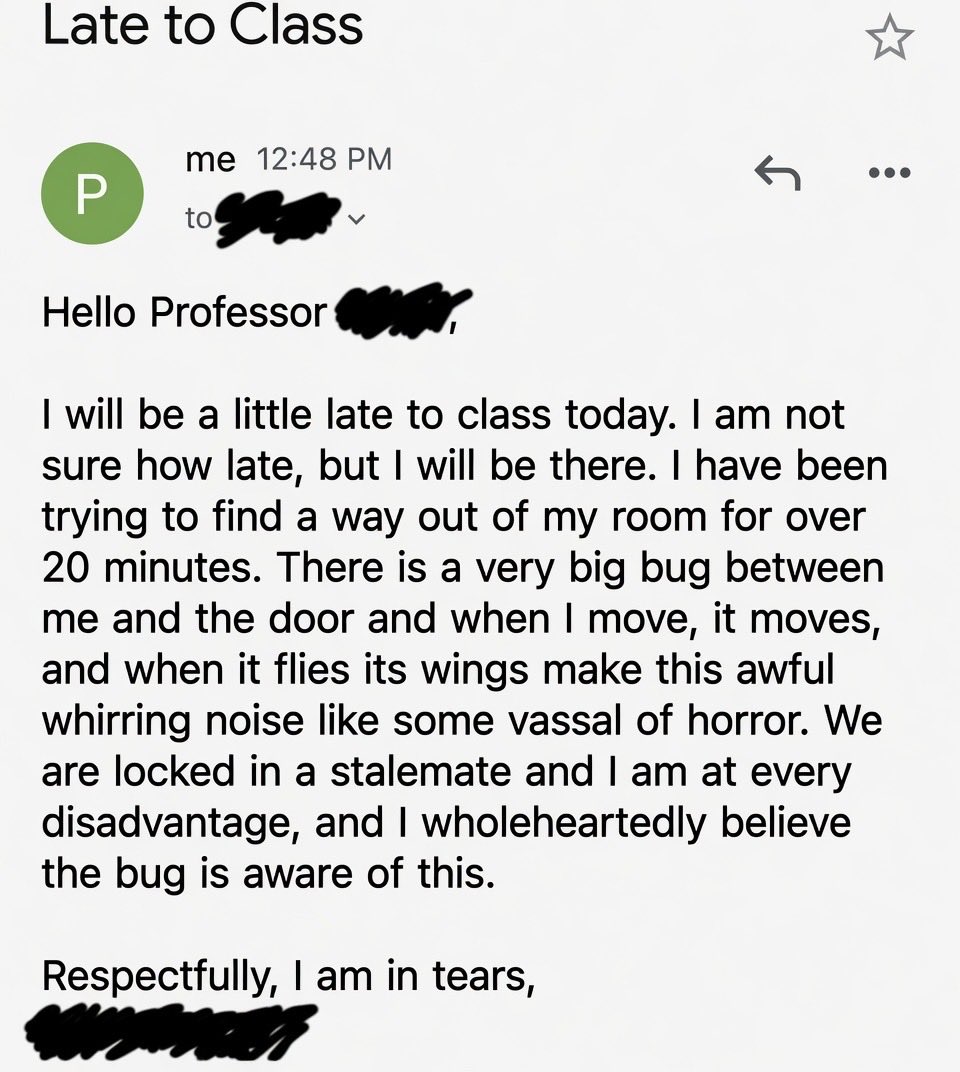
Sabitlenmiş Tweet

Väterchen Frost
34.2K posts

@VaeterchenFrost
Literatur | Sprachakrobatik | © Eigene Fotos (außer RT) | Gedanken, Gedichte, Geschichten, Gedöns™ | German/English ✌🏻🎅🏻✨


