Sabitlenmiş Tweet

Superintelligence isn't about discovering new things; it's about discovering new ways to discover
I think our latest work formalizes Meta Chain-of-Thought which we believe lies on the path to ASI
When we train models on the problem-solving process itself—rather than the final solution—they internalize how to think about reasoning tasks, not just what to think
The next wave of AI is a Meta-CoT loop. We can't predict what novel forms of thinking might emerge, but it points to an extraordinary synthetic future
I'm so proud of @synth_labs team & our incredible open science collaborators for getting this work out
Rafael Rafailov @ NeurIPS@rm_rafailov
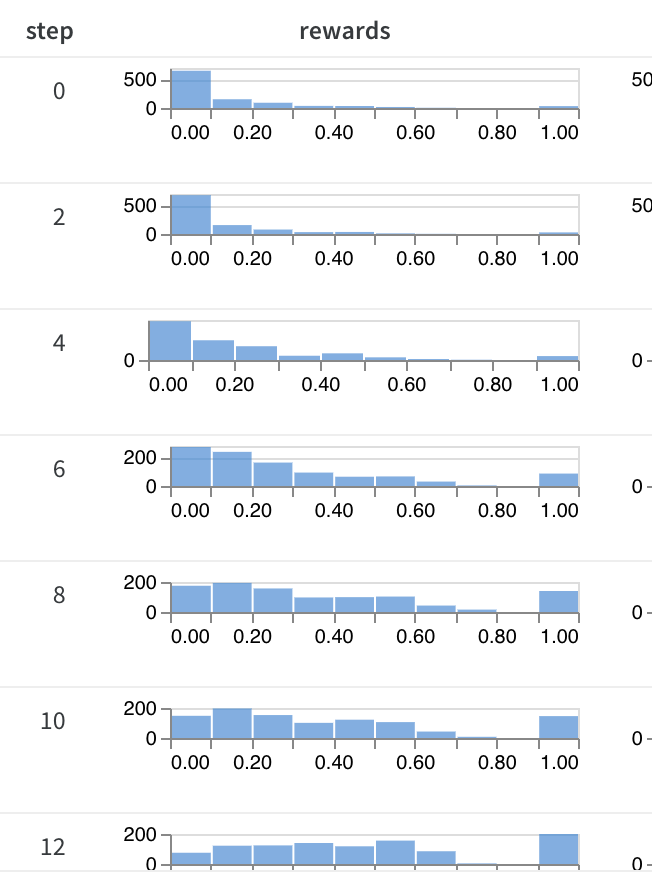
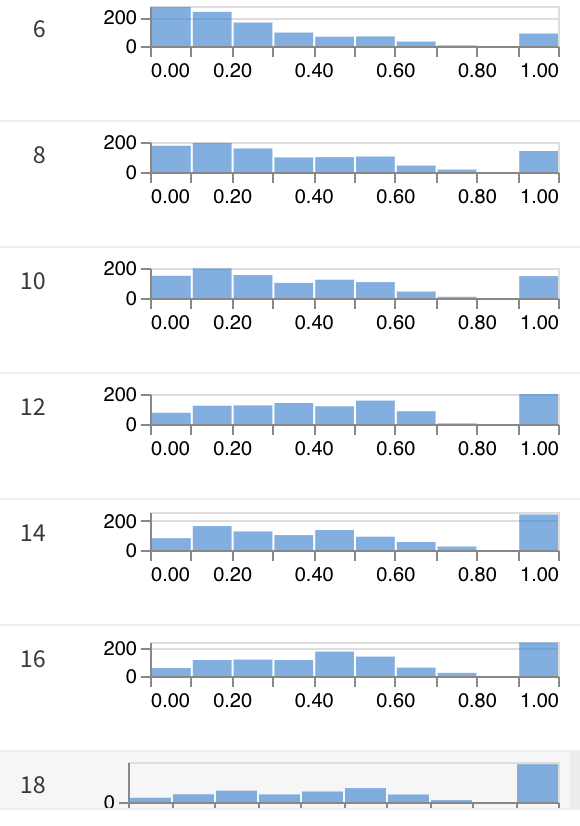
We have a new position paper on "inference time compute" and what we have been working on in the last few months! We present some theory on why it is necessary, how does it work, why we need it and what does it mean for "super" intelligence.
English