
Alessio
1.2K posts
Alessio retweetledi

🚨 BREAKING: Tencent has killed the “next-token” paradigm.
Tencent and Tsinghua has released CALM (Continuous Autoregressive Language Models), and it completely disrupts the next-token paradigm.
LLMs currently waste massive amounts of compute predicting discrete, single tokens through a huge vocabulary softmax layer. It’s slow and scales poorly.
CALM bypasses the vocabulary entirely. It uses a high-fidelity autoencoder to compress chunks of text into a single continuous vector with 99.9% reconstruction accuracy.
The model now predicts the “next vector” in a continuous space.
The numbers are actually insane:
- Each generative step now carries 4× the semantic bandwidth.
- Training compute is reduced by 44%.
- The softmax bottleneck is completely removed.
We’re literally watching language models evolve from typing discrete symbols to streaming continuous thoughts.
This changes the entire trajectory of AI.

English
Alessio retweetledi

Alessio retweetledi

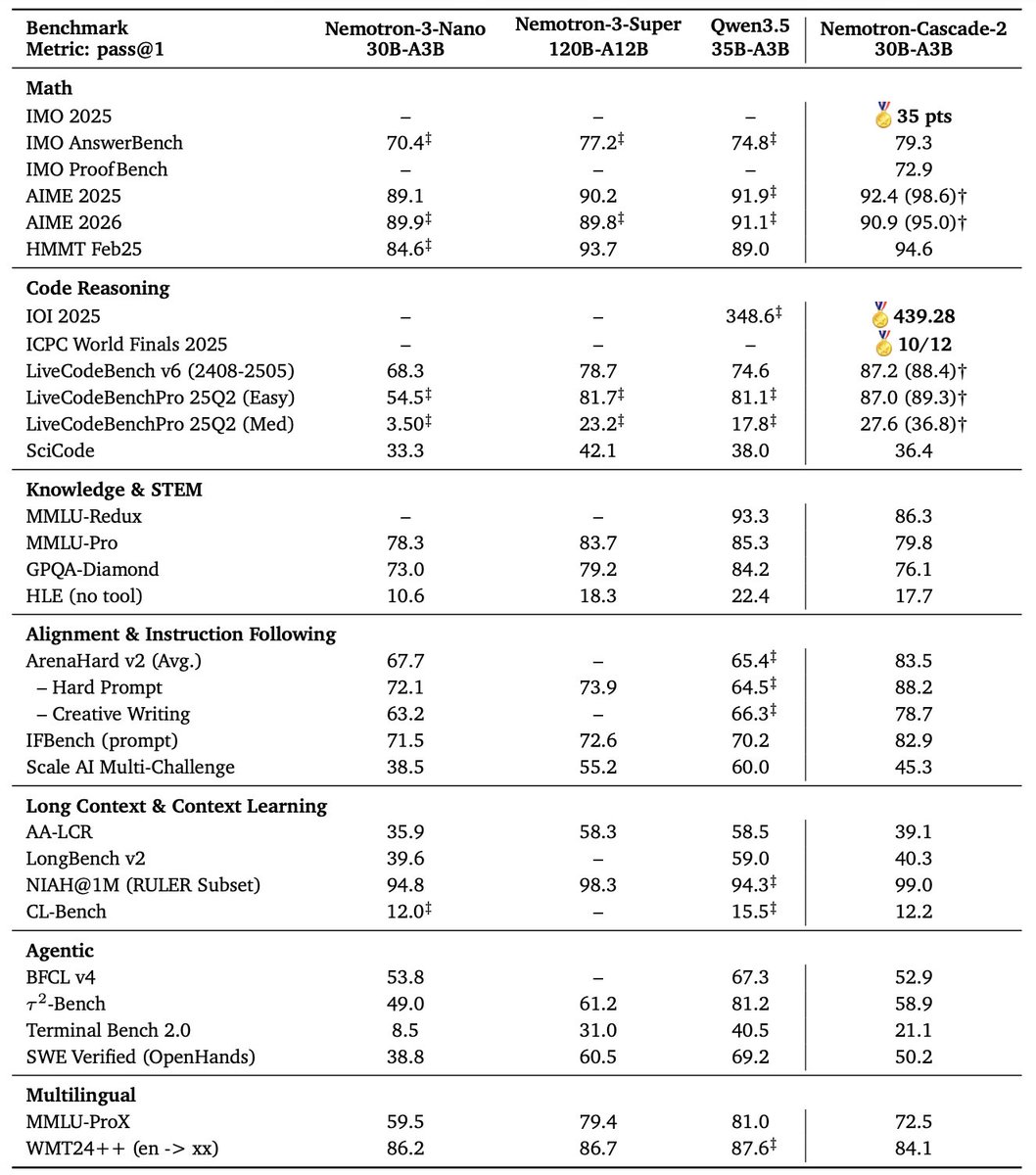
🚀 Introducing Nemotron-Cascade 2 🚀
Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities.
🥇 Gold Medal-level performance on IMO 2025, IOI 2025, and ICPC World Finals 2025:
• Capabilities once thought achievable only by frontier proprietary models (e.g. Gemini Deep Think) or frontier-scale open models (i.e. DeepSeek-V3.2-Speciale-671B-A37B).
• Remarkably high intelligence density with 20× fewer parameters.
🏆 Best-in-class across math, code reasoning, alignment, and instruction following:
• Outperforms the latest Qwen3.5-35B-A3B (2026-02-24) and even larger Qwen3.5-122B-A10B (2026-03-11).
🧠 Powered by Cascade RL + multi-domain on-policy distillation:
• Significantly expand Cascade RL across a much broader range of reasoning and agentic domains than Nemotron-Cascade 1, while distilling from the strongest intermediate teacher models throughout training to recover regressions and sustain gains.
🤗 Model + SFT + RL data:
👉 huggingface.co/collections/nv…
📄 Technical report:
👉 research.nvidia.com/labs/nemotron/…
English
Alessio retweetledi

