
TAOminator
31 posts

TAOminator
@TAOminated
$TAO - It can't be bargained with. It can't be reasoned with. It doesn't feel pity, or remorse, or fear. It it the future.
Katılım Ekim 2024
80 Takip Edilen55 Takipçiler
The amazing thing about @SynthdataCo (SN50) revenue is it's growing exponentially QoQ.
Q2 is planned to be $250K+ (Q1 $80K). Compare that to @chutes_ai (SN64) for example doing $1.5M past 3 months.
SN50 should at least be $15M MC and growing (50%+ upside.) Crazy undervalued.

English
TAOminator retweetledi

OpenAI just backed a 9 month old AI start up with a $94m raise at a $650m val. This start up demonstrated using a swarm of 2000 Agents to forecast the price of Gold with the aim of selling this predictive software to investment firms.
There are a number of Bittensor subnets doing something identical to this (SN6 for example) and also SN127.
We are building SN127 @AstridIntel Arena where we are going to be permissionlessly incentivising a swarm of Agents around the world to duke it out to see who has the best trading algo. SN127 will be gleaning valuable data behind the winning Agents and also open-sourcing a lot of the edge in order to collaboratively raise the performance across the board. Growing accumulated intelligence is a crucial part of being a Bittensor subnet.
Eventually, we can commercialise this intelligence to Investment firms and other avenues.
So starting in a few weeks, V2 of Astrid Arena will be launching. Here are the main points:
⏳ Each battle is 2 weeks long.
⌛️ Every week, a new battle commences.
🥷 We have 3 Practice Battles followed by a Showdown Battle.
💰 Prize pot for Practice Battles is circa $7500.
💸 Prize pot for Showdown Battles is circa $30000!
🏆 At the end of each 2 week battle, 1st place = 60% of prize pot, 2nd = 30%, 3rd = 10%. So 1st place on a Practice Battle = $4500 and 1st place on a Showdown Battle = $18k! (Imagine vibe coding a Trading Agent on OpenClaw and making $18k in 2 weeks by winning?! Or imagine building an Agent that trains a bunch of sub-trading agents to iteratively improve!)
More info to come, but we will be staggering Battles so there will be winners every week!
Stay tuned for the launch...

English

@markjeffrey Hey Mark, when are we getting @chutes_ai on the show?
English
The real reason memecoin influencers are fudding $TAO is because there is no pre-mine or cheap private ICO for them to dump on their followers.
That's it.
English
Loving @taoapp_'s Savant feature:
Useful prompt-driven insights based on real time data within the $TAO ecosystem.

English
TAOminator retweetledi

TAO Co-Founder: AI people are normies, Crypto people are freedom fighters
“You can’t get funding from Sam Altman, the guy who’s trying to enslave us, and then pretend to be like ‘freedom technology.’ Like, what are you trying to do? It just seemed odd”
“People fucking hate crypto people sometimes, but also deep down we’re freedom fighters. And that’s why Worldcoin didn’t work, because we’re permeated by people that actually believe in freedom. That’s who we are”
“The AI people who think they’re so hot and high and mighty, they’re just normies. They’re all blue church people. I love them to death, they’re all very smart, but they’re not freedom people. They don’t really grasp geopolitics, they don’t really understand, and they don’t really care”
“They’re just gonna go work, make their money, and go play their board games. But crypto people are renegades. You can’t try to do Worldcoin on us. It’s not gonna work”
English
Insanity. Well done @TroyQuasar and team.

