
@sudoingX How do you use multiple devices with Hermes, can they all connect to one Hermes instance?
English
TechnoItch 🧙🏽♂️
6.5K posts


a week with the dgx spark, here is what is on it and what i have measured so far. nobody is really talking about this machine and it is quietly becoming the workhorse of my whole stack. hardware: nvidia gb10 sm_121, 124 gb unified lpddr5x at 273 gb/s, cuda 13.0 models on disk (305 gb total, 9 ggufs): > qwen 3.6 27b q4_k_m / q5_k_m / q8_0 / ud-q4_k_xl > nemotron 3 omni 30b-a3b q4_k_m / q8_0 / ud-q6_k / ud-q6_k_xl > deepseek v4-flash 158b q4_k_m (112 gb, flagship 128gb-tier test) terminal + shell environment: > zsh + oh-my-zsh + powerlevel10k theme > modern cli stack: bat, eza, ripgrep, fd, git-delta, tldr, neovim, fzf, autojump > 6 tmux sessions actively running for parallel agent work ml + agent stack: > llama.cpp built sm_121 against cuda 13 > uv + venv ml stack with pytorch 2.11.0+cu130 (aarch64) + transformers + diffusers + accelerate > hermes agent v0.11 with codex auth bridge > opencode for free-model overnight research > telegram gateway routing to nemotron q8 right now speeds verified so far: - nemotron 30b-a3b q8: 56 tok/s gen, 1,300 tok/s prefill, 96% gpu, 33gb in unified - qwen 27b dense q4: 40 tok/s consistent 90+ gb of unified memory still free. deepseek v4-flash 158b loading next as the real flagship test, multimodal omni testing once mmproj pulls, comfyui install in flight for the diffusion lane. honestly curious what the actual limit is on this box, i have not hit it yet.





🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power! Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇 What's new: 🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks 💡 Strong reasoning across text & multimodal tasks 🔄 Supports thinking & non-thinking modes ✅ Apache 2.0 — fully open, fully yours Smaller model. Bigger results. Community's favorite. ❤️ We can't wait to see what you build with Qwen3.6-27B! 👀 🔗👇 Blog: qwen.ai/blog?id=qwen3.… Qwen Studio: chat.qwen.ai/?models=qwen3.… Github: github.com/QwenLM/Qwen3.6 Hugging Face: huggingface.co/Qwen/Qwen3.6-2… huggingface.co/Qwen/Qwen3.6-2… ModelScope: modelscope.cn/models/Qwen/Qw… modelscope.cn/models/Qwen/Qw…

how to set up hermes agent step by step. built-in memory, 40+ tools, works on your phone, and what to think of hermes vs openclaw: 1. hermes is a personal AI agent that runs in your terminal. think of it like open claw but with built-in memory, 40+ tools out of the box, and 90% cheaper token costs. you install it with one command. 2. the 3 problems with open claw that hermes solves: no memory (you keep repeating yourself), constant gateway restarts, and zero visibility into what you're spending on tokens. 3. hermes remembers everything. every completed task gets saved to memory. it searches through past logs to find solutions. over time it literally gets smarter at your specific workflows. 4. connect it to open router. you see exact costs per model per task. free models rotate weekly. one founder went from $130 every five days on open claw to $10 on hermes. same output. 5. it comes preloaded with skills. apple notes, imessage, find my, browser, web search, image generation, cron jobs. no hunting for plugins. 6. connect it to obsidian so it reads your entire vault. connect it to gstack for your dev environment. create custom skills for your specific workflows. 7. the biggest money saver: have it write code once for recurring tasks. then it runs without burning tokens every time. stop paying an LLM to do the same scrape or report daily. 8. run it on android via telegram. name your agents. talk to them like coworkers. in this episode imran shows you how to set this up. 9. you can run it bare metal, in docker, or serverless on modal. pick your risk level. i begged @imranye to come on @startupideaspod and walk through the full installation live. he made it impossibly clear. if you've heard of Hermes Agent and want the clearest explanation of how to get set up like a pro let me know what you want me to cover on the next ep this is the best personal agent setup video on the internet right now. watch





First time with Openclaw Spending too much on tokens Buy a 3090 + install Hermes




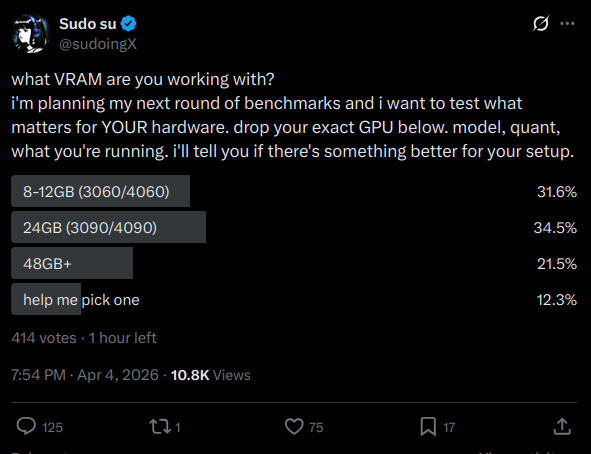
what VRAM are you working with? i'm planning my next round of benchmarks and i want to test what matters for YOUR hardware. drop your exact GPU below. model, quant, what you're running. i'll tell you if there's something better for your setup.


I love Hermes Agent by @NousResearch but wanted to keep my memory data private. so I made a self-hosting setup for @honchodotdev, the memory layer that powers its cross-session learning. By default, Hermes uses @plastic_labs cloud and Neuromancer models for memory, extracting observations, recalling context, consolidating what it knows about you over time. Great service, but your data lives on their servers. This drops the full stack onto your own machine. No fork, just config files on top of upstream Honcho. - Any OpenAI-compatible LLM (OpenRouter, Venice, Together, or local via Ollama) - Primary + backup provider with automatic failover - Optional MCP server for Claude Code / Claude Desktop - One setup script, ~3 minutes github.com/elkimek/honcho…
