Nipsuli
268 posts


Nipsuli
@Nipsuli
Product Engineer | ML & AI Systems | Founder Opinions are my own
Katılım Temmuz 2009
457 Takip Edilen59 Takipçiler
@mitchellh I've seen codex now few times go and check source of dependencies while trying to fix things. That's freaking amazing, when it actually checks how things work instead of relying on sometimes limited documentation on some behaviors
English

Ahhhh, Codex 5.3 (xhigh) with a vague prompt just solved a bug that I and others have been struggling to fix for over 6 months. Other reasoning levels with Codex failed, Opus 4.6 failed. Cost $4.14 and 45 minutes. Full trace plus includes original issue: ampcode.com/threads/T-019c…
I know this prompt is relatively bad. Honestly, our stable release is in a week, and I was throwing some Hail Marys at the frontier models to see if I could get a clean, understandable fix for some of these bugs. By using `gh`, it grabs much better context from the issue, so its not terrible.
The best thing that Codex did was eventually start reading GTK4 source code. That's where I ended up (see my GH issue), and I knew the answer was somewhere in there, but I didn't have the time or motivation to do it myself. The other models never went there, and lower reasoning efforts with 5.3 didn't go there either. Only xhigh went there. I think that was a critical difference.
The final fix was decent. It was small, all in a single file, and very understandable. It had one bug I identified (you can see in the trace), and then I manually cleaned up some style. But, it did a great job.
Definitely an "it's so over" moment. But at the same time, it feels amazing because now our next stable release will have this fix and I was able to spend the time working on other fixes as it went.
English

11/
I also made a comic version of this paper. Sometimes a picture is worth a thousand tokens.
(And sometimes Image Gen models do their own mistakes)
#MachineLearning #AI
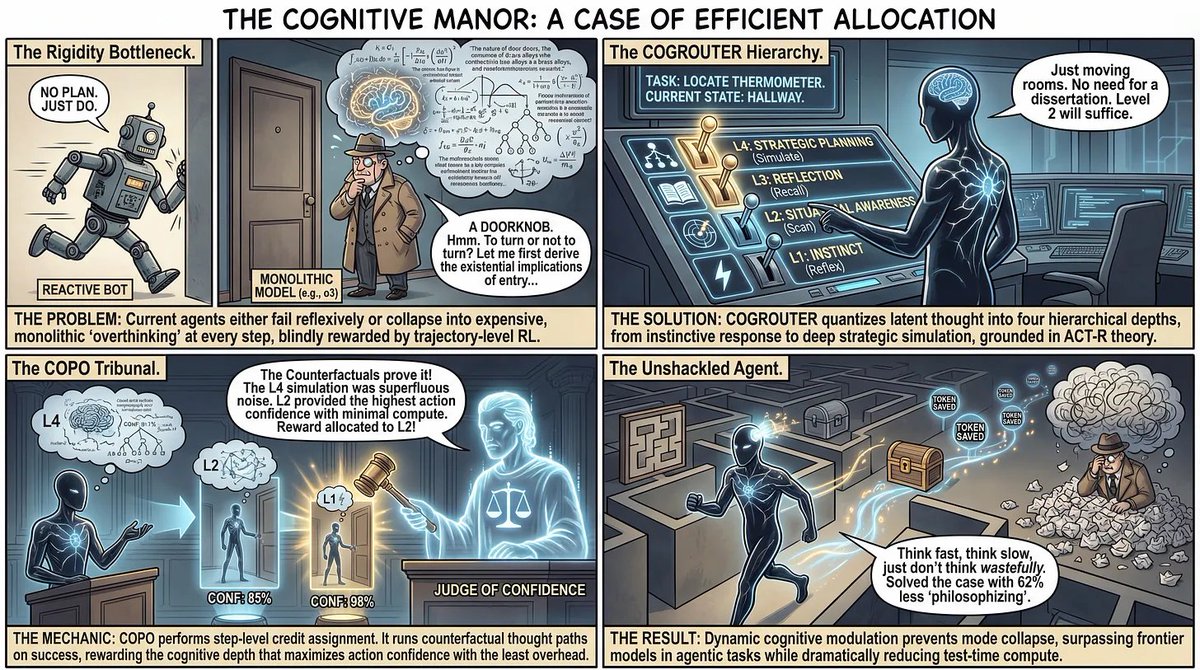
English
1/
Frontier models like o3 and DeepSeek-R1 have a fatal flaw: cognitive rigidity. They use expensive Chain-of-Thought for every single step.
A new 7B model just beat o3 on agentic tasks using 62% fewer tokens by fixing this.
🧵

