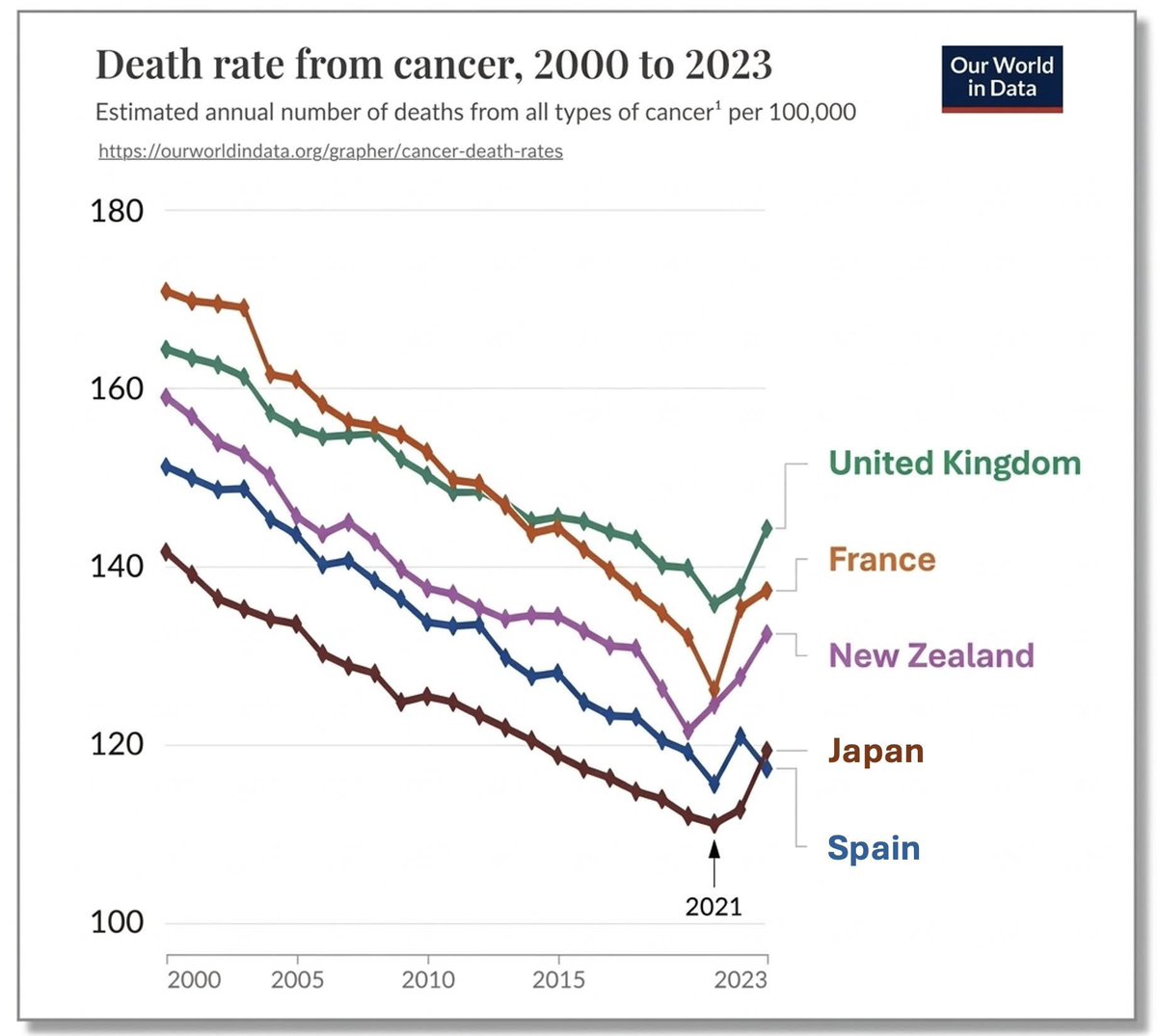
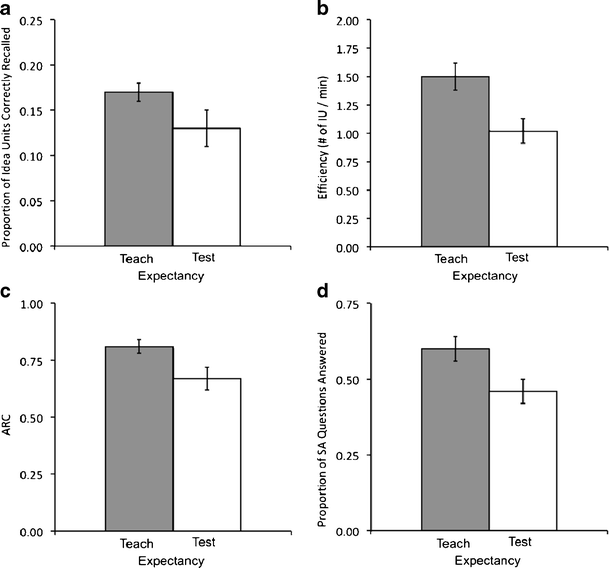
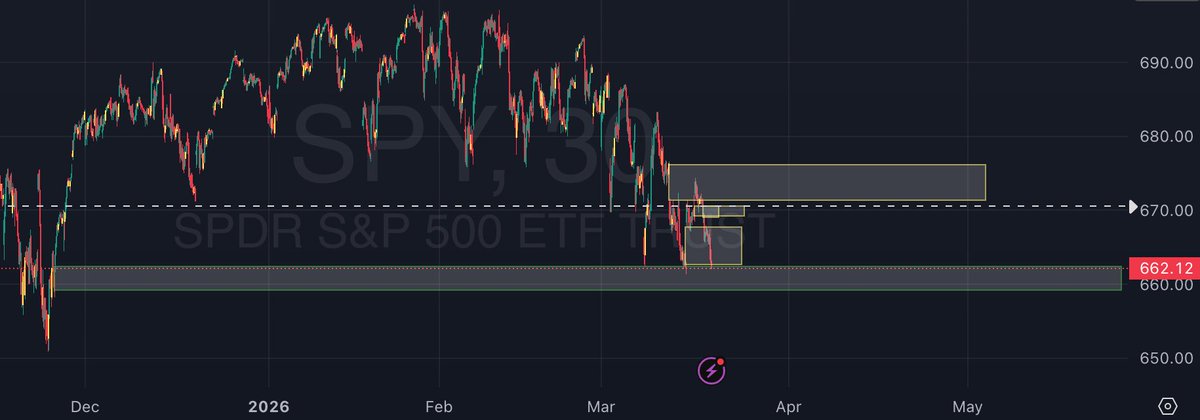
Sabitlenmiş Tweet

For everyone who complains that private companies keep getting richer and bigger,
last i checked you are allowed to buy a stake in their hard work without working for them.
So stop complaining about their smartly earned profits, Stop asking for welfare.
Invest, earn your share.
English