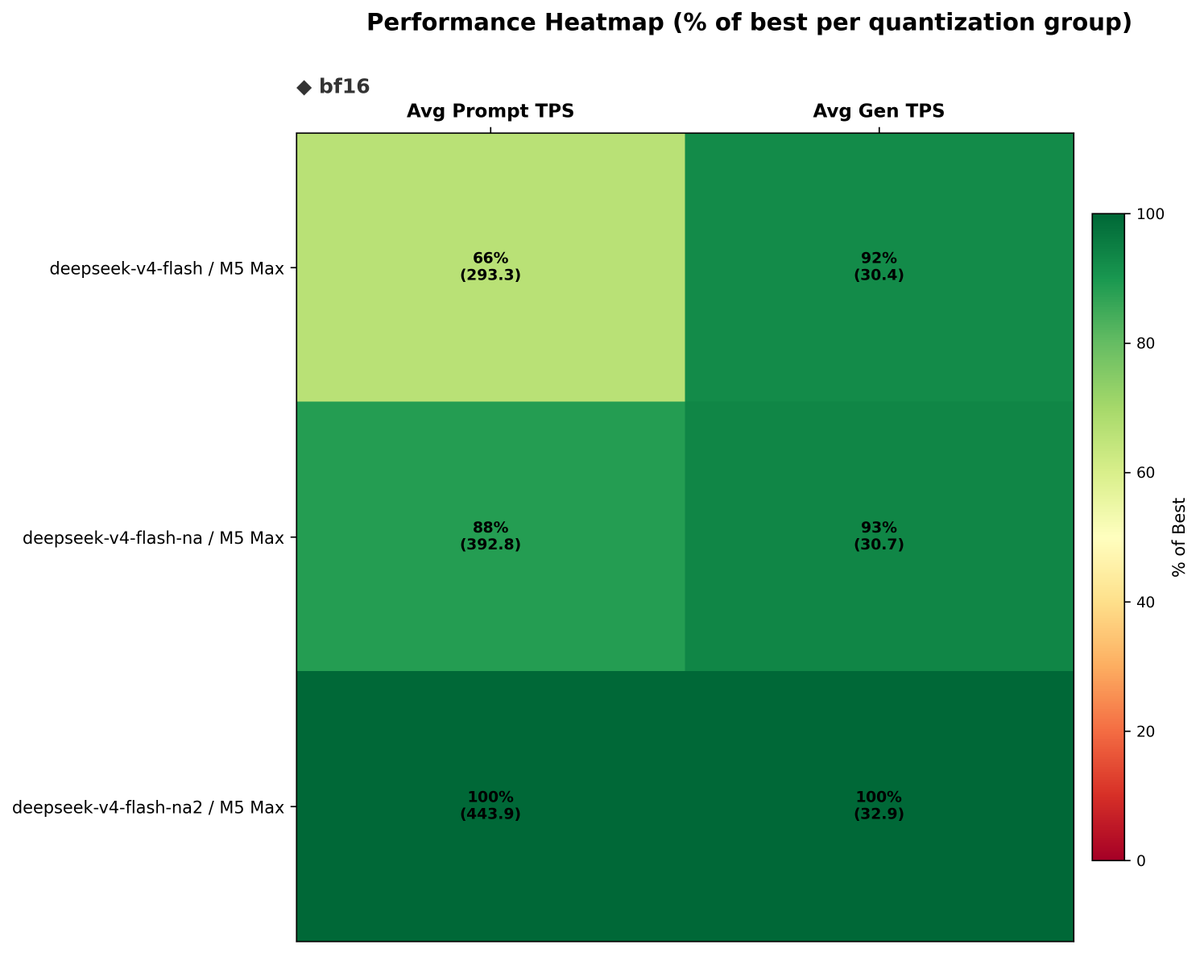
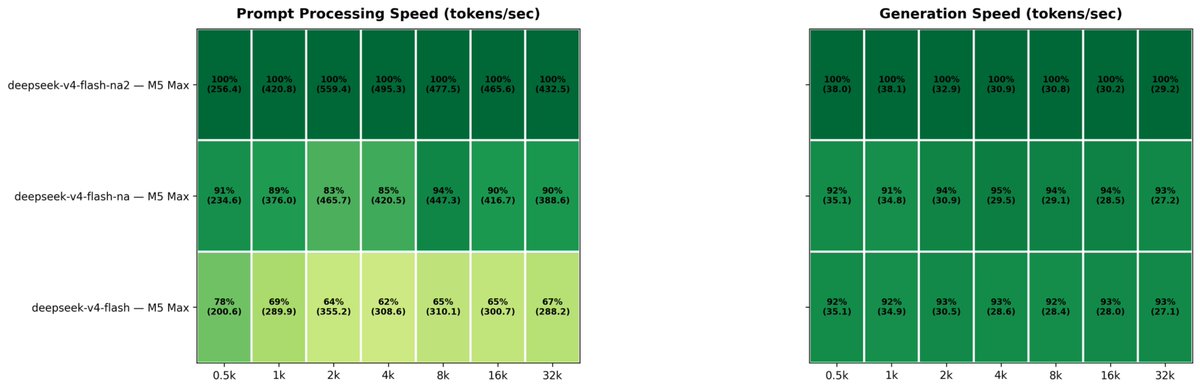

















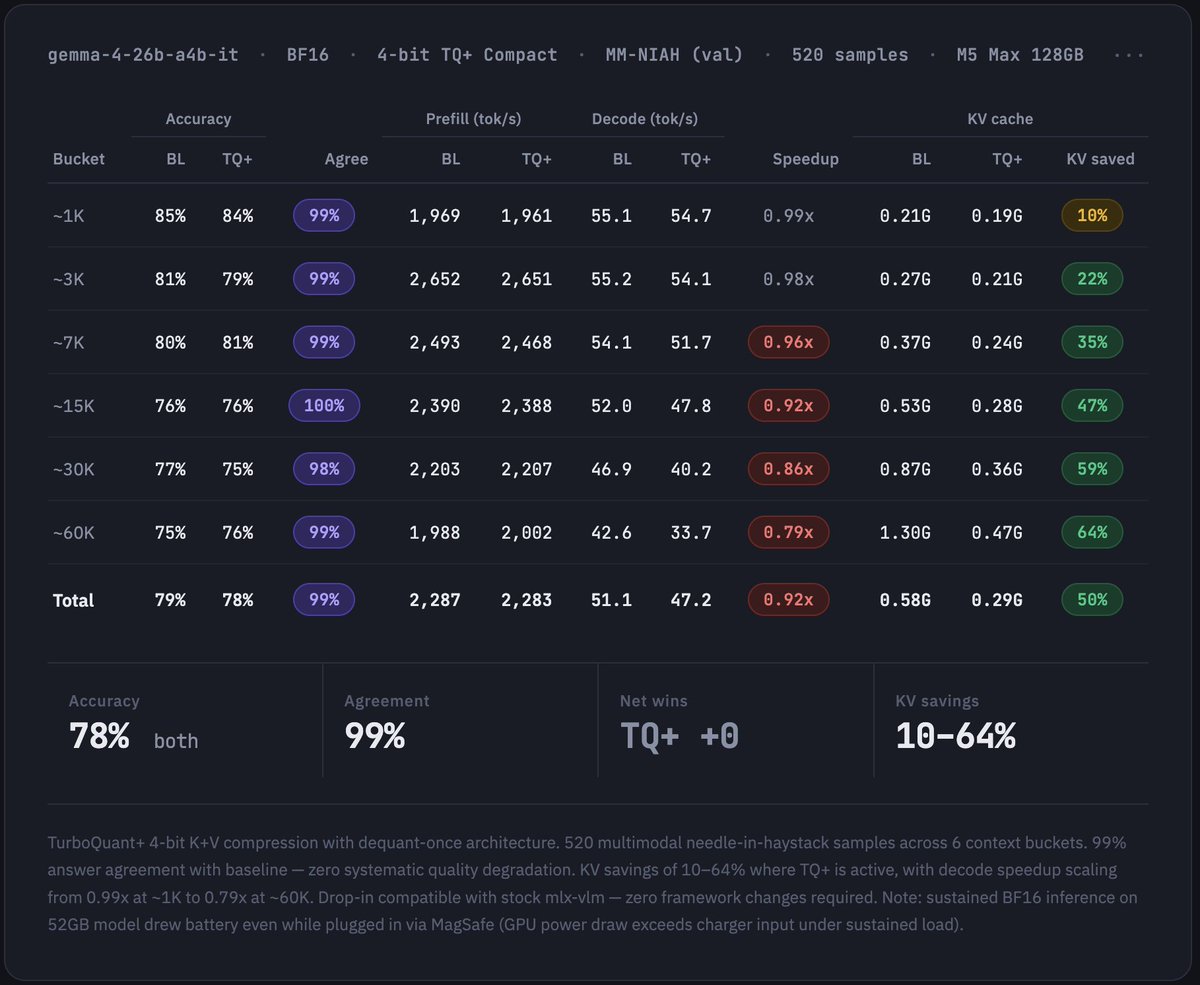
TurboQuant: Open Evals on MLX 🔥 Yesterday I launched mlx-vlm v0.4.4 with major TurboQuant performance improvements. Today, the