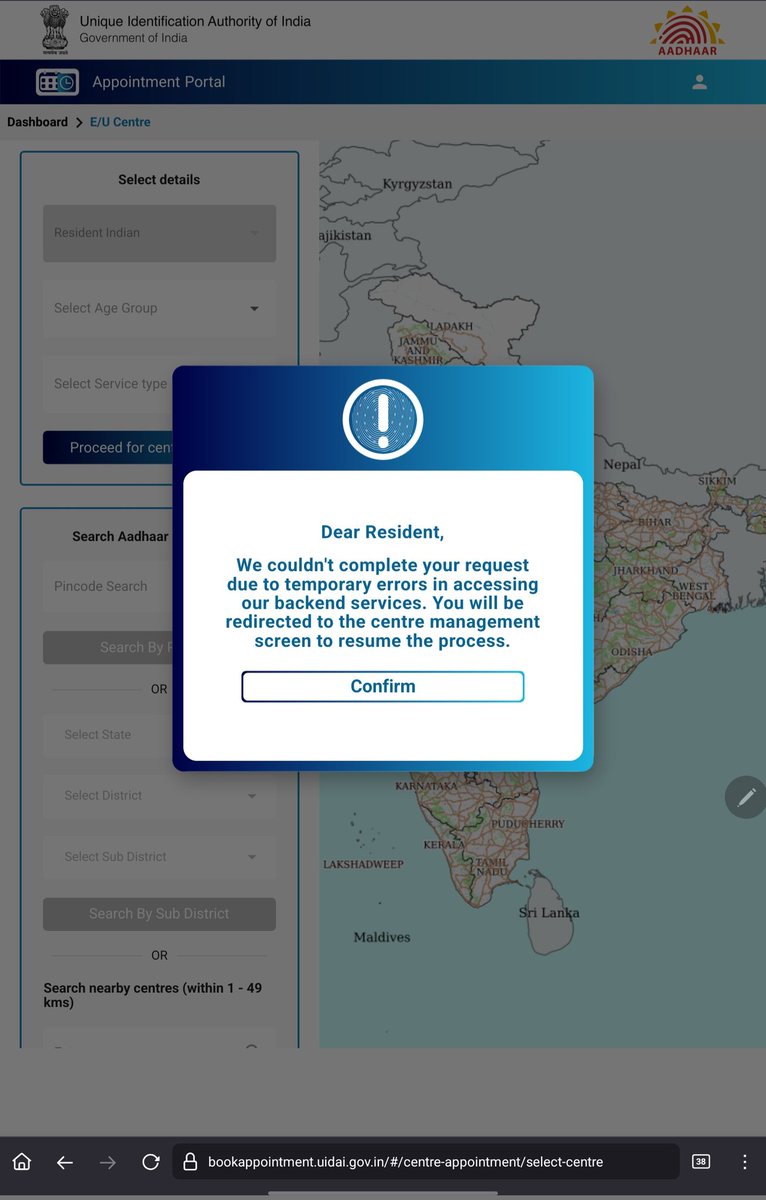
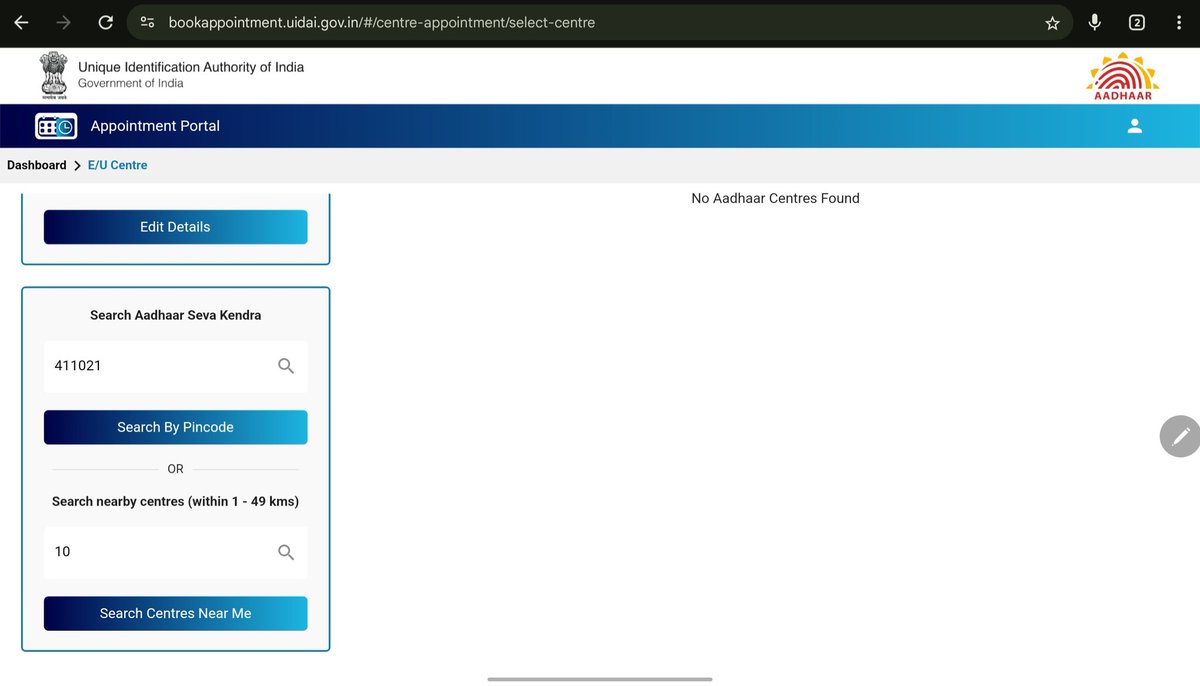
AMAR P. retweetledi

Just putting the two Gemma 4 variants side by side here for easy reference.
#architecture-diff-tool" target="_blank" rel="nofollow noopener">sebastianraschka.com/llm-architectu…

English
AMAR P.
140 posts


@MeAmarPotdar
To make this world a better place, One code at a Time. Generative AI , Deep Learning, Computer Vision.