MACD) - seed dataset for MiroFish (convert data into structured context) - multi-agent simulation (macro strategist, earnings analyst, sentiment analyst agents etc.) - probability forecast (run different scenarios) - trading / decision Model (SPX futures ES, SPY ETF) Save this pipeline if you want to run a similar simulation on your own data. You can feed the whole thing to your Claude and build your first (even small) simulation model together.
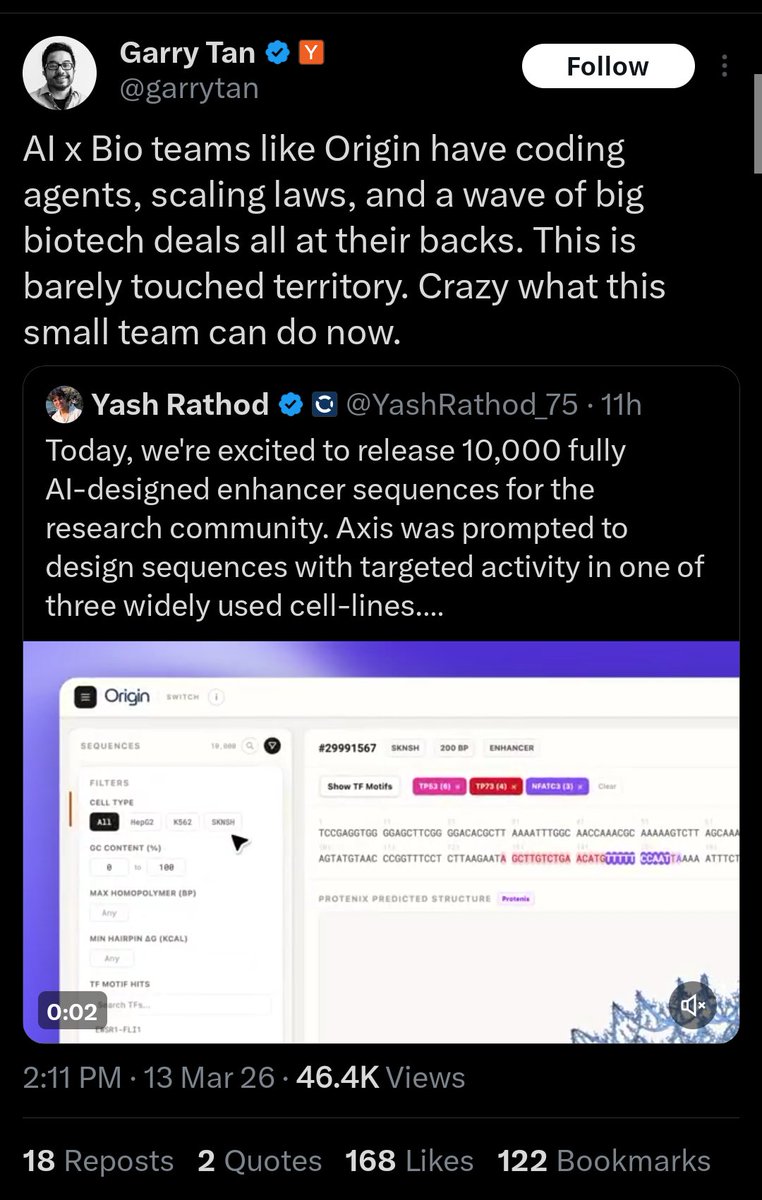
@garrytan It's always nice to see more people in this space, but "barely touched territory" seems exaggerated. To design these enhancers, they use a model from a paper that also does AI-based enhancer design! And they provided wetlab validation of their sequences.

I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)



