
Victor Barsoum
128 posts

Victor Barsoum
@VBarsoum
Automation Therapist: I help AI agents overcome fear of sucking @ AI Profit Architects. Co-founder Streetwise Mortgages making underwriting less meh with AI
Toronto Katılım Mart 2013
171 Takip Edilen34 Takipçiler
English


@jarredsumner not sure if there’ll be a second date but at least she knows Claude Code is a general purpose agent and that writing code is the foundation of agentic capability
English

me at nopa on a first date
her: how’d you pick this restaurant?
me: I asked claude
[waitress compliments her pants, clothes come up]
her: where do you shop?
me: lost a bunch of weight, had to rebuy everything. sent claude a pic of me and it picked
[few min later, looking at menu]
her: wait how do you track the calories
me: believe it or not, also claude. I send it a pic of the menu
I’m such a shill
English
2) Creating your own public endpoints from HF is a crazy fun feature and needs to be way more intuitive than it currently is.
3) Once a public endpoint gets created, I lose the ability to edit or delete it. So there's a lot of garbage on the platform — some of it is mine, sorry. That doesn't make sense. I can make a GitHub repo public but I still have full edit rights.
English

Just over week until @Cloudflare next Innovation Week! What should we announce?
English
1. Discoverability — the Explore page is super unintuitive. With new models every day, it would be awesome to be able to see and try the latest models (image generation, image editing, video, OCR). The "I Want To" section on the Explore page comes close, but the models it surfaces are ancient in AI timelines. I hit OpenRouter and fal landing pages once or twice a day just to see what just dropped.
English
@dok2001 @Cloudflare Oh thanks for asking — all quality of life improvements. I think the platform is way underappreciated and doesn't get the public attention it deserves. 🧵
English
@karpathy Would love for your to review this: github.com/vbarsoum1/klore I think I captured the spirit of it
English

Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442a6…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Andrej Karpathy@karpathy
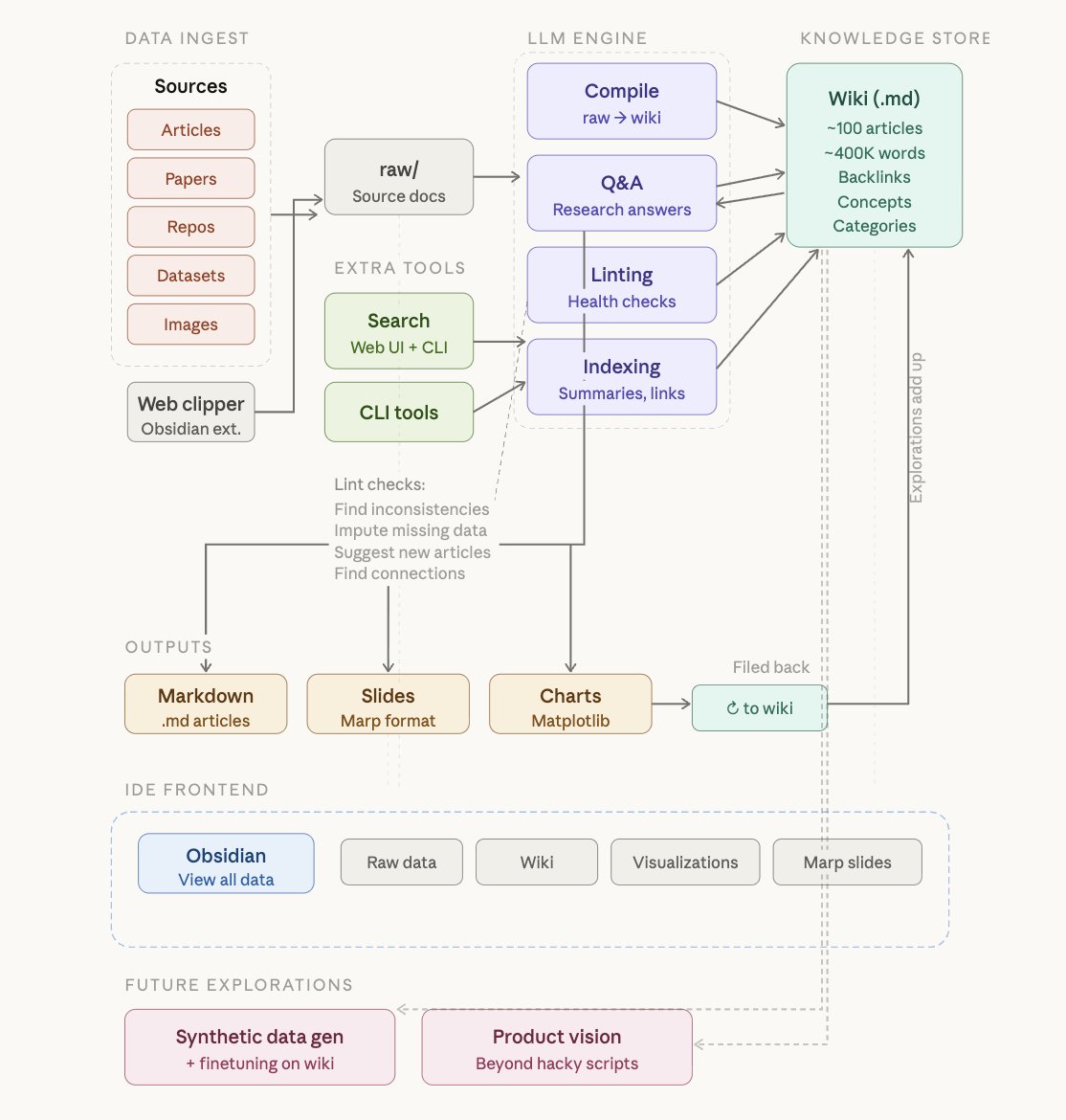
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English