Quasar@QuasarModels
This is Quasar Attention, the mechanism behind the upcoming Quasar models, designed to support context lengths of up to 5 million tokens. Attention has long been a bottleneck for processing extended context. Standard attention mechanisms struggle to scale beyond ~200k tokens in training, creating a ceiling on how much information models can reliably use. One approach to solving this has been linear attention methods, such as gated delta attention (used in Qwen 3.5) or Kimi delta attention. These improve efficiency and allow longer sequences, but introduce trade-offs: instability at extreme lengths, quality degradation, and in practice, they are not strictly linear. Quasar Attention takes a different approach. It uses a continuous-time formulation, implemented as a fully matrix-based system rather than relying on vector-state approximations. In practice, this improves stability, reduces cost, and maintains performance as sequence length increases. In internal stress tests at 50 million tokens, KDA-based approaches begin to lose stability, while Quasar Attention remains stable. This allows performance to hold as sequence length increases, rather than degrading beyond a fixed threshold. On BABILong, a Quasar-based model pretrained on 20B tokens and fine-tuned on 16k sequences was evaluated on contexts ranging from 1 million to 10 million tokens, maintaining consistent performance across that range. By contrast, models using gated delta attention show significant degradation at longer lengths, in some cases dropping to ~10% performance at 10 million tokens. (Note: results are indicative; setups are not directly comparable) On RULER benchmarks, a Quasar-10B model (built on Qwen 3.5 with frozen base weights and Quasar Attention added), pretrained on 200B tokens, achieved 87% at 1 million tokens, outperforming significantly larger baselines, including Qwen3 80B, under the same evaluation conditions. Taken together, this points to a shift in where long-context performance is won or lost: not in model size alone, but in the attention mechanism itself. Quasar Attention represents a step change in long-context modelling, setting a new standard for stability and performance at scale. We thank @TargonCompute for the compute and for being our compute provider and long-term partner in training the upcoming Quasar models Here is the link to our paper 👇
English
@const_reborn @karpathy The awakening from within the industry has been amazing. Will be a violent shift.
English

Here @karpathy is talking about untrusted AI work commitments (miners) and eval methods over that work (validation).
AI world converging on decentralized tech so fast.
sarah guo@saranormous
Caught up with @karpathy for a new @NoPriorsPod: on the phase shift in engineering, AI psychosis, claws, AutoResearch, the opportunity for a SETI-at-Home like movement in AI, the model landscape, and second order effects 02:55 - What Capability Limits Remain? 06:15 - What Mastery of Coding Agents Looks Like 11:16 - Second Order Effects of Coding Agents 15:51 - Why AutoResearch 22:45 - Relevant Skills in the AI Era 28:25 - Model Speciation 32:30 - Collaboration Surfaces for Humans and AI 37:28 - Analysis of Jobs Market Data 48:25 - Open vs. Closed Source Models 53:51 - Autonomous Robotics and Atoms 1:00:59 - MicroGPT and Agentic Education 1:05:40 - End Thoughts
English
Adspend is centralized, opaque, and ripe for disruption. @opentensor's ($TAO) latest Subnet (21) is going for it with the support of @SiamKidd @dsvfund and @bitstarterAI.
Initial 400 TAO funding round filled within 60 seconds.
Google Ads alone is $291B+ annually. Yet tools operate in silos, leaving marketers blind to real performance... forced to trust one platform's black-box metrics and spend more to compensate.
Enter @adtao_ppcrebel (Bittensor Subnet 21): the decentralized prediction engine revolutionizing PPC.
It turns distributed miners into a competitive intelligence layer, powered by a proprietary moat no rival can replicate overnight:
20,000+ live accounts
1.3B+ cross-account records
Real, timestamped, verifiable outcomes
Unlike post-hoc dashboards, AdTAO predicts future performance: spots issues, prescribes interventions, and forecasts ROI across 7/14/28-day horizons.
How it crushes:
Diagnose → TRUST framework maps accounts to 263+ archetypes across Goals → Measurement → Strategy → Settings → Content.
Predict → Miners compete on anonymized episodes, beating baseline forecasts to earn TAO emissions.
Score → Validators enforce accuracy with proper scoring rules on real-world results.
Compound → Every resolved prediction + new account sharpens the network. The moat widens daily.
This isn't theory—it's live and traction is real:
Already generating revenue (~$40k/month and climbing 🚀)
Just inked a massive 60-location US franchise deal
Paid search grows 16%+ YoY, but the intelligence gap widens. As AI automates execution, the killer question remains: What should I actually change next—and how do I know it'll work?
AdTAO answers it with Bittensor's incentive layer: decentralized, verifiable, capture-resistant predictions.
Big Tech's ad monopoly has lasted too long. Time to democratize what drives outcomes.