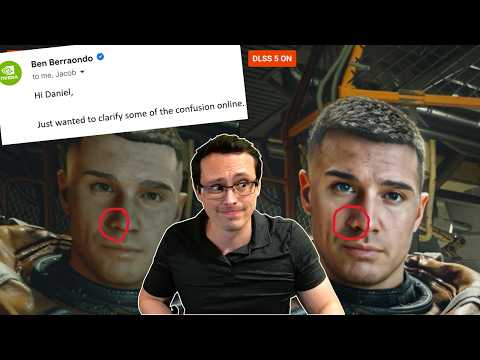
@nimlot26 @Rashimotosan @_mamoniem But they specifically stated that they use only the 2D color frame and motion vector, no other buffer, that's it. So, now that we do have more info, this looks more and more just like a post process filter. I was in your camp, but the latest info disprove that.
English

No. I've said Dan jumped to a conclusion without understanding that this could be done while using the g-buffer data(as they suggest when calling this not a post process, and using model and texture information and so on).
I've told people about how i understand that this works based on what info they released and what Jensen said in the Q&A where he stated multiple times that it's not post process.
If this turns out to be just a post process filter I will stand corrected and Nvidia can suck a dick for misleading.
If this is actually processed prior to frame compositing and takes into consideration the g-buffer information then it's a revolutionary leap.
In the end I'm just adding more info to the pool for people to have the ability to make an educated guess about how it works. It will be sorted out once Nvidia decided to release some proper documentation.
English
People keep sending me Daniel Owen's video which basically states that DLSS5 is an instagram filter because it uses just one frame and a motion vector.
While his questions were valid and he actually got the replies he needed, his lack of basic technical understanding took him to the wrong conclusion.
A lot of you have a very hard time understanding the basics of how a frame is rendered in your game and what kind of information is available before postprocessing and straight up went to the idea is that a rendered frame is like the screenshot you saved on your disk.
@ado_tan and his friends have some amazing breakdowns about how different games render stuff. I suggest you to dive on his blog and check all of them out. This way maybe you will understand a bit more about how games are rendered.
Here you have an article he wrote about how GTA5 renders a frame. I'm sure it will be eye opening for a lot of you.
Till you do your research...I'll just go and play Crimson Desert.
Adrian Courrèges@ado_tan
This is how a frame is rendered in GTA V: adriancourreges.com/blog/2015/11/0…
English
Alessio retweetledi

Alessio retweetledi

As someone who watched Iran get ruined my whole life, then moved to the USA and now sees them coming here too, this pic tells you everything.