English
@BingBongBrent The code approach mentioned on the website is really cool. Been thinking a lot about code as part of the thinking process of models and how to utilize that kind of approach more
English

Today we're introducing Confluence Labs - an AI lab focused on learning efficiency.
Our first project has been to saturate ARC-AGI-2.
Over the past few years I've seen AI do things that I never could've possibly dreamed of, but it's impact has been limited in data-sparse domains like physics, biology, and robotics.
That's why we started Confluence Labs, and what we hope to work on with this company.
Y Combinator@ycombinator
.@_confluencelabs is coming out of stealth with SOTA on ARC-AGI-2 (97.9%). They're focused on learning efficiency — making AI useful where data is sparse and experiments are costly. Read more at confluence.sh Congrats on the launch, @BingBongBrent and @bankminer78! ycombinator.com/launches/PWR-c…
English
@penberg @jazz_tools In general I see cases where isolated compute + storage makes sense a lot with all kinds of agentic coordination work.
English
@penberg With my AI notes app (in maintenance mode now, run out of money 😔) I have all the app data with @jazz_tools and all the agentic stuff in durable objects, and I use the DO Sqlite as storage for Jazz to speed up loading things. I also contributed that feature to Jazz
English

If you're using SQLite with Cloudflare Durable Objects, I would love to hear why you're using that over D1. What workloads benefit from this approach the most?
English
@samlambert @stuxnet_vt Build once a graph based solution with branches and merges and per branch undo log on top of postgres. Heavy use of json and json patch as the diff mechanism. Did also js execution in pg for this... fun times
English

@stuxnet_vt its probably better to fake the versioning rather than having something git style. just append versions to a table and select the recent one.
English

.@samlambert - nerd snipe question on DB design - for something like a local only but fully featured knowledge graph backed by a sharded vector DB + Document DB - I’m thinking a Git like versioning control might be useful.
Users could checkout a version, branch, etc. Less time fighting weightings, correcting bad data when agents get off track, etc.
Overkill?
English

Turned down a sponsor deal because the company didn’t feel like a good fit for my audience. Biggest amount of money I’ve ever seen in one place.
I won’t lie, it hurt a bit. Holding strong to make sure I only show you guys cool products 🫡
English
@dom_scholz @xBenJamminx This is so freaking cool! Been thinking about all kinds of game analogies related to managing work. Like instead of having task list I manage quest journal
English

The natural UI for skills?
A skill tree 🌳
Guillermo Rauch@rauchg
In love with this aesthetic skills.sh
English
@_m27e @crunchydata I can’t remember the exact way I did it, but I’ve once in my life abused explain to do this. The filtering columns did have index so it was accurate enough
English

@crunchydata The problem I've always had here is that you rarely count an entire table. Usually, you want to estimate a subset of it, e.g. row count for a particular tenant. Wish there was an easier way to do that tbh.
English

Need to count all the rows in a huge Postgres table?
SELECT count(*) FROM table;
That can be slow. You can ask the internal tables too.
SELECT reltuples AS estimate FROM pg_class WHERE relname = 'table';
This is an estimate, but pretty close.
English