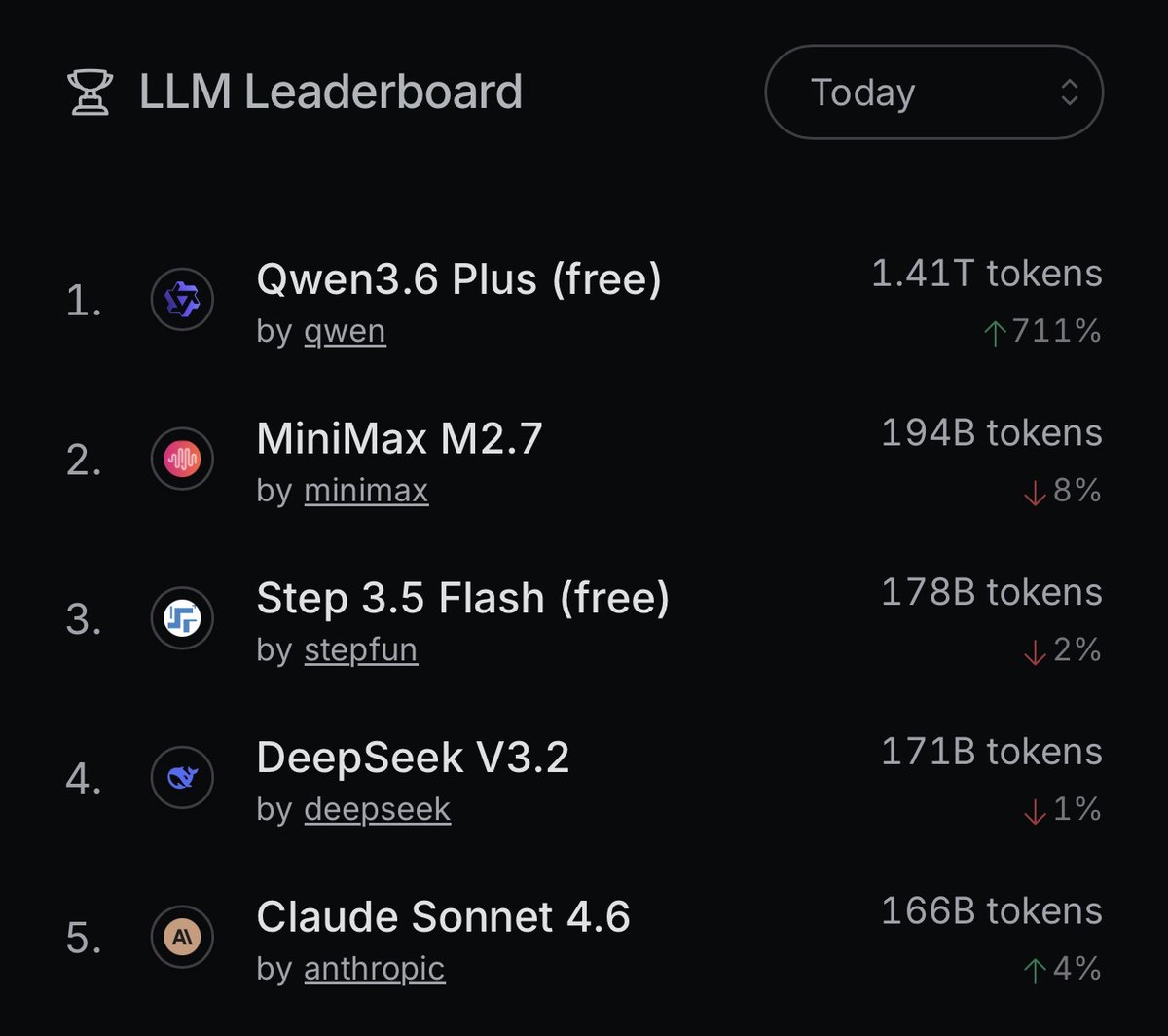
Qwen 3.6 Plus from @Alibaba_Qwen is officially the first model on OpenRouter to break 1 Trillion tokens processed in a single day!
At ~1,400,000,000,000 tokens, it’s the strongest full day performance of any new model dropped this year. Congrats to the Qwen team!
English
@garrytan Haven't logged in to salesforce in 2 weeks, all queries and changes are natural language from the ide.
English
@garrytan MCP done right = API skills. MCP as a concept is dead. API skills, much more token efficient, on demand, and can get very specific when needed
English

