
Reuben Stern
54 posts
Reuben Stern
@ReubenConducts
Research Scientist at Colfax International. Conductor, bassoonist, mathematician, wannabe powerlifter. They/them
Boston, MA Katılım Mayıs 2019
79 Takip Edilen147 Takipçiler

"ohh I beat cublas by 2% by implementing Hilbert curves"
The trick to beating cublas is to go where they aint looking;
And pray the next toolkit hasn't caught back up (it will)

English
@PatrickToulme can you provide more detail: TFLOPS, runtime in us, testing environment (eg did you use triton do_bench or manual timing), and tolerance figures, among others? it's a bit challenging to understand speedup numbers and "better numerics" claims without additional context.
English

PyPTX is now the fastest FlashAttention kernel I’ve benchmarked.
Using an improved PyPTX harness, GPT 5.6 Sol Max fully generated the kernel over a multi day loop that beats both FlashAttention-4 and cuDNN.
Excited to share more results in the coming weeks.
The future of kernel authoring is 100% agentic: models writing directly in the ISA.

English
i'll be conducting my second full opera this season! half a year away, but i'm starting to sink my teeth into this great score

English
@drisspg @gaunernst with the breaking changes from 4.6.0 i'm doubtful that there won't be major breaking changes in future releases.... doesn't inspire confidence
English
@gaunernst FWIW this is also my experience and why I have been putting off doing this. But I want nice out of the box perf :(
English
If PyTorch added cutedsl as a required
Runtime dependency for our Cuda wheels, how much would this mess you up? Would >= X.y for latest X.y at time of pt release work?
English
@SubhoGhosh02 @elliotarledge i haven't looked through it thoroughly, but the softmax approach appears to differ slightly from fa-4. worth noting that these optimization problems get significantly harder as simultaneous feature requirements increase - more headdims, varlen, GQA, etc.
English

@elliotarledge do you think like since model could reward hack, it could have emitted the ptx of fa4 from cutedsl and maybe reverse engineered it to build pyptx flash attention, but even if it not it would be interesting since we could reverse engineer everything in pyptx then
English
I was anti Fable, but now I do find it to be a good model though
Added a VSA example to the gym: github.com/meta-pytorch/a…
FlexFlash on sparse-distilled Wan2.1 14B: 2.4× faster attention, 1.4× faster e2e vs dense at 768×1280 .