open benchmark results on MM-NIAH (val, 520 samples) using Gemma 4 26B IT by @GoogleDeepMind on M3 Ultra: → 0 quality loss — 78% accuracy for both BL and TBQ → 97% answer agreement across all context lengths → 30–53% KV cache savings (where TBQ is active) → 1.16x decode speedup at ~60K context Benchmark code 👇🏽
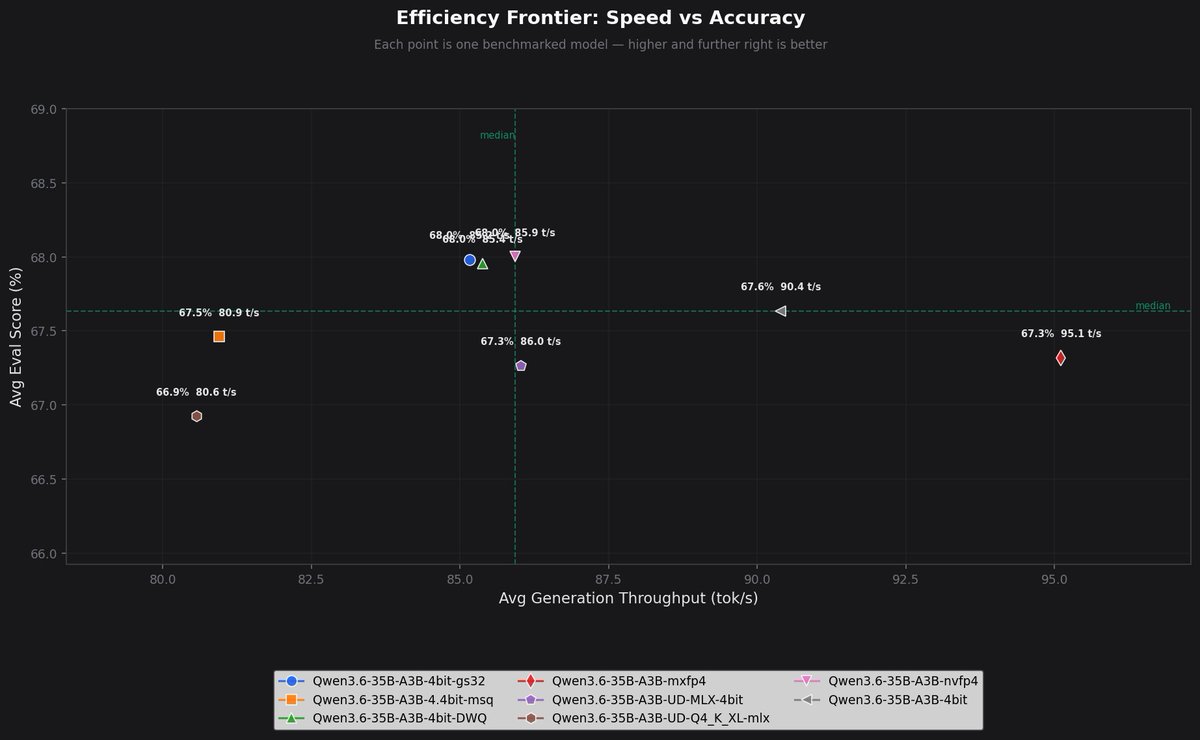
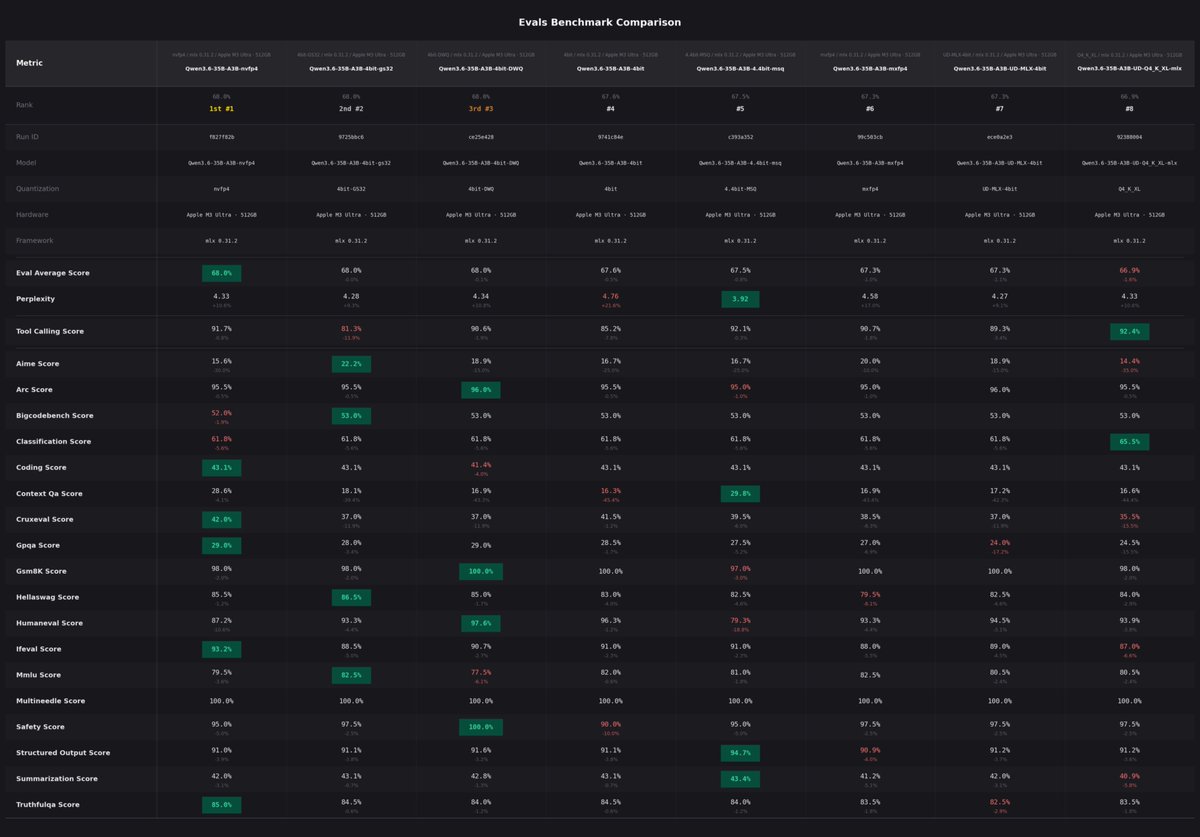
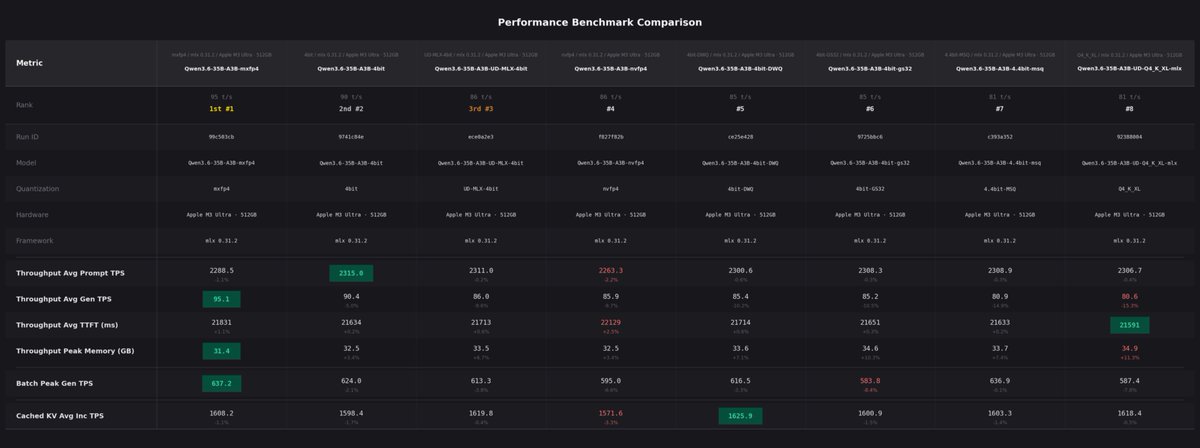
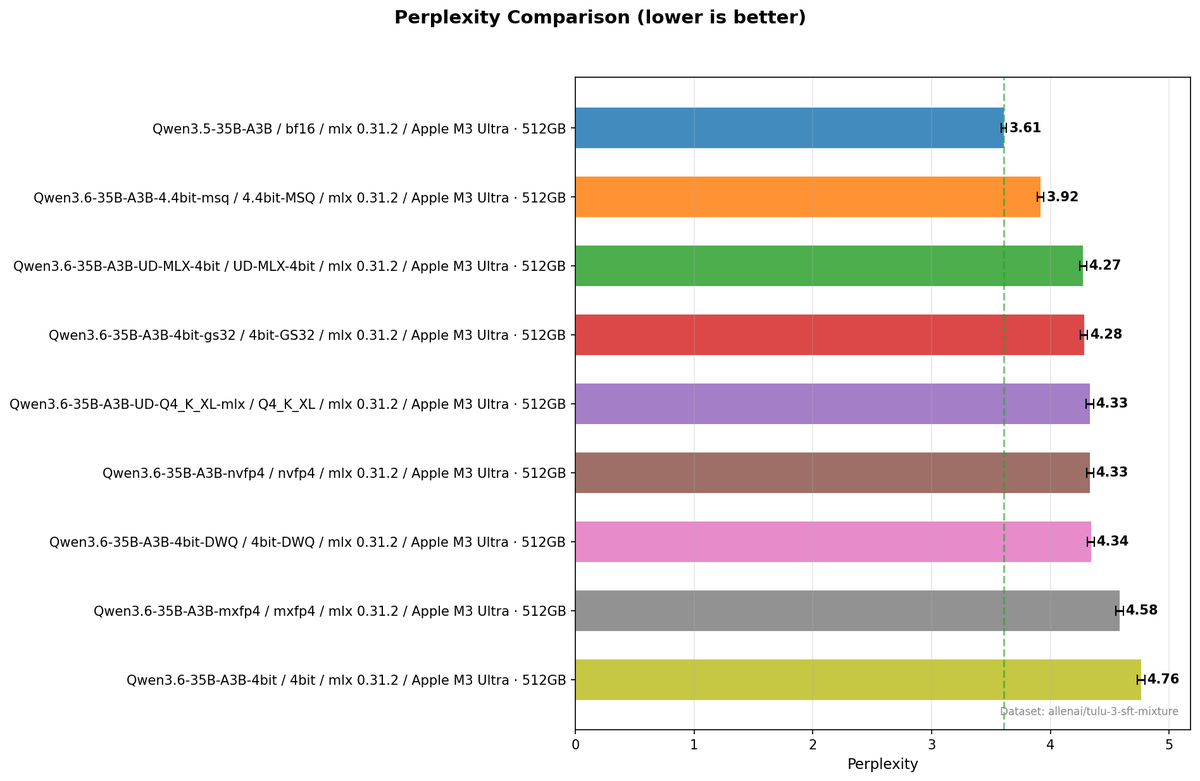
APEX quantizations of more models ongoing! Meanwhile, playing with Qwen 3.5.. the impact of APEX vs Unsloth Dynamic quant on quality is clearly visible IMO, at least in some areas. I know we need more numbers before drawing conclusions, but this isn't about numbers. Just check out a simple prompt: "create an html page of a rotating cube in SVG." Left: Unsloth Qwen3.5-35B-A3B-UD-Q8_K_XL.gguf (48.7 GB, ~32 tok/s) → flat square (?????) Right: APEX Qwen3.5-35B-A3B-APEX-I-Quality.gguf (22.8 GB, ~53 tok/s) → ✨