
#CVPR Findings posters are at 7am, per the tentative schedule.💀
English
Michael Smith
139 posts
@TheCIMSmith
PhD Student, CIM/APL



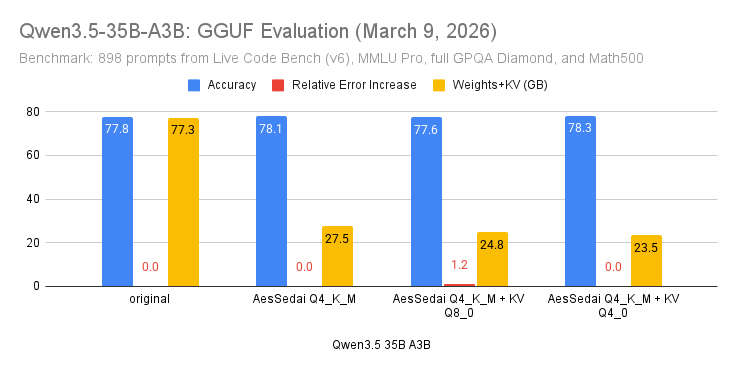
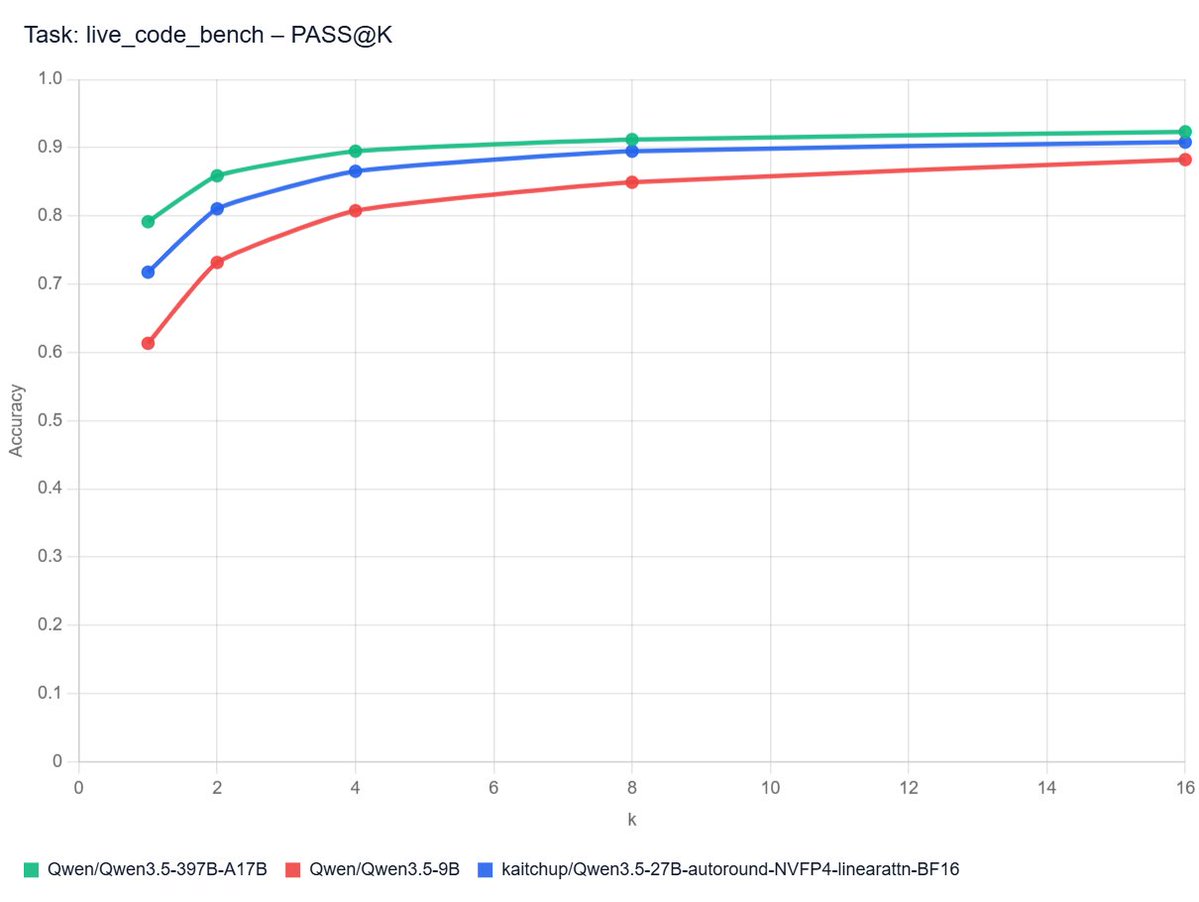