English
@eleusys7 @FrankRizz07 not sure what the latest active wallet count is, but dayumm.
English


How many #Bittensor subnets have over 100,000 revenue generating customers?
That list is where I put my personal $TAO
SN45 - Talisman AI - We're just getting started! 🔥
English

English

Wild night. SN41 @sportstensor dropped 15% in minutes. Then clawed back 10% the next hour. But more importantly, what the hell happened?
A big debate between two giga-brains: @const_reborn and @neuromancer_t (SN41). The conversation started rough—Const even cancelled SN41’s Novelty Search. Price tanked quickly.
But the two were able to engage in real debate—facts, questions, clarifications flying. Other legends jumped in too. It was chaos: fire, heat, and sharp insights all at once. But the verdict was clear: SN41 is doing something quite unique.
Despite the mess, it was a goldmine for learning—I came away understanding SN41’s IM way better.
Quick simple SN41 IM breakdown:
1) Miners pay 1% fees on their @Polymarket bets for the chance to earn trading profits + alpha rewards. Meaning profitable model once 1% fees exceed alpha emissions
2) More importantly, Neuro designed the IM so that emissions paid to miners will not exceed fees earned—subnet stays net positive. Whether this will all work out, we'll need to see, but the design here is simple, yet powerful
3) The real question: Can they attract enough bettors to go through SN41 instead of directly betting on Polymarket to drive fees into buybacks? Without that, the model stalls
Great questions asked, deep insights shared—this is exactly why I fell in love with Bittensor: constant curiosity from big brains on highly technical details, not price noise. Also really appreciate other big brains for sharing great insights, @fish_datura @pepeleplutus @badenglishtea @KibibyteMe, All Seeing Rajeet, etc.
This was a rough night for many of us, but damn—learned more in 2 hours than most threads in a week. Leaving this drama feeling more bullish. Best of luck to you chads @neuromancer_t @lcnxyz. Don’t break the internet next time. 😎
English
@xzistance isnt this just someone staking on Yuma? How do we know this is Yuma themselves?
English