English
@drisspg @gaunernst anecdotally, I think the pytorch flex side is preferable now - I recently struggled to get a particular score mod performant by hand, and the flex version was better
English
@gaunernst I dont have much of a dog in this race. But personally I do believe what we have in pytorch flex - generating the cutedsl expressions (they recently got a lot faster for loads) / compile support, backwards glue etc is a nicer interface. There is always torch_logs=output ;)
English
@SubhoGhosh02 FA3 has the option to sort batches by decreasing number of blocks processed in a metadata prepare kernel, which just hasn't yet been ported over to FA4 (though I have an open PR beginning this!). it's especially beneficial in mixed prefill-decode or with many zero-len sequences
English
@SubhoGhosh02 yeah, this is exactly the right approach! interestingly, this appears important even when using CLC scheduling. there's also a distinction to draw between intra-sequence LPT (that which is built into FA (3 and 4)) and inter-sequence LPT, which is currently only built into FA3.
English
FA4's SingleTileLPTScheduler exploits that causal attention work grows with block index, so it just visits blocks in reverse (block = num_block - 1 - block).
So why not try something similar on grouped gemm! In grouped GEMM the analog is that a tile's mainloop time is proportional to its group's K, and StaticPersistentGroupTileScheduler visits tiles in group-metadata order. So LPT = order groups by descending K.
Result is 1.74x speedup in grouped gemm, just by sorting the scheduling path.
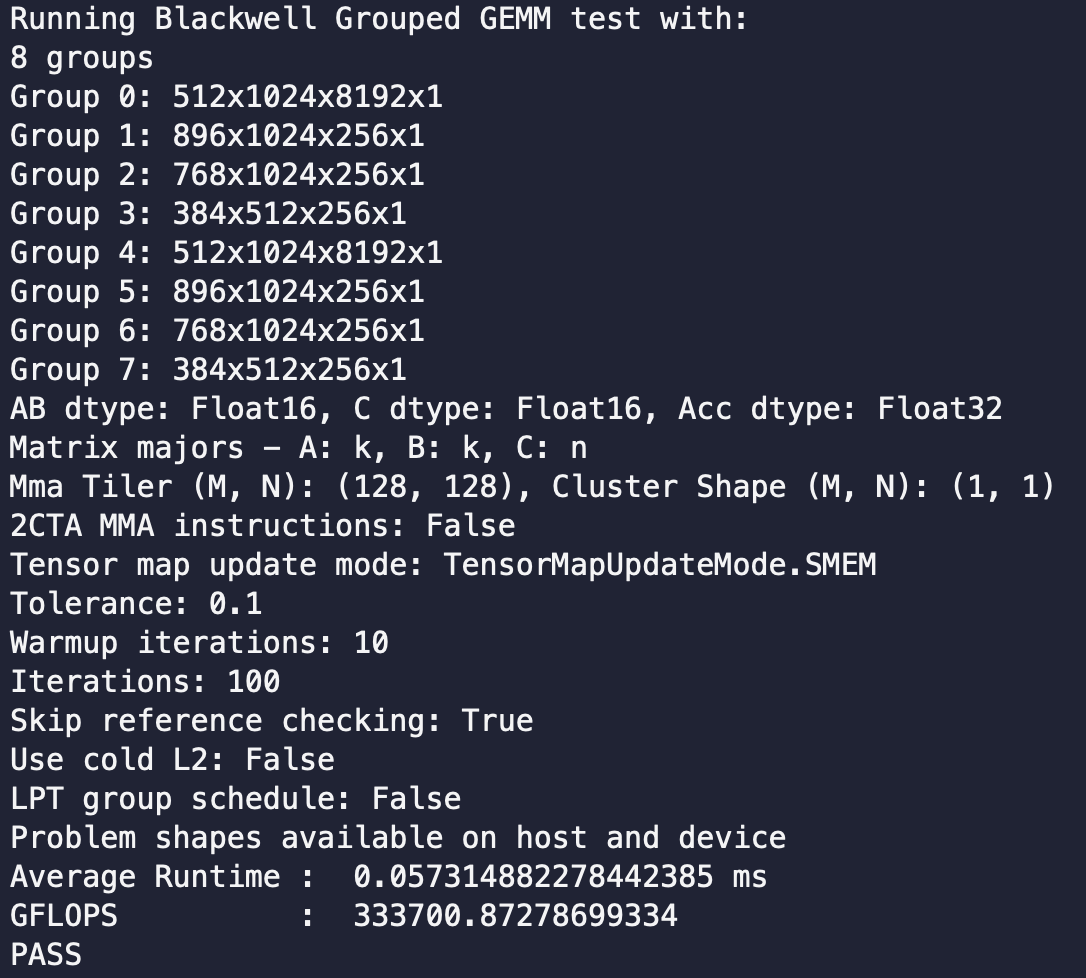
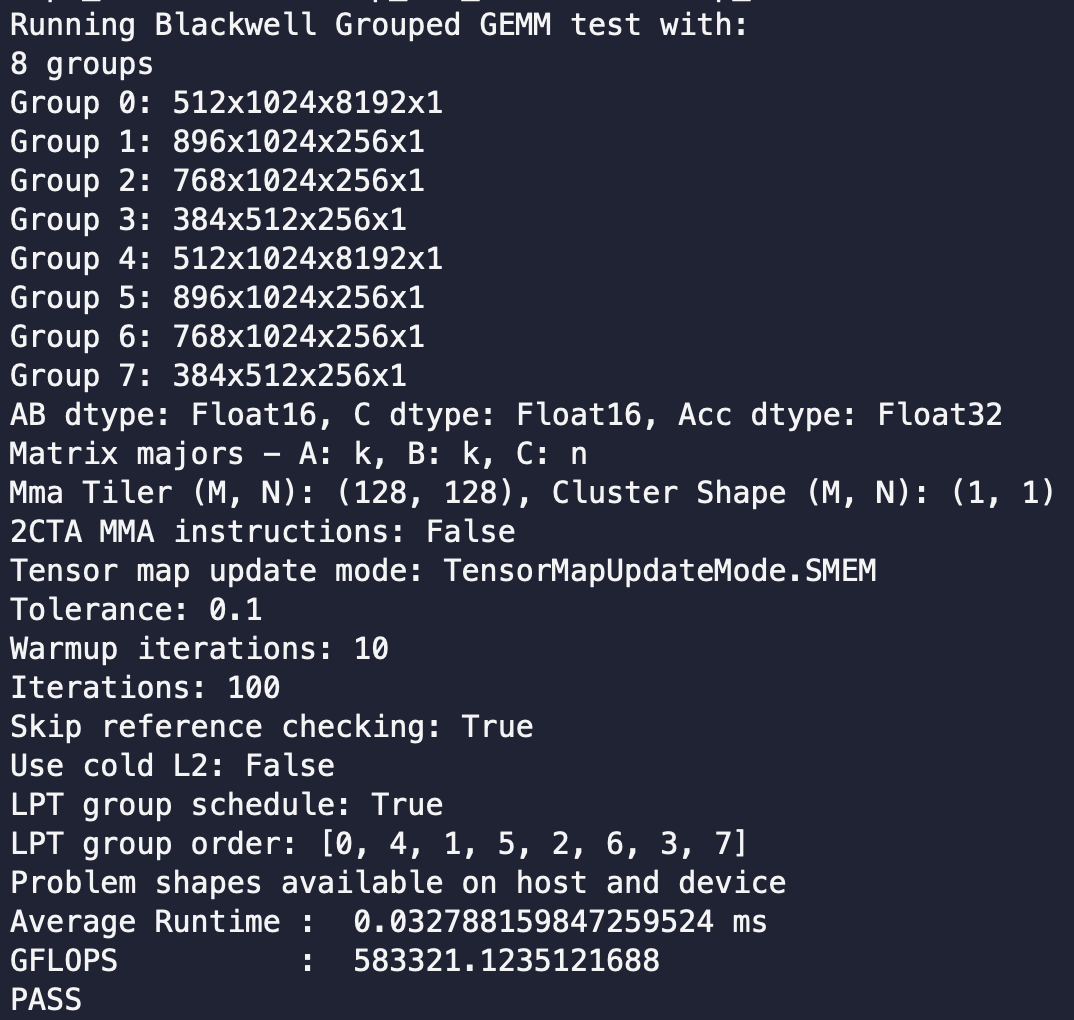
English
at least Reuben Ultra is still the same size (5'8") and all the performance (squatting 425 no sleeves no belt) 😤
SemiAnalysis@SemiAnalysis_
INTERESTING: Only 3 months after Rubin Ultra was announced at GTC 2026, the original 4-die Rubin Ultra has been cancelled due to manufacturing execution concerns. The new “Rubin Ultra” is half the size/~ half the real-world performance of the original Rubin Ultra. 1/4🧵
English

@drisspg this far too good to be AI-generated. "but only if you have the faith in god"? "..., instructed by the powerball company workers because they have spoiled our names a lot!"? true poetry.
English
Proof that agi will take a long time to disseminate through society

English
English

I am actually kind of super CODA pilled right now arxiv.org/abs/2605.19269 ... need to work out the details for sparse MoEs though
English


We have a new blog post out on NVFP4 blockscaled GEMM on NVIDIA Sm12x GPUs, like the RTX Pro 6000, DGX Spark, and 5000-series Geforce cards! We carefully walk through converting a BF16 CuTeDSL GEMM example to NVFP4.
research.colfax-intl.com/cutlass-tutori…
English
@maharshii hdim 256 on sm100 takes a fully separate kernel path than other supported hdims, while all hdims are unified on sm90. the behavior may thus be different on b200; hopefully someone can resolve your issue soon
English


Reuben Stern retweetledi

I've started at @AnthropicAI this week, working with amazing folks in interpretability & alignment! Lots to learn, but excited to keep pushing on broader questions I care about at frontier scale: building AI systems to be coherent, interpretable, introspective, and aligned
English
@SubhoGhosh02 the point about cache thrashing is an important one that took me a long time to appreciate: after a certain point, it is necessary to *avoid* more l2 cache usage. flashattention handles this nicely in the longest-processing-time-first scheduling logic
English
@ReubenConducts yup we have so many ways to improve L2 like swizzle, thread block raster, super grouping, and this, I mean we are over engineering l2 ig, hehe but yeah simple swizzle solves it most of the time
English
@SubhoGhosh02 usually more naive swizzling can get you close to the best possible l2 usage. if you don't know that your problem is a power-of-2-tile-per-side square, hilbert curves (though pretty) may not be reasonable. (also, more l2 usage is not always best (cache thrashing is bad))
English
Wherever I go I see hilbert curve improving L2 cache efficiency
ft. mpp programming guide - developer.apple.com/download/files…

English
Today marks one year since I began my new career as a researcher at @colfaxintl! I am incredibly grateful to my brilliant team -- Hassan, Jack, Jay, Paul, Ryo, and Frank -- as well as the collaborators we've been fortunate enough to work with.
English