English
@nataliacruzxo @glam_queenn No man wants to do that, but it happens anyways. I would say the stats suggest it's very common in fact
English




youtu.be/D0EM1vKt36s?is…
After the questions answered by Nvidia in this video, I have to change my opinion on DLSS 5. It is in fact just an Instagram filter and not at all what they implied. Lame and uninteresting. That's what I wanted, more technical info, so now, fuck Nvidia!

YouTube
English
Alessio retweetledi

Qwen3.5-4B searched 20+ websites, cited its sources, and found the best answer! 🔥
Try this locally with just 4GB RAM via Unsloth Studio.
The 4B model did this by executing tool calls + web search directly during its thinking trace.
English
Alessio retweetledi

Alessio retweetledi

During DLSS 5 Hands-On Video, YouTube creator Hot Hardware asked Nvidia employees this question about the computational cost of DLSS 5 when you move around in the game and it really caught my eye on how they hesitated on showing any DLSS 5 footage during motion.
Every time that he moved the character, he would turn off DLSS 5 first then move to a different in-game location and then turn it on, or if DLSS 5 was turned on the movement was very slow and controlled.
I know this is still work in progress, but it really begs the question "why wouldn't they show any this?" or "why show DLSS 5 this early?"
I tried freezing some shots when another character is in motion to check if there are any artifacts when DLSS 5 is turned on.
As suspected, I did come across some artifacts with UI elements, character popping out of the UI element and ghosting/artifacts behind the character.
Its still not the best way to judge these small details that you can clearly see if a footage is recorded in-game, but then again its not like Nvidia provided any of them during DLSS 5 marketing campaign.
Whenever this is still going to be present by the time DLSS 5 launches remains to be seen, however as of right now it doesn't look like it will handle fast-paced motion quite well and I don't know how well this "controlled AI-generated" rendering will scale to weaker GPUs in the RTX 50 series

