Sabitlenmiş Tweet
Meetem
2.9K posts
Meetem
@Meetem4
C# lover and Unity Performance Maniac. | 🇺🇦 переможе | Cutting milliseconds for money | https://t.co/M0cMRkjVv6
Belgrade, Republic of Serbia Katılım Ocak 2023
336 Takip Edilen396 Takipçiler
@yak32 @playcanvas That’s really good, you just have to bake lightprobes so dynamic objects will match the scene lighting! Amazing!
English

I finally finished my Gaussian Splat based FPS demo.
It's a @playcanvas project, runs in a browser. On a real photoscan. With physics, baked lighting, pathfinding NPCs.
Here's how 👇
English
@andkalysh Very nice job! Where can I read more about that implementation?
English

That’s true. I’ve asked Josh Peterson if they will remove compacting from GC, and he atm told no. I think I would’ve just remove the compacting entirely and it’s quite easy to do in coreclr.
On IL2CPP perf though I don’t think IL2CPP will beat coreclr nativeaot in all the circumstances
English

People are a bit confused by the CoreCLR news
CoreCLR is great news for newer c# adoption and compatibility but:
1) I still have to see how the new GC system is implemented. They have already said they are going to need a custom GC because .net GC is not meant for games
(more)
Unity for Games@unitygames
Get ready for a Unity 6.8 alpha coming later this year, as we prepare for the entire ecosystem to take full advantage of CoreCLR for faster iteration times and reduced wait times for incremental changes.
English
@SebAaltonen Interesting, last time Ive checked structured buffers in Compute pipeline they were a little bit faster. Probably they are using a different path in compute. Interesting why is that.
English

Nvidia is one of the few vendors who still have IA. But Turing (RTX 2000) added fastpath raw loads (~3x lower latency vs sampler) and 2x L1$ bandwidth for raw load paths. So you just use that. Performance is practically the same. But don't use typed buffers, those go though the sampler = higher latency and lower throughput.
English
This reminded me that I should kill vertex buffers and vertex input assembly setup APIs in our RHI. We no longer need GLES backwards compatibility.
Vertex vertex = buffer.vertices[gl_VertexID];
Tech Bro Memes@techbromemes
English
@SoftEngineer Ah, Ive got it. I did something similar for Unity implementing NICE filter on gpu. Constructing a little smaller kernel and take max(currentMip-3, 0) as a source
English

On the mipmap generation? Well, there are a few things here. In real-time scenarios you're typically forced to run small filter kernels, like 5x5 is already large. A typically linear mipmap (basic standard) is 2x2 kernel.
When we generate mipmaps offline - we can always start from mip0 (highest resolution), and run progressively larger kernels all the way. You get best results this way, but it's slow. And it doesn't scale for GPUs.
If you just run recursive filter, that is filter mip0 to mip1, then use the same filter on mip1 to get mip2 etc. You get a pretty blurry result, because at each stage you're destroying some information.
So with all that - my mipmap generator cheats, instead of going all the way to mip0 which is too expensive, it goes back a few mip levels, where you still have more detail and information. The kernel gets larger, but in acceptable range. I also don't use the basic linear filter. This, however, creates a conundrum where you want to run a complex filter, but not recursively. So my mechanism is split into optional forward and backward passes. Backward pass is optional, it only kicks in when needed by the requested filter.
To maybe better illustrate the system, here's a processing spec for mitchell filter:
---
[TextureFilterType.Mitchell]: FilterProcessDescriptor.from({
filter: FilterShaderType.Mitchell,
skip_distance: 2,
base_filter: FilterShaderType.MagicKernelBase,
})
---
Beyond this, the mipmap generator has a scheduler, where it runs a bit of the mipmap workload at a time each frame, which prevents the main thread from locking up. There's a fair bit of complexity related to memory management and keeping drawcall overhead to the minimum.
English
Sponza scene, in Shade (WebGPU graphics engine).
Was working on mipmap texture filtering. It's one of those things that can be a time black hole, but when we can improve image clarity - I can't help but feel like it's worth it.
I guess my mipmap generation system in Shade is the most sophisticated mipmap system on the web. Perhaps a bit of an overkill but I'm super happy with the results.


English
@unitygames Will runtime be opensourced and easily recompilable as an original dotnet repo?
English

Get ready for a Unity 6.8 alpha coming later this year, as we prepare for the entire ecosystem to take full advantage of CoreCLR for faster iteration times and reduced wait times for incremental changes.
English


There are now two full (all 14 block size) open source ASTC LDR GPU texture encoders in the world: ARM's and Binomial's. We also support ASTC HDR 4x4 and 6x6 with high quality specialized encoders.
github.com/BinomialLLC/ba…
English
@Mirko_Salm Probably just use SH? I haven’t even knew they’ve patented that!
English

@AlperenAkkuncu We became closer to God. E.g. to the glass weights and lightspeed inference
English

Apparently, there is new hardware that can run LLMs much, much faster. It can easily give you over 15,000 tokens per second, which is stupidly fast.
From what I understand, it's 'hard-coded,' meaning that you can't change the weights or anything; the chip itself can only run the model from the day it's manufactured, forever.
Interesting concept.

