AshutoshShrivastava@ai_for_success
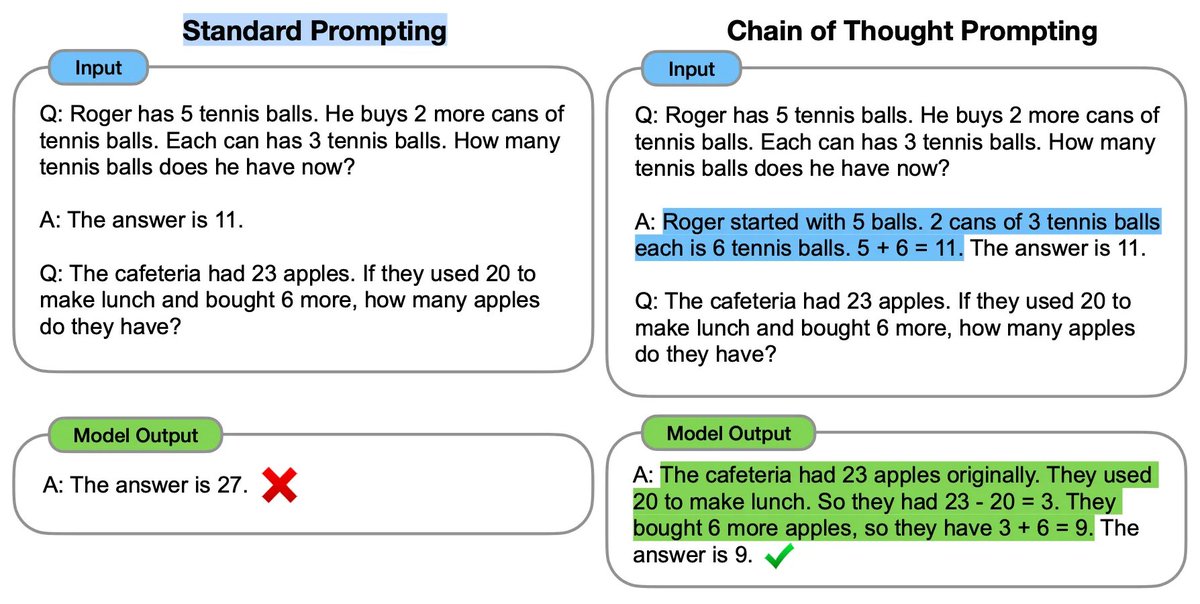
DALL-E-3's most significant feature update: Learn how to work with seed values.
🔖 Bookmark this! You won't want to miss it. Share with others so they don't miss out either.
Hello everyone! This is the GOLD you won't find anywhere else.
As you all know, I spend my day experimenting and creating images with DALL-E-3
Today, I discovered something new that DALL-E-3 now allows us to use seed values. If you've been working with DALL-E-3, you'd be aware that previously the seed number wasn't functional, and it was fixed at 5000.
However, today I found out that we can actually specify a seed number. This means with the same prompt and seed, you can consistently generate the exact same image in diffrent chat instance.
You might wonder how I discovered this. Previously, DALL-E-3 would produce the same image for a given prompt every time because the seed was set in the backend. However, today, when I tried HOPE old prompt, they didn't produce the expected results. This led me to investigate further, ultimately leading to this discovery.
Let me show you how it works :
Let's prepare our chatgpt first :
First of all set your custom instructions to this :
@ DMP " means: do not in any circumstance modify my prompt, please create image using this prompt:
Also, use wide aspect ratio by default and when you generate an image, always provide the seed number details for that image after it's rendered.
Note: In DALL-E-3, the aspect ratio influences the final result, even if you provide a seed. Therefore, ensure you use the same aspect ratio when specifying a seed.
What does this custom instruction do?
It forces ChatGPT to never modify your prompt and to generate content based on exactly what you provide. By default, it uses a wide aspect ratio and returns the seed number. Sometimes, it might make errors. So, while working, you can ask, "Do you know what DMP means?" Once it replies, you can instruct it to proceed accordingly, ensuring it functions correctly.
Let's create image now
For example, if I request "DMP:dog", it uses the exact same prompt and provides me with an image and the seed number: 1840089640.
Now, open a different chat instance of DALL-E 3 and enter the command as follows: "DMP Prompt:dog, Seed: 1840089640". It will provide exact same result.
Now, change the seed and observe the result. My updated command is "DMP Prompt:dog, Seed: 1844489640", where I have altered the seed number. You'll notice a different outcome.
Now, I went to a different chat instance and entered the same command without specifying the seed value. It generated a different image and returned a new seed value. You can use this seed and prompt to generate same image again
That's all for today. Follow me for future updates, cool AI discoveries, and the best ways to write prompts. Share this with others.