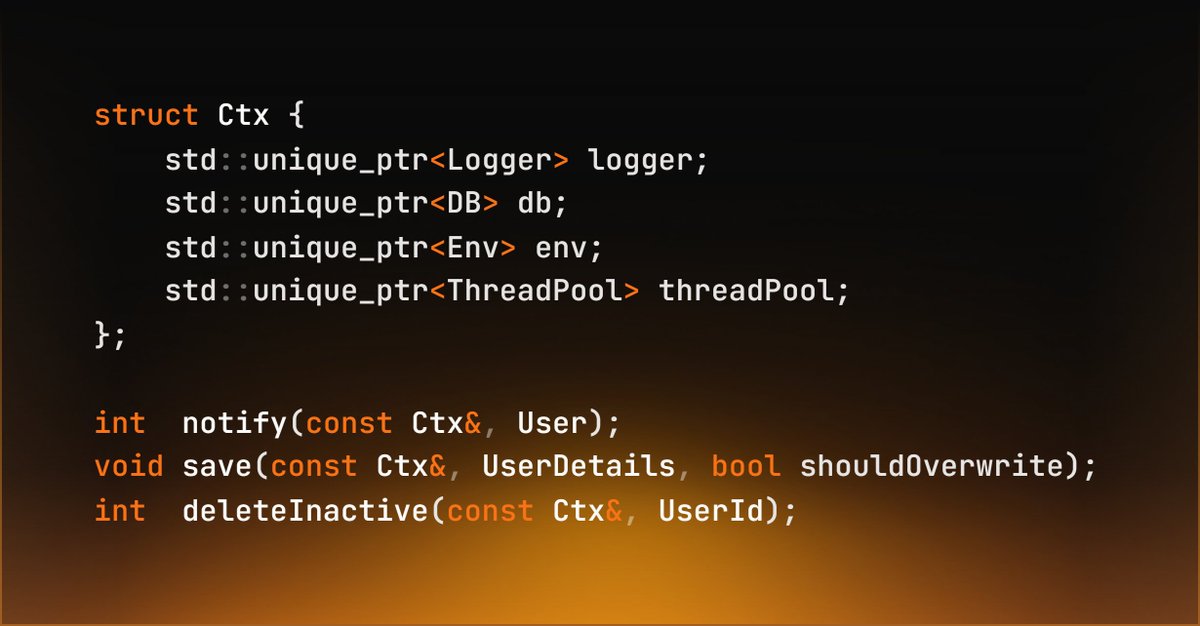
After 8 years of Haskell, 2 years of OCaml, 2.5 years of C++ and 45 minutes of Go, I present you the ultimate Design Pattern.
The Context Pattern
FP, OOP, Procedural and Declarative Programming combined to create The Last and Only design pattern you ever need.
A single record containing all your dependencies that you pass to every function explicitly.
No more inheritance.
No more classes and methods.
No more Dependency Injection.
No more singleton pattern.
No more private/public.
Mocks have never been easier.
This is the only pattern you need to structure EVERY SINGLE APP NO MATTER THE INDUSTRY (microservice, compiler, spaceship system).
English
Just released AgentFS 0.4.0 with copy-on-write overlay support! Turns out getting COW semantics right across Linux and macOS is pretty interesting problem. Full story: turso.tech/blog/agentfs-o…
English
@mitchellh Great example of how it’s always about the people not about the tool. Same tools can be used in many ways, only some of which provide value. But damn that’s great story
English
Slop drives me crazy and it feels like 95+% of bug reports, but man, AI code analysis is getting really good. There are users out there reporting bugs that don't know ANYTHING about our stack, but are great AI drivers and producing some high quality issue reports.
This person (linked below) was experiencing Ghostty crashes and took it upon themselves to use AI to write a python script that can decode our crash files, match them up with our dsym files, and analyze the codebase for attempting to find the root cause, and extracted that into an Agent Skill.
They then came into Discord, warned us they don't know Zig at all, don't know macOS dev at all, don't know terminals at all, and that they used AI, but that they thought critically about the issues and believed they were real and asked if we'd accept them. I took a look at one, was impressed, and said send them all.
This fixed 4 real crashing cases that I was able to manually verify and write a fix for from someone who -- on paper -- had no fucking clue what they were talking about. And yet, they drove an AI with expert skill.
I want to call out that in addition to driving AI with expert skill, they navigated the terrain with expert skill as well. They didn't just toss slop up on our repo. They came to Discord as a human, reached out as a human, and talked to other humans about what they've done. They were careful and thoughtful about the process.
People like this give me hope for what is possible. But it really, really depends on high quality people like this. Most today -- to continue the analogy -- are unfortunately driving like a teenager who has only driven toy go-karts.
Examples: github.com/ghostty-org/gh…
English

i wanted to make a group to talk daily research stuff, send papers, talk about AI news, who is interested? react or comment to be added
English
@minimax_ai Where’s the link to the VIBE benchmark? Am I blind or why I cannot find it 😅
English

MiniMax M2.1 is officially live🚀
Built for real-world coding and AI-native organizations — from vibe builds to serious workflows.
A SOTA 10B-activated OSS coding & agent model, scoring 72.5% on SWE-multilingual and 88.6% on our newly open-sourced VIBE-bench, exceeding leading closed-source models like Gemini 3 Pro and Claude 4.5 Sonnet.
The most powerful OSS model for the agentic era is here.
English
@rach_it_ @Meta @KempnerInst @astonzhangAZ @rish2k1 @Devvrit_Khatri @dvsaisurya @louvishh @brandfonbrener @elmelis This is cool, been thinking about test time training a lot recently
English

Current LLMs support contexts with millions of tokens. However, we keep seeing failure modes due to poor long-context reasoning.
Our new work shows that, for long contexts, we must perform test-time training updates rather than vanilla ICL or “thinking”!
w/ @Meta & @KempnerInst

English
AgentFS overlay is progressing well. You can run any command with "agentfs run" (including bash) and the current directory becomes copy-on-write, but rest of the system is read-only.

English