English
Meetem retweetledi

Продолжая тему взвешенного подхода к использованию AI. Наткнулся тут на интересную заметку - "Breaking the Spell of Vibe Coding". Довольно интересный текст о рисках бездумного вайбкодинга. Всем разработчикам (и не только им, конечно) известно понятие flow state ("состояние потока"), то самое, когда хорошим программистам удаётся "своротить горы". Автор статьи рассматривает вариант этого состояния - dark flow, типа того, что испытывает лудоман, взаимодействуя с игровым автоматом, и утверждает, то же самое человек испытывает при вайбкодинге - когда ты вообще не смотришь на результирующий код, но крайне увлечён реализацией своей наверняка великой идеи. В результате такой работы получается "дом на песке", некая конструкция без внятной архитектуры, с кучей воркэраундов и багов, разваливающаяся под собственным весом по мере роста объёма кода. Примерно тот же результат, если вдуматься, что и у лудомана с голой жопой и коллекторами у входной двери.
Думается мне, что что-то в этом есть.
Русский
@James_M_South Getting a better performance for drawing is usually simple, what’s complicated is getting results back without a huge delay from GPU while also maintaining the frontend similar to CPU
English

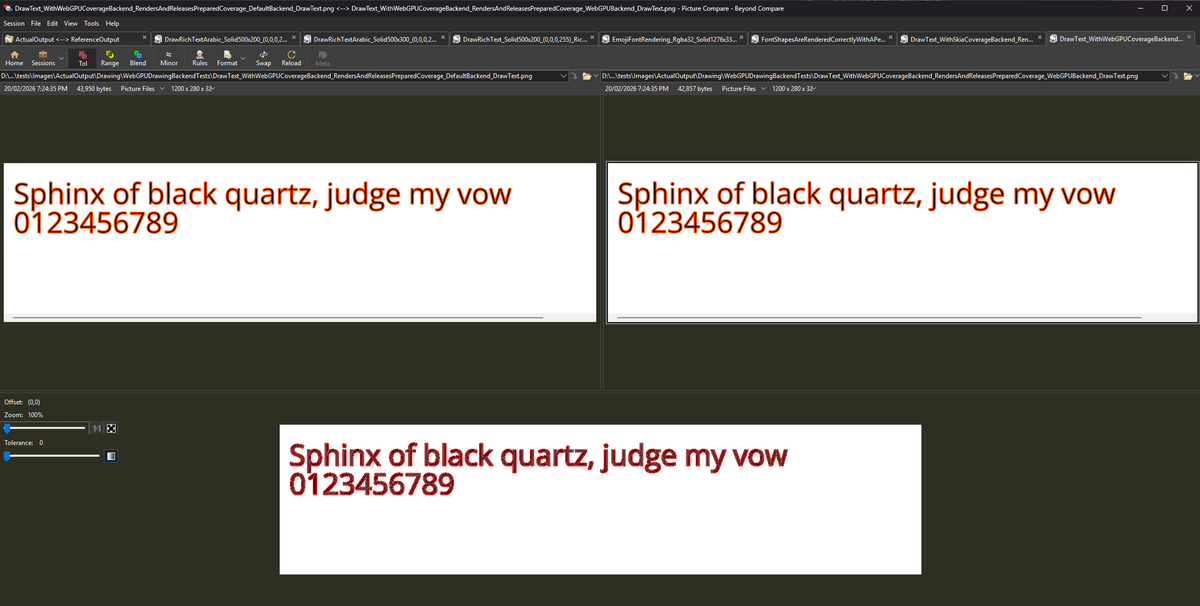
Writing a GPU drawing backend is REALLY difficult.
I can get it rendering but not there with the perfomance yet. My new parallel CPU rasterizer is still a touch faster
English
@unitycoder_com Yeah funny thing they are still using cpu to submit drawcalls, and only sub cull draw calls with occlusion culling. Sorting/filtering is basically impossible to get done on gpu with the current API design. At least when I checked it (~half year ago)
English

unity survey about "GPU Resident Drawer" discussions.unity.com/t/feedback-nee…
English
BTW Unity DXR is broken because they are using per-material variant to bind textures (sic!) instead of using bindless.
So it’s hell as slow.
Gabriel Dechichi@gdechichi
just wrapped up the PBR path tracer for my engine, and looks like it's about 5x faster than @UnrealEngine and 12x faster than @unity for the same scene. goal is to make this real time
English
@marcel_wiessler @guycalledfrank @pemathedev years of unsupported binding MRTs without depth buffer (while there are no gfx api which don’t allow that):
discussions.unity.com/t/setting-mult…
English

Do you also dislike how Unity's WheelCollider only casts 1 center ray, so cars jump on every tiny bump?
Did you also see 3rd-party assets doing like 16 rays per wheel and thought maybe it's kinda expensive?
Did you know that PhysX can actually sweep convex shapes instead of rays?
English