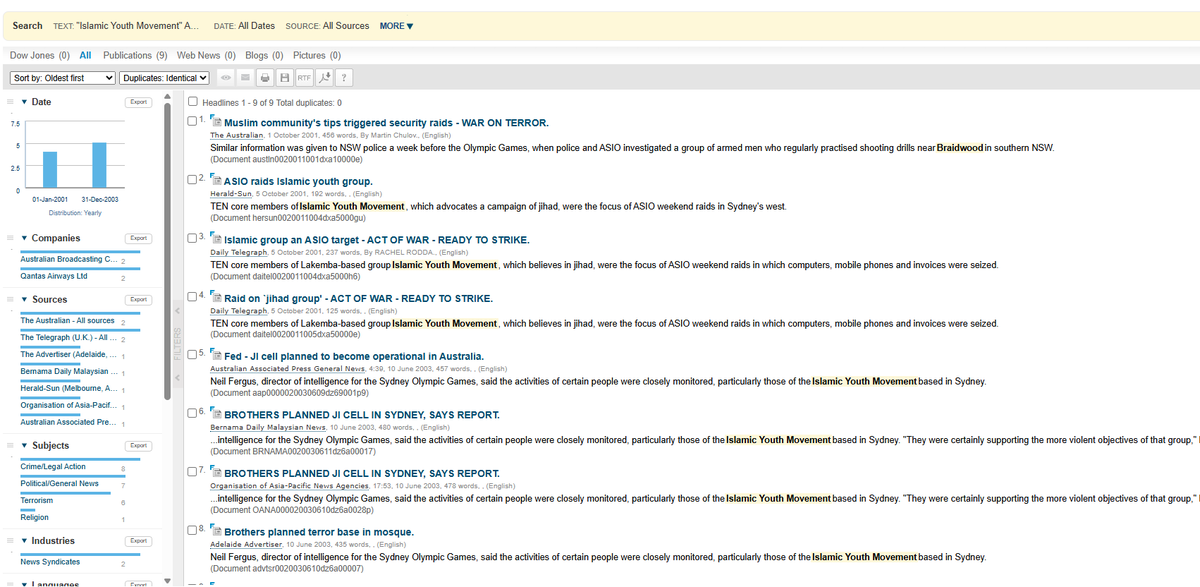

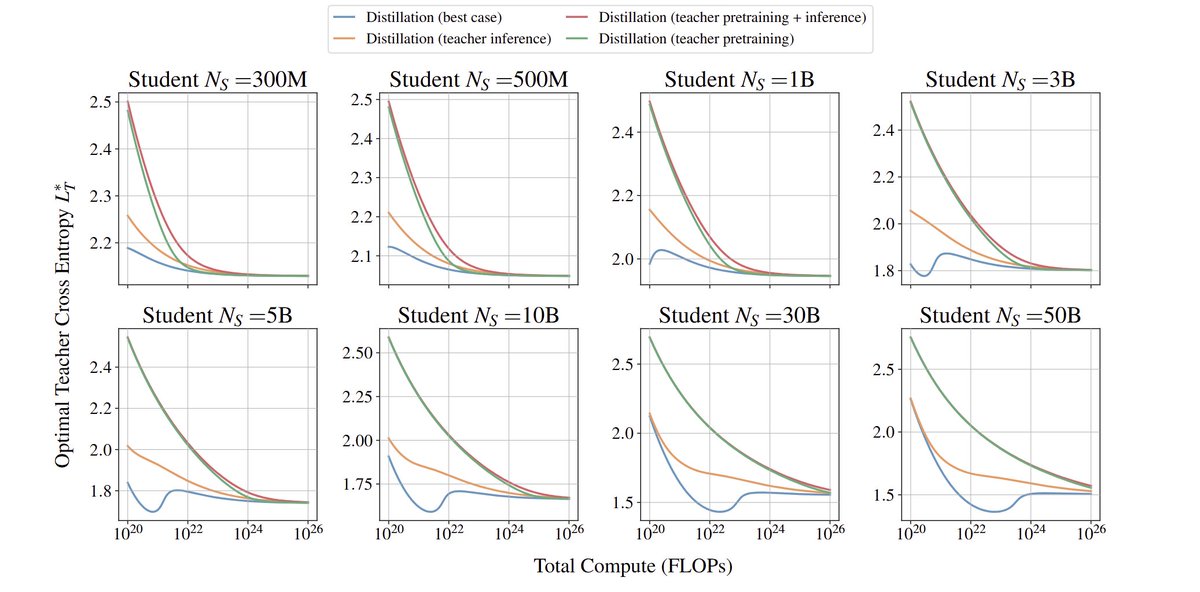
Seedream 3.0 Do I need to re-do my REPA experiments🤔



A more personal and detailed interview with the crew of the Ukrainian Bradley which took on a russian T-90M. Also goes over using American-supplied Bradley IFVs in conditions of the Ukrainian winter 💪