@danielfoch hahaha... didn't have enough VRAM on my watch, trying to load it to my shoe next. Will let you know.
English

If you’re not running Gemma 4 locally on a BlackBerry you are NGMI in 2026
English

@karpathy Karpathy vibe coding with humans. Fine, I will bite:
github.com/vbarsoum1/klore here is your model as a cli to automate the process. Thank you @garrytan for gstack's help.
English
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@cline I know it's April fool don't care... ship it .. ship it...
English


Baking an extension into Chromium isn't making your own browser. Just... ship an extension? It's already trivial.
Garry Tan@garrytan
Has anyone cracked this yet with Claude Code? Trivially easy customization to make your own browser with auto-loaded browser extension?
English
Can we stop talking about war, politics, real estate, and even AI for a second? Humanity is heading back to the Moon for the first time in half a century. Godspeed, Artemis II. Remind us what it means to dream bigger than ourselves.

English
If someone was to accidentally release Claude desktop source code I promise to accidentally release a Linux version for it. Just saying.. @bcherny @claudeai @felixrieseberg
English
@garrytan slowly...slowly.. back up and step away from the edge
English

@codyschneiderxx Love how this is the exact playbook you shared a few days ago. Full transparency, full build in public. 100% dogfooding all the way. Respect 👊
English

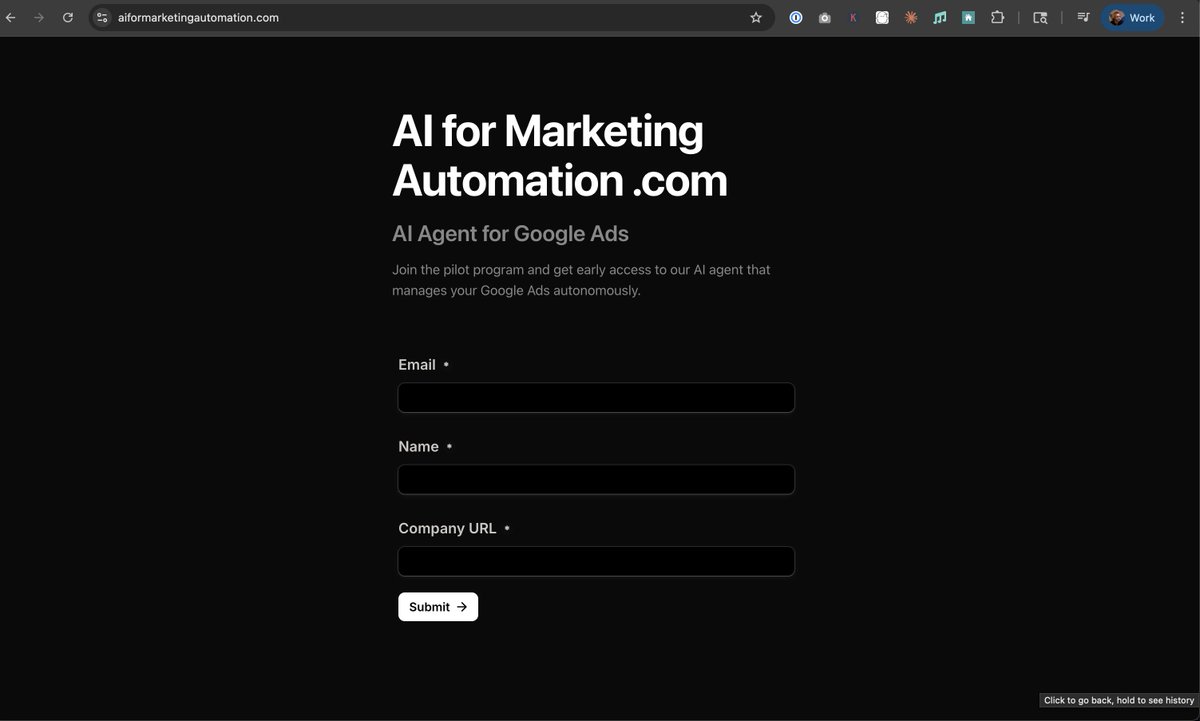
have an AI agent run your google ads aiformarketingautomation .com
English
I just built an AI agent that's completely running my google ads
it's connected to my google ads data, my google analytics data, my posthog data, and my stripe data
it does the keyword research, builds the ads, analyzes the conversion data, analyzes the stripe data, allocates ad spend budget
entirely autonomous
you just plug your company in
and growth starts happening
if you want early access to this lmk below
English