Sabitlenmiş Tweet

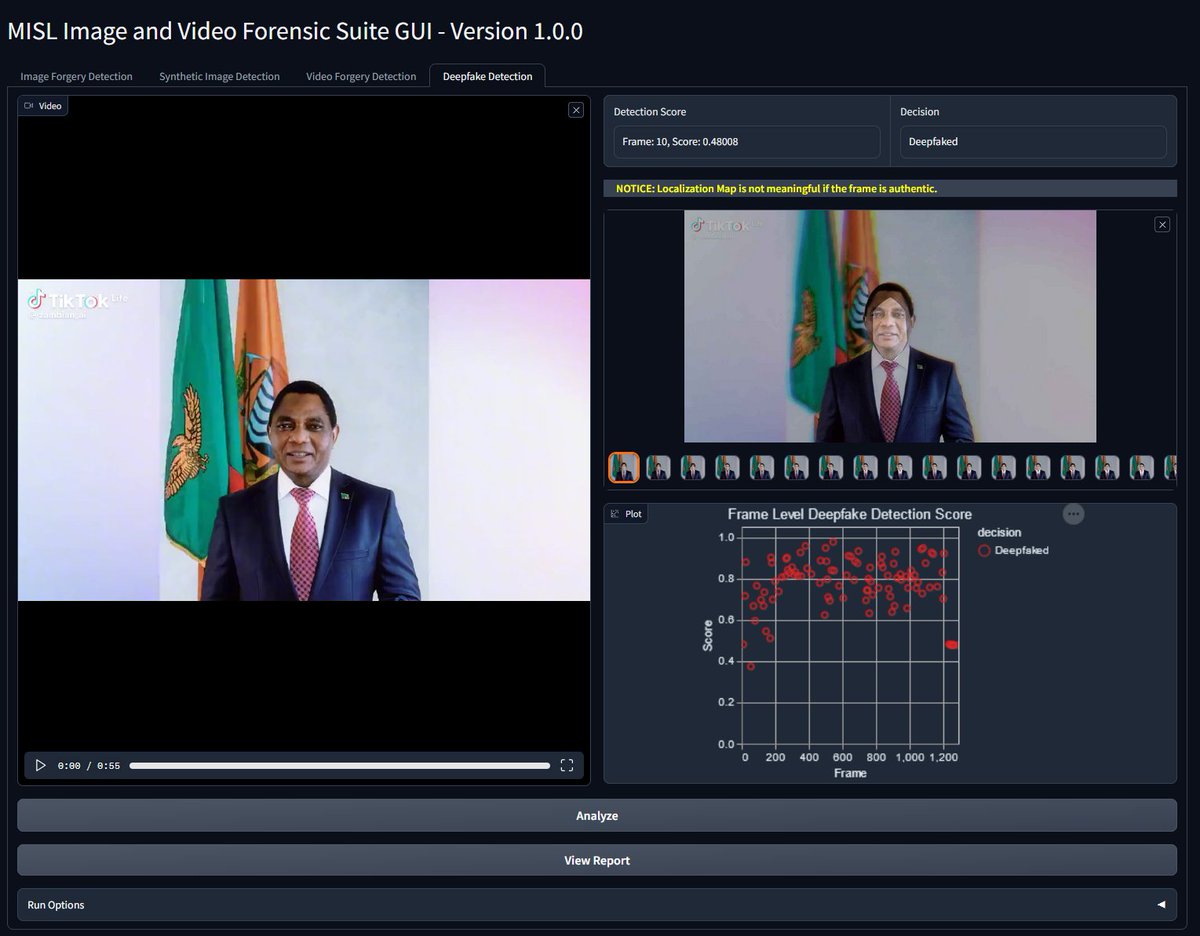
Our MISL lab at @DrexelUniv tackled a popular deepfaked video on X/Twitter of Zambia's president reportedly saying he was withdrawing from 2026 election. Our discovery is verified and posted on AFP Fact Check.
#deepfake #misinformation #disinformation #election #afp #FactCheck

English