English
Alessio retweetledi

Alessio retweetledi

English
Alessio retweetledi

Oh wow, Mamba-3 is here!
For me, the most interesting use case of Mamba and Mamba-likes are the recent transformer attention hybrid architectures (Qwen3.5, Kimi Linear, etc.)
Would be interesting to swap Gated DeltaNet with Mamba-3 (which now also has RoPE) in next gen hybrids.
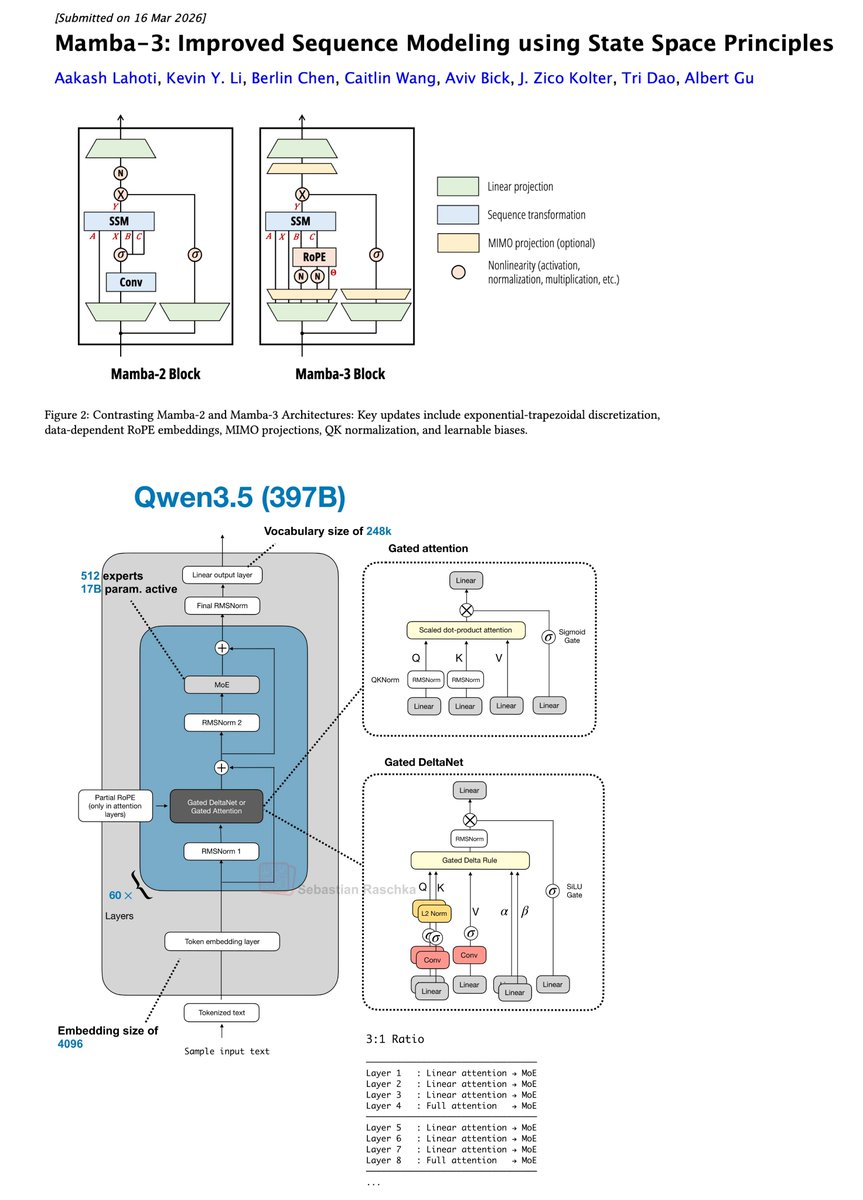
Albert Gu@_albertgu
The newest model in the Mamba series is finally here 🐍 Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models. We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes. This is the first Mamba that was student led: all credit to @aakash_lahoti @kevinyli_ @_berlinchen @caitWW9, and of course @tri_dao!
English
Alessio retweetledi

Meet Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled: a 27B parameter reasoning specialist. This model was distilled from Claude's reasoning patterns into Qwen's architecture, creating a powerful chain-of-thought thinker that's surprisingly accessible. The community's excitement is real!
English
Alessio retweetledi

Her name was Leonie, she was a 13-year-old Austrian girl.
While she was out with friends, 3 Afghan immigrants secretly put 11 ecstasy pills in her drink. Stunned and unable to defend herself, she was taken to the house of one of the three.
The ecstasy dose was way too high, the girl started overdosing but the 3 immigrants, completely indifferent to her suffering, began to undress her and took turns raping her, putting their hands around her neck, strangling her. All of it recorded by themselves on a mobile phone video.
That’s how Leonie died, naked, in atrocious suffering, while the beasts raped her. The autopsy would later confirm the cause of death was triple overdose and asphyxiation.
When they were done, they wrapped the body in a carpet and dumped it roadside, under a tree.
The girl’s body was found the next morning by some passers-by, wearing only her underwear and with clear strangulation marks on her neck.
One of the perpetrators fled to the United Kingdom, but was quickly tracked down in a hotel and extradited, the 3 Afghans were sentenced:
- Zubaidullah R. life imprisonment;
- Ali H. 19 years in prison;
- Ibraulhaq A. 20 years in prison.
During the closing arguments, the Public Prosecutor told the court she was “stunned” by what the defendants said throughout the proceedings, stating that “there is not a trace of remorse”.

English
Alessio retweetledi

Here's some of the DLSS 5 material we saw in the demos but didn't get a chance to film. Here I think you can see the strengths of DLSS 5 - reflections become much more attractive. Starfield doesn't have great lighting to begin with, so the differences can be profound.
English