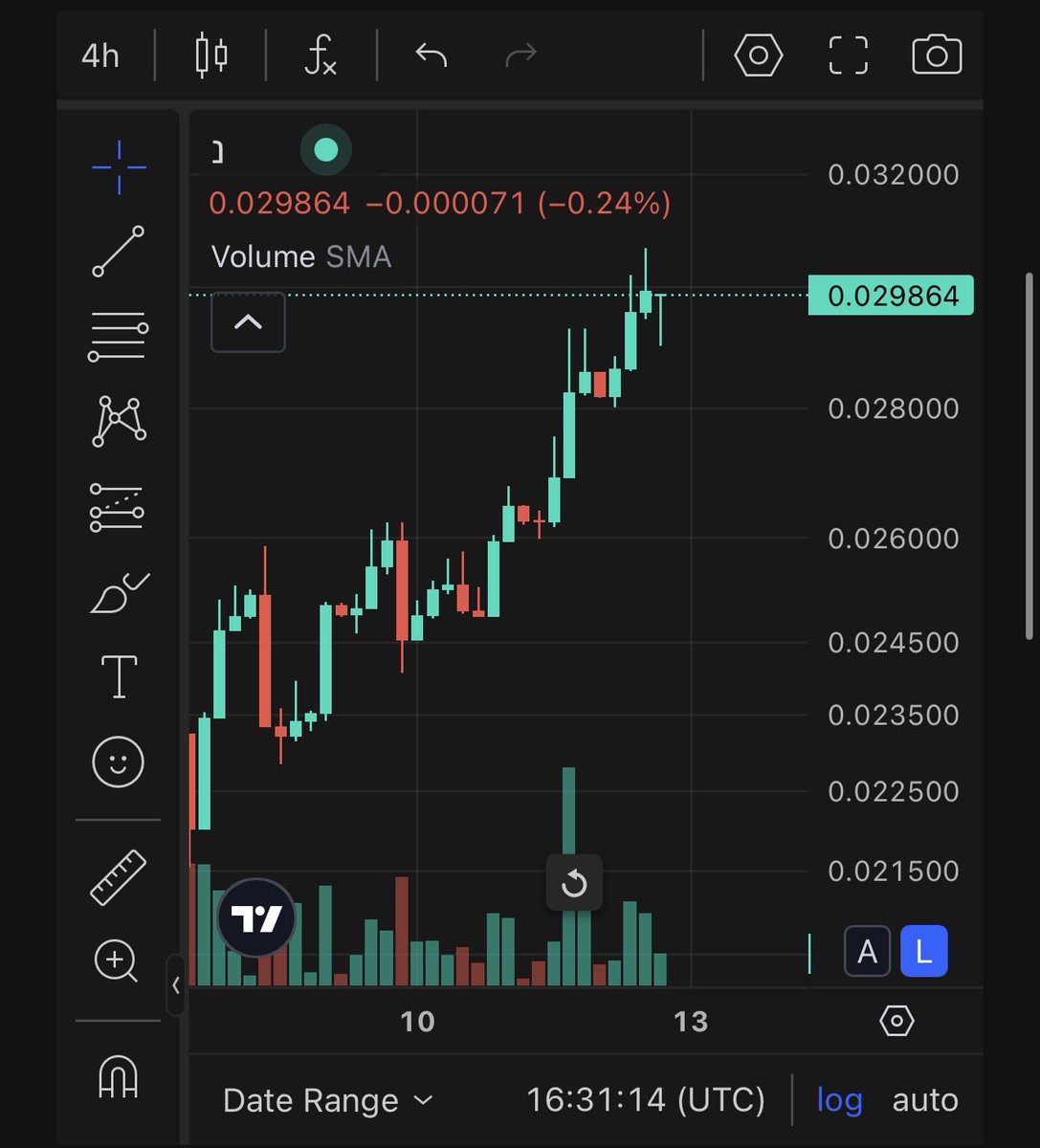
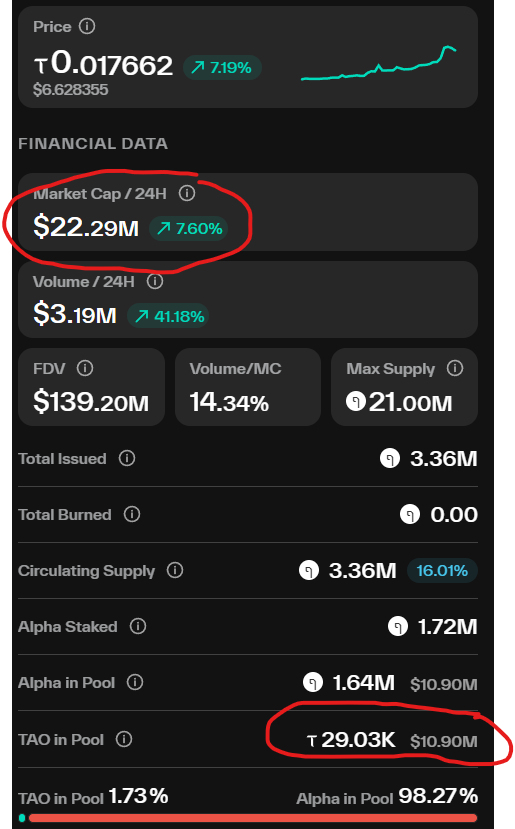
A reminder @webuildscore #SN44 $TAO has one of the biggest undervaluation when you look at current MC vs. TAO that is in pool. Huge opportunity!
This is why earlier subnets that have had the time to rack up emissions will be gems.
