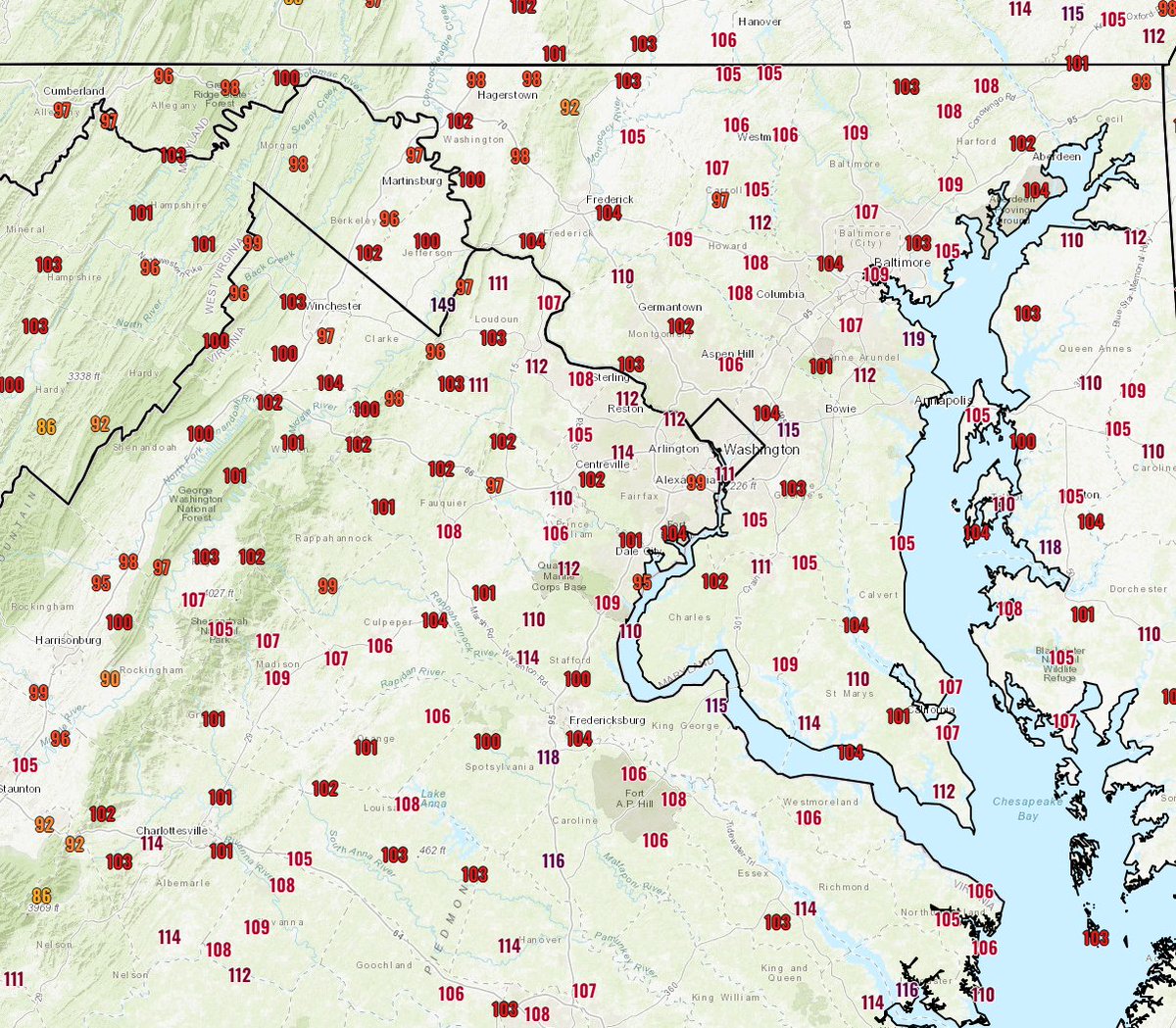
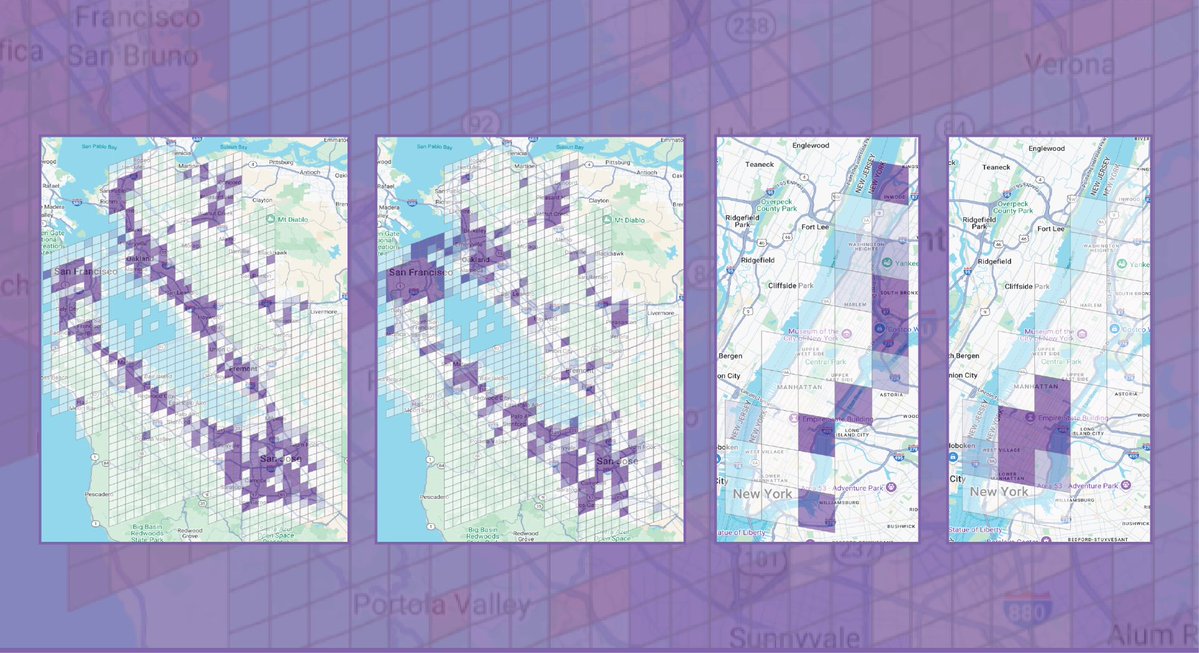
@GoogleResearch Inb4 they contrast it with natural language to do multimodal search:
> give me the location with the most tim hortons in walking distance possible
English
Nathan
421 posts
@NathanJLeRoy
Research @ Qdrant, PhD @ UVA













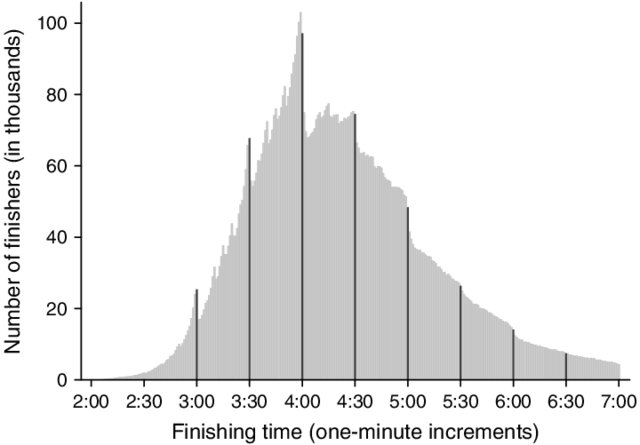
No, look at *this* distribution of z-values from medical research! (329,601 z-values from Cochrane database)