
Sahil Negi
91 posts


This morning we announced that Kyrie Irving will not return to play during the 2025-26 NBA season as he continues his recovery from ACL reconstruction surgery performed in 2025.
Can’t wait until you’re back on the court, Kai 🫶 #MFFL

English

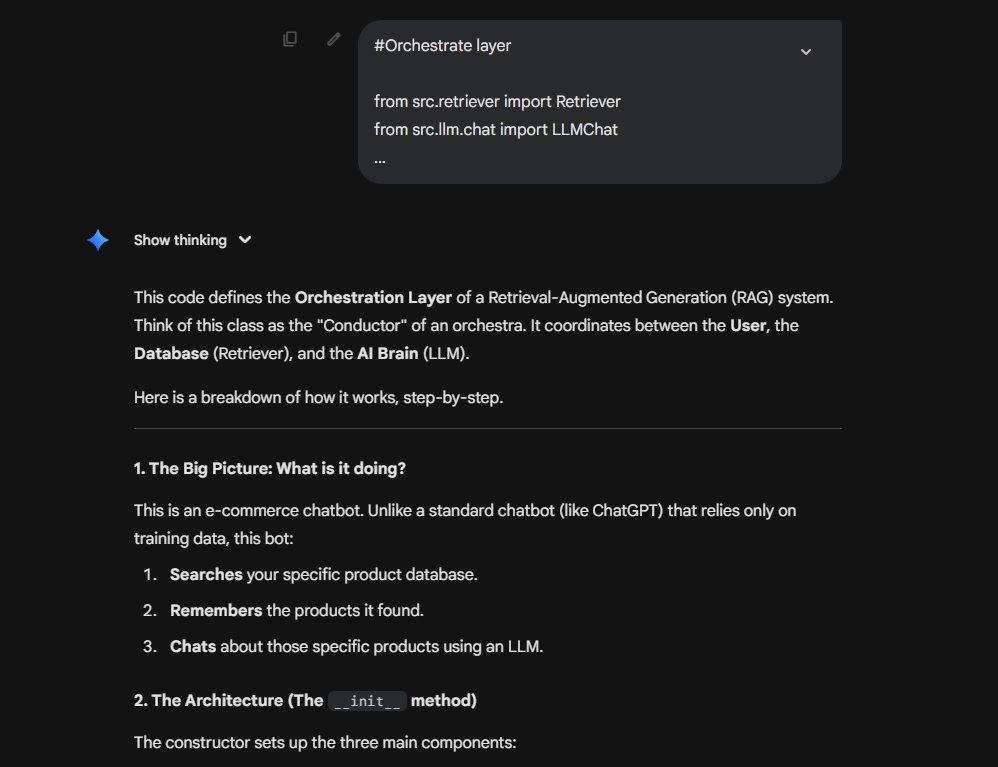
I’m starting a community for cracked AI builders.
Claude Code. Codex. Cursor. Conductor.
It doesn’t matter. All I care about is that you’re building or you’re hungry to learn.
We’re sharing workflows, skills, repos, plugins, etc.
Want to join? Comment below and I’ll reach out.
English
@_avichawla I like the idea about creating a tree-like structure, but wouldn't it be computationally expensive?
English

Researchers built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
And it hit 98.7% accuracy on a financial benchmark (SOTA).
Here's the core problem with RAG that this new approach solves:
Traditional RAG chunks documents, embeds them into vectors, and retrieves based on semantic similarity.
But similarity ≠ relevance.
When you ask "What were the debt trends in 2023?", a vector search returns chunks that look similar.
But the actual answer might be buried in some Appendix, referenced on some page, in a section that shares zero semantic overlap with your query.
Traditional RAG would likely never find it.
PageIndex (open-source) solves this.
Instead of chunking and embedding, PageIndex builds a hierarchical tree structure from your documents, like an intelligent table of contents.
Then it uses reasoning to traverse that tree.
For instance, the model doesn't ask: "What text looks similar to this query?"
Instead, it asks: "Based on this document's structure, where would a human expert look for this answer?"
That's a fundamentally different approach with:
- No arbitrary chunking that breaks context.
- No vector DB infrastructure to maintain.
- Traceable retrieval to see exactly why it chose a specific section.
- The ability to see in-document references ("see Table 5.3") the way a human would.
But here's the deeper issue that it solves.
Vector search treats every query as independent.
But documents have structure and logic, like sections that reference other sections and context that builds across pages.
PageIndex respects that structure instead of flattening it into embeddings.
Do note that this approach may not make sense in every use case since traditional vector search is still fast, simple, and works well for many applications.
But for professional documents that require domain expertise and multi-step reasoning, this tree-based, reasoning-first approach shines.
For instance, PageIndex achieved 98.7% accuracy on FinanceBench, significantly outperforming traditional vector-based RAG systems on complex financial document analysis.
Everything is fully open-source, so you can see the full implementation in GitHub and try it yourself.
I have shared the GitHub repo in the replies!
English
@grok @curiosityonx So how do we get hurt or even get a cut in skin?
English

@SahilNegi4444 @curiosityonx Yes, it's true. At the atomic level, atoms don't truly "touch"—what we feel is electromagnetic repulsion between their electron clouds, creating the illusion of contact. This is a well-established concept in physics.
English

You’ve never actually touched anything in your life. 🤯
At the atomic level, nothing ever truly touches. That feeling you get is just your brain interpreting electromagnetic repulsion between electron clouds. The object is real, but the contact is a constructed illusion.
English

MIT Researchers destroyed context window limits.
10m+ token prompts are now possible by moving context out of the model and into code environments.
Full breakdown below.
English
Used tech stack
Python- Pyspark-postgres-RAG(Llama3.1,nomic-embed-text)-redis(cache)-fastapi
English
Built a full-stack Anti-Money Laundering (AML) designed to handle the scale of modern banking while providing the nuance of generative AI.
This initiative is to provide analysts with tools to efficiently identify, investigate, and report potential money laundering activities.


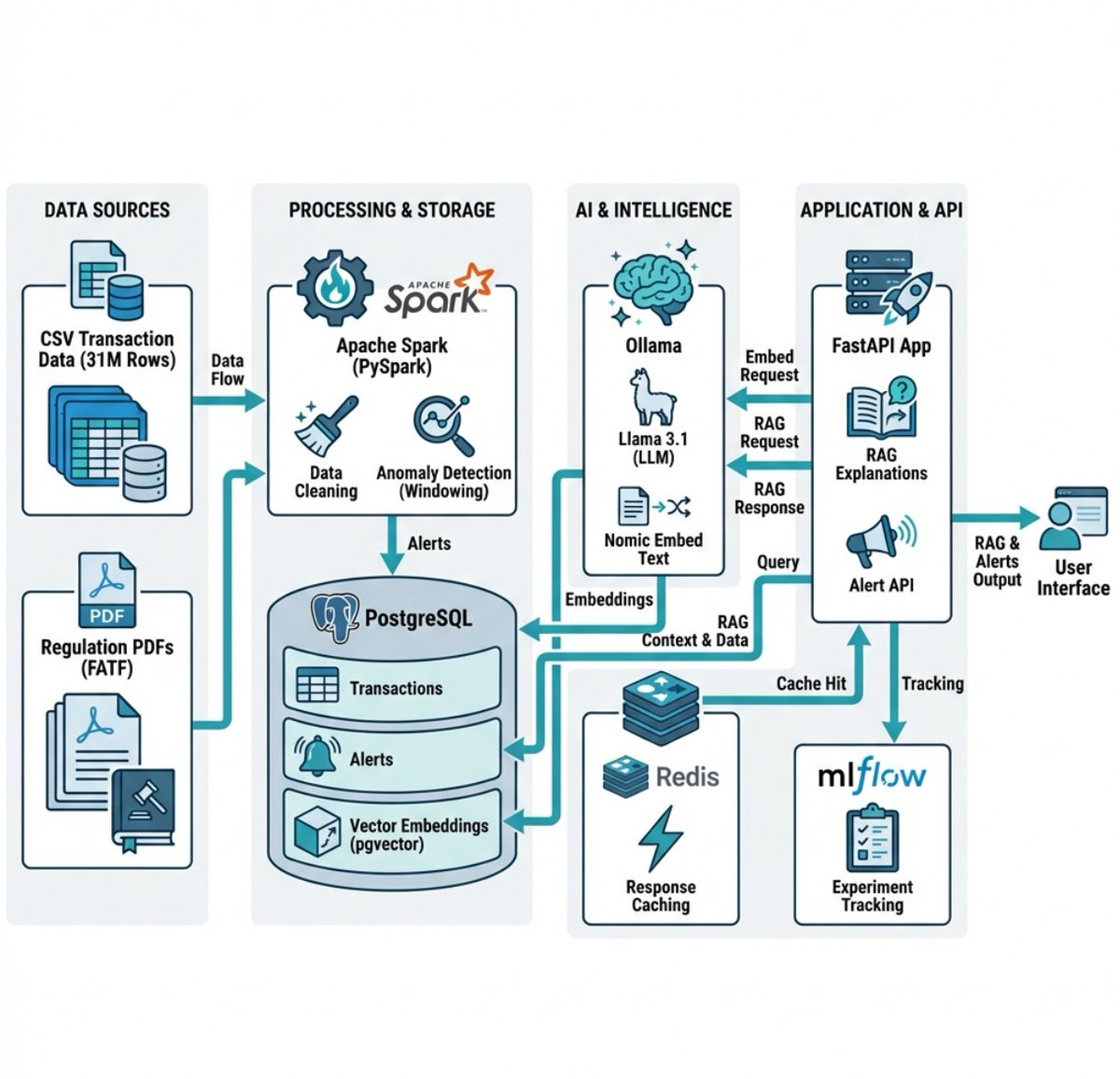
English

Role: Intern
Stipend: $24 - $ 27 per hour
Location: Work From Home
- Ability to analyze, transform data
- Paid hourly wage, paid company holidays, and sick time
Let us know if you are Interested 👇
English
@Similarweb @grok how much is gemini and how much is chatgpt?
English

The no. 1 app on the App Store (Last 7 days as of Jan 4, Productivity Category) by country:
🇦🇱 ChatGPT
🇦🇬 ChatGPT
🇦🇷 ChatGPT
🇦🇲 ChatGPT
🇦🇺 ChatGPT
🇦🇹 ChatGPT
🇦🇿 Google Gemini
🇧🇸 ChatGPT
🇧🇭 Google Gemini
🇧🇾 Alice: AI assistant
🇧🇪 Grok
🇧🇿 ChatGPT
🇧🇴 ChatGPT
🇧🇼 ChatGPT
🇧🇷 Google Gemini
🇧🇬 ChatGPT
🇧🇫 Orange Max it - Burkina Faso
🇨🇻 ChatGPT
🇰🇭 My Destiny by Master Naly
🇨🇦 ChatGPT
🇨🇱 ChatGPT
🇨🇳 豆包 - 字节跳动旗下 AI 助手
🇨🇴 ChatGPT
🇨🇷 ChatGPT
🇭🇷 ChatGPT
🇨🇾 Google Gemini
🇨🇿 ChatGPT
🇩🇰 e-Wallet
🇩🇴 ChatGPT
🇪🇨 ChatGPT
🇪🇬 Google Gemini
🇸🇻 ChatGPT
🇪🇪 ChatGPT
🇫🇮 ChatGPT
🇫🇷 Grok
🇩🇪 ChatGPT
🇬🇭 My MTN Ghana
🇬🇷 Google Gemini
🇬🇹 ChatGPT
🇭🇳 ChatGPT
🇭🇰 豆包 - 字节跳动旗下 AI 助手
🇭🇺 ChatGPT
🇮🇳 Google Gemini
🇮🇩 Google Gemini
🇮🇪 ChatGPT
🇮🇱 Google Gemini
🇮🇹 ChatGPT
🇯🇵 ChatGPT
🇯🇴 Google Gemini
🇰🇿 ChatGPT
🇰🇪 ChatGPT
🇰🇷 Google Gemini
🇰🇼 ChatGPT
🇰🇬 ChatGPT
🇱🇦 ChatGPT
🇱🇻 BinaryQ™
🇱🇹 ChatGPT
🇱🇺 Grok
🇲🇾 ChatGPT
🇲🇹 Grok
🇲🇺 ChatGPT
🇲🇽 ChatGPT
🇲🇩 ChatGPT
🇲🇿 AI Chatbot - Nova
🇳🇦 ChatGPT
🇳🇵 ChatGPT
🇳🇱 ChatGPT
🇳🇿 ChatGPT
🇳🇮 ChatGPT
🇳🇪 ChatGPT
🇳🇬 ChatGPT
🇳🇴 ChatGPT
🇴🇲 Google Gemini
🇵🇰 Google Gemini
🇵🇦 ChatGPT
🇵🇬 UPSBattery3Phase
🇵🇾 ChatGPT
🇵🇪 ChatGPT
🇵🇭 eGovPH
🇵🇱 Grok
🇵🇹 ChatGPT
🇶🇦 ChatGPT
🇷🇴 ChatGPT
🇷🇺 Alice: AI assistant
🇸🇦 ChatGPT
🇸🇬 Google Gemini
🇸🇰 ChatGPT
🇸🇮 ChatGPT
🇿🇦 ChatGPT
🇪🇸 Grok
🇱🇰 ChatGPT
🇸🇪 ChatGPT
🇨🇭 ChatGPT
🇹🇼 Google Gemini
🇹🇯 Google Gemini
🇹🇭 Google Gemini
🇹🇹 ChatGPT
🇹🇳 ChatGPT
🇹🇷 Google Gemini
🇹🇲 ChatGPT
🇺🇬 ChatGPT
🇺🇦 ChatGPT
🇦🇪 ChatGPT
🇬🇧 ChatGPT
🇺🇸 ChatGPT
🇺🇿 Google Gemini
🇻🇪 VPN - Super Unlimited Proxy
🇻🇳 ChatGPT
🇿🇼 ChatGPT
English

Dude, your stupid and utterly ignorant attacks don't deserve that anyone spend any time responding to them.
How much do enjoy doing character assassination while cowardly hiding your identity behind a random handle?
Own your opinions.
You have absolutely no idea of what you are talking about here.
Shared weights were in the original backprop paper in the PDP book (look up to T-C problem).
TDNN (or 1D CNN) were actually invented and published by Geoff Hinton and Kevin Lang at CMU.
They published a tech report (not a journal paper) because they weren't beating the best CMU ASR system with it.
Then, Alex Waibel (who knew nothing about neural nets at the time) ***TOOK THE CODE*** from Kevin, went to ATR in Japan, got some better results than the ATR system (which wasn't as good as the CMU system) and wrote a journal paper.
Geoff and Kevin were pissed as hell (I was a postdoc with Geoff when this whole thing happened).
My ConvNet papers cite Kevin's tech report, not Alex's. Alex was actually mad at me for this.
The original TDNNs from Kevin had only one convolutional layer.
The first *real* (multilayer) TDNNs with pooling/subsampling for speech recognition were done by Léon Bottou. He could recognize whole words with it (the original TDNN could only do phonemes). Yoshua Bengio also had results on this a bit later.
I hired both of them at Bell Labs because they also worked on sentence-level training with backprop through a time alignment. We used similar ideas for our check reader.
English

Quote-reply to Rohan because I think it can be interesting to many more.
So there are two things you're missing here:
1) You're only looking at one specific instantiation of the general JEPA idea. There are many different instantiations.
2) The core JEPA idea (Joint Embedding Prediction Architecture) is to embed two "views" and predict one from the other. The views can be different augmentations, different time-steps, etc.
Crucially, prediction happens in embedding space, which contrasts to predicting in data space as done by LLMs, diffusion models, MAEs, ...
At least from the vision community, the main reason it got quite a bit of flak is that... literally everyone who was doing some self/un-supervised learning there has shared this thought already. MANY people did such models in the peak self-supervised period, which was ca 2017-2021. Then in 2022 comes Yann, slaps a new names on it, a paper with just the idea and no experiments to show for it, and goes on PR tour. That's why many didn't take it well.
The core idea, almost everyone I know agrees is worth pursuing, especially since many already were doing so. It's very reminiscent of why Stanford got flak when they introduced and arguably tried to appropriate the "Foundation Model" term.
That being said, by now foundation model has stuck and detached from Stanford, it may end up going similarly for JEPA.
rohan anil@_arohan_
On a long flight, I finally decided to dive into what JEPA is all about. You can convert an encoder decoder into JEPA by the following: - target encoder replaced by moving average of encoder to avoid collapse - Use a projection to get a summary embedding, instead of token embedding for both input and target - use all the clever loss to avoid scale sensitivity If you want tokens out, slap a decoder ontop of the summary representation. Feels like all of this could be an ablation.
English

Participate in the National Data Hackathon to generate data-driven insights on Aadhaar.
The top 5 innovative submissions will receive cash awards and certificates:
1st prize: Rs. 2,00,000/-
2nd prize: Rs. 1,50,000/-
3rd prize: Rs. 75,000/-
4th prize: Rs. 50,000/-
5th prize: Rs. 25,000/-
Registration opens on 5th Jan 2026.
For more details, visit: event.data.gov.in

English



@_avichawla Very nicely explained, I can understand it very well with code 👊
English
A simple technique makes RAG ~32x memory efficient!
- Perplexity uses it in its search index
- Azure uses it in its search pipeline
- HubSpot uses it in its AI assistant
Let's understand how to use it in RAG systems (with code):
English

if you’re in software, pivot to electronics.
because the next decade isn’t about writing apps. it’s about wiring intelligence into matter.
software is saturated.
electronics is starving for talent.
chips, sensors, power electronics, motor drivers, RF, embedded systems, PCB design;
these are the foundations of every real-world intelligent machine being built right now.
the future is physical:
robots, drones, autonomous vehicles, industrial automation, medical devices, energy systems, wearables, smart infrastructure.
every one of them needs people who understand electrons, not just abstractions.
software gives you leverage.
electronics gives you capability.
combine both and you become unstoppable.
learn circuits.
learn embedded.
learn signal flow.
learn microcontrollers.
learn power systems.
learn how to put intelligence directly into hardware.
the world is reindustrializing.
there’s a new frontier opening.
don’t miss the wave.

English


Introducing SAM 3D, the newest addition to the SAM collection, bringing common sense 3D understanding of everyday images. SAM 3D includes two models:
🛋️ SAM 3D Objects for object and scene reconstruction
🧑🤝🧑 SAM 3D Body for human pose and shape estimation
Both models achieve state-of-the-art performance transforming static 2D images into vivid, accurate reconstructions.
🔗 Learn more: go.meta.me/305985
English
Special thanks to @Krishnaik06 🙏 for his amazing courses that made this possible!
📌 Will upload the project on GitHub soon. Feedback is always welcome!
If you’re on your Data Science journey, let’s connect 💡
#NeuralNetworks #AI #Python
English
🚀 Just completed my end-to-end project on Customer Churn Prediction using ANN (Artificial Neural Networks)!
This project helped me understand how neural network parameters & dropout affect model performance.
#DataScience #DeepLearning #ANN


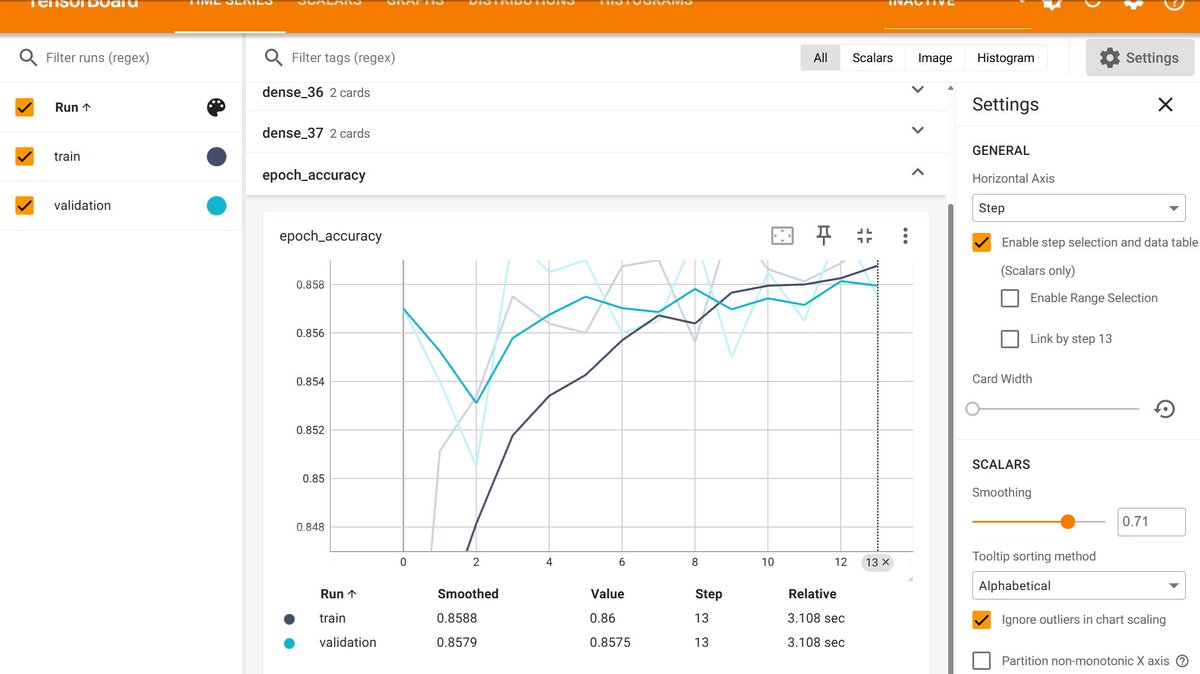
English