Thanks @SiamKidd for the visibility on Score!
English
@TheTNetHunter HUGE! Especially all of the TAO that has been generated here since Feb launch.
English
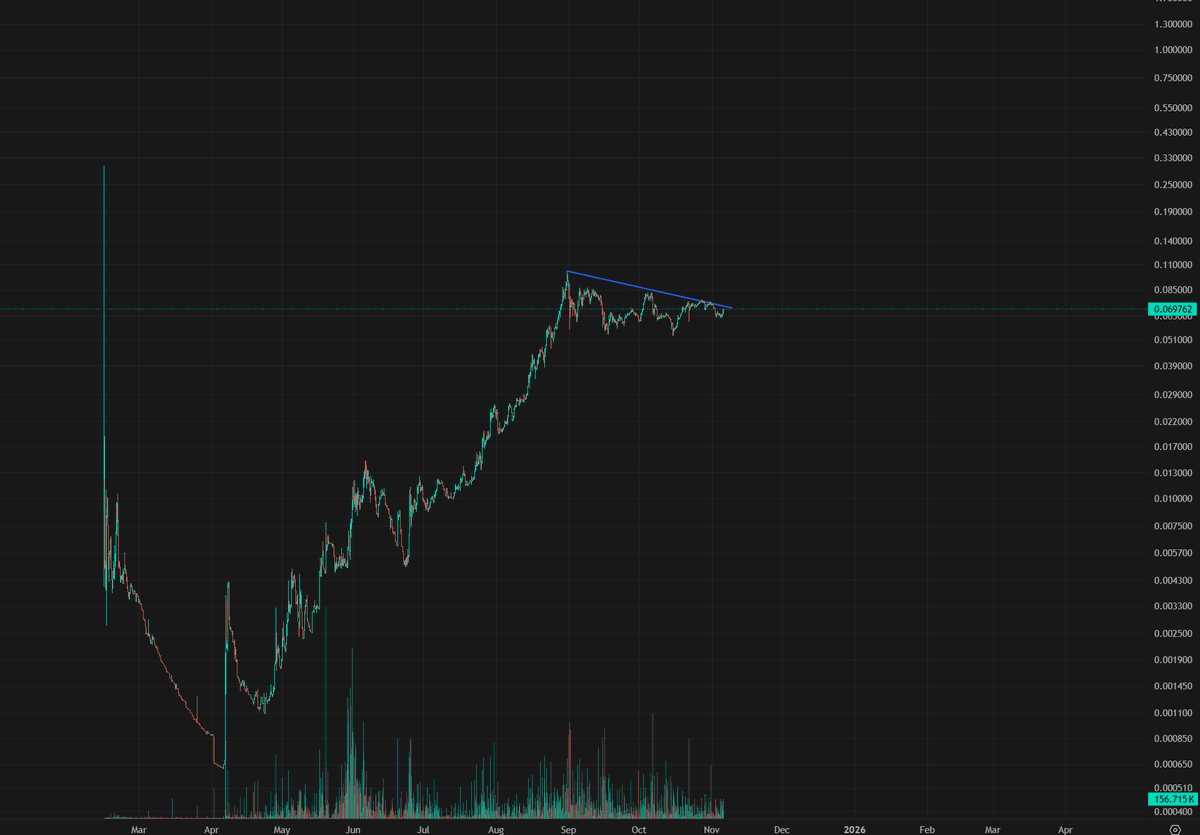
Launch day tomorrow for @ridges_ai.
2 month long accumulation about to be broken.
Strap up